Merge branch 'debug' of https://github.com/SengokuCola/MaiMBot into debug
This commit is contained in:
8
.gitignore
vendored
8
.gitignore
vendored
@@ -190,7 +190,6 @@ cython_debug/
|
||||
|
||||
# PyPI configuration file
|
||||
.pypirc
|
||||
.env
|
||||
|
||||
# jieba
|
||||
jieba.cache
|
||||
@@ -199,4 +198,9 @@ jieba.cache
|
||||
!.vscode/settings.json
|
||||
|
||||
# direnv
|
||||
/.direnv
|
||||
/.direnv
|
||||
|
||||
# JetBrains
|
||||
.idea
|
||||
*.iml
|
||||
*.ipr
|
||||
|
||||
10
.pre-commit-config.yaml
Normal file
10
.pre-commit-config.yaml
Normal file
@@ -0,0 +1,10 @@
|
||||
repos:
|
||||
- repo: https://github.com/astral-sh/ruff-pre-commit
|
||||
# Ruff version.
|
||||
rev: v0.9.10
|
||||
hooks:
|
||||
# Run the linter.
|
||||
- id: ruff
|
||||
args: [ --fix ]
|
||||
# Run the formatter.
|
||||
- id: ruff-format
|
||||
@@ -62,6 +62,7 @@
|
||||
|
||||
- 📦 **Windows 一键傻瓜式部署**:请运行项目根目录中的 `run.bat`,部署完成后请参照后续配置指南进行配置
|
||||
|
||||
- 📦 Linux 自动部署(实验) :请下载并运行项目根目录中的`run.sh`并按照提示安装,部署完成后请参照后续配置指南进行配置
|
||||
|
||||
- [📦 Windows 手动部署指南 ](docs/manual_deploy_windows.md)
|
||||
|
||||
|
||||
@@ -121,6 +121,7 @@ sudo nano /etc/systemd/system/maimbot.service
|
||||
输入以下内容:
|
||||
|
||||
`<maimbot_directory>`:你的maimbot目录
|
||||
|
||||
`<venv_directory>`:你的venv环境(就是上文创建环境后,执行的代码`source maimbot/bin/activate`中source后面的路径的绝对路径)
|
||||
|
||||
```ini
|
||||
|
||||
BIN
docs/synology_.env.prod.png
Normal file
BIN
docs/synology_.env.prod.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 107 KiB |
BIN
docs/synology_create_project.png
Normal file
BIN
docs/synology_create_project.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 208 KiB |
67
docs/synology_deploy.md
Normal file
67
docs/synology_deploy.md
Normal file
@@ -0,0 +1,67 @@
|
||||
# 群晖 NAS 部署指南
|
||||
|
||||
**笔者使用的是 DSM 7.2.2,其他 DSM 版本的操作可能不完全一样**
|
||||
**需要使用 Container Manager,群晖的部分部分入门级 NAS 可能不支持**
|
||||
|
||||
## 部署步骤
|
||||
|
||||
### 创建配置文件目录
|
||||
|
||||
打开 `DSM ➡️ 控制面板 ➡️ 共享文件夹`,点击 `新增` ,创建一个共享文件夹
|
||||
只需要设置名称,其他设置均保持默认即可。如果你已经有 docker 专用的共享文件夹了,就跳过这一步
|
||||
|
||||
打开 `DSM ➡️ FileStation`, 在共享文件夹中创建一个 `MaiMBot` 文件夹
|
||||
|
||||
### 准备配置文件
|
||||
|
||||
docker-compose.yml: https://github.com/SengokuCola/MaiMBot/blob/main/docker-compose.yml
|
||||
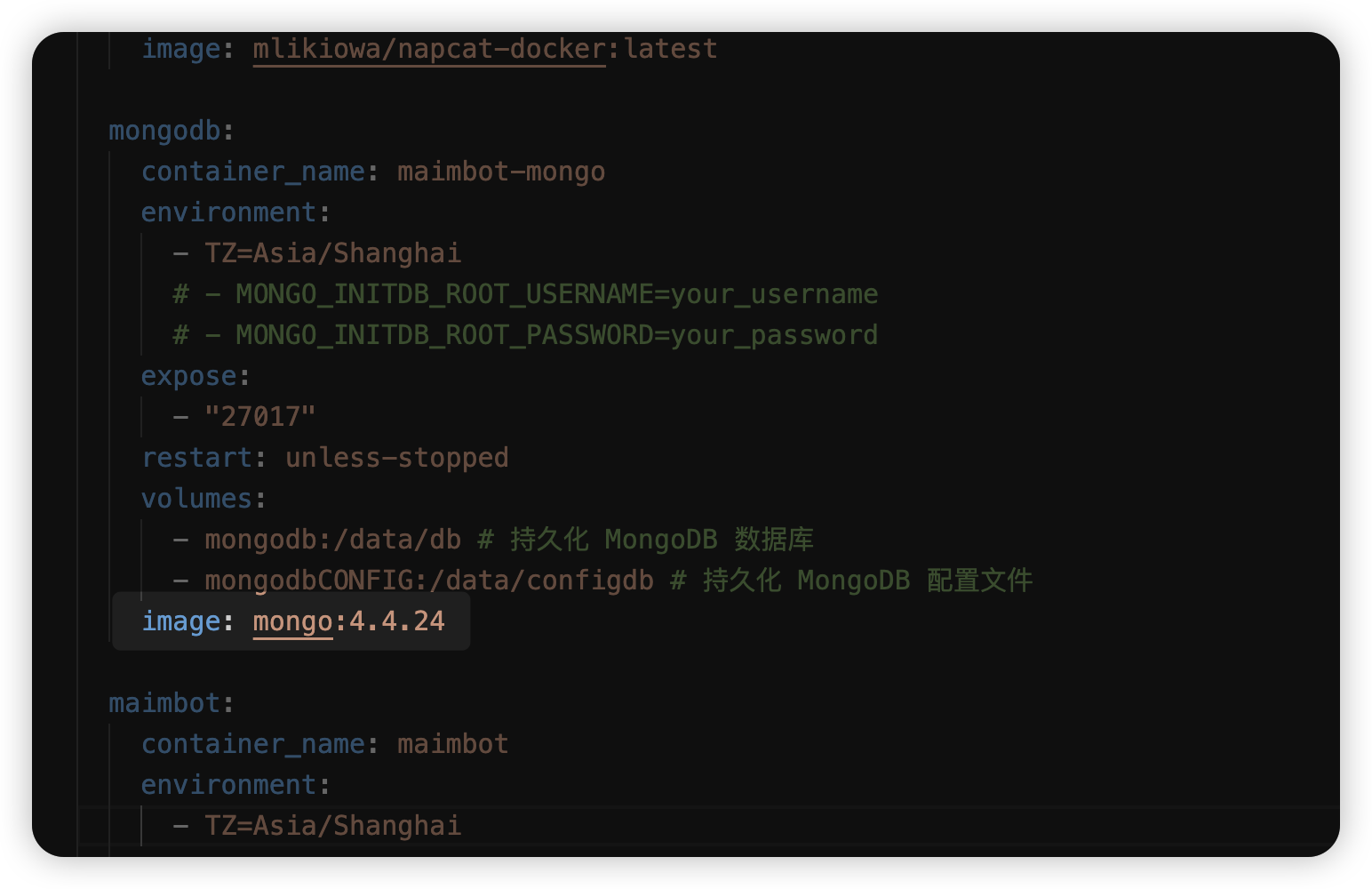
下载后打开,将 `services-mongodb-image` 修改为 `mongo:4.4.24`。这是因为最新的 MongoDB 强制要求 AVX 指令集,而群晖似乎不支持这个指令集
|
||||
|
||||
|
||||
bot_config.toml: https://github.com/SengokuCola/MaiMBot/blob/main/template/bot_config_template.toml
|
||||
下载后,重命名为 `bot_config.toml`
|
||||
打开它,按自己的需求填写配置文件
|
||||
|
||||
.env.prod: https://github.com/SengokuCola/MaiMBot/blob/main/template.env
|
||||
下载后,重命名为 `.env.prod`
|
||||
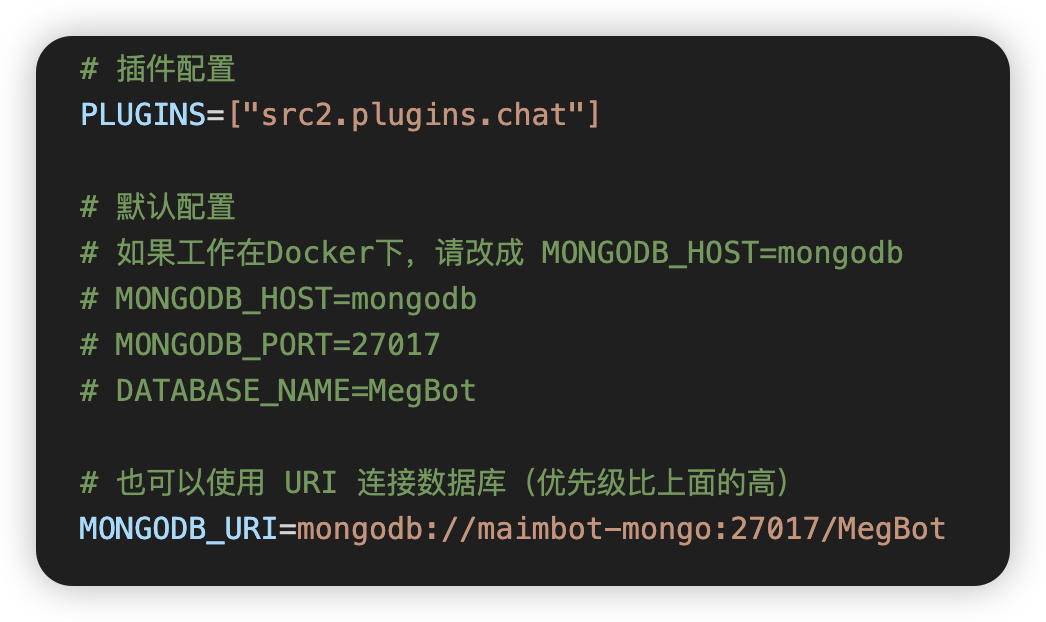
按下图修改 mongodb 设置,使用 `MONGODB_URI`
|
||||
|
||||
|
||||
把 `bot_config.toml` 和 `.env.prod` 放入之前创建的 `MaiMBot`文件夹
|
||||
|
||||
#### 如何下载?
|
||||
|
||||
点这里!
|
||||
|
||||
### 创建项目
|
||||
|
||||
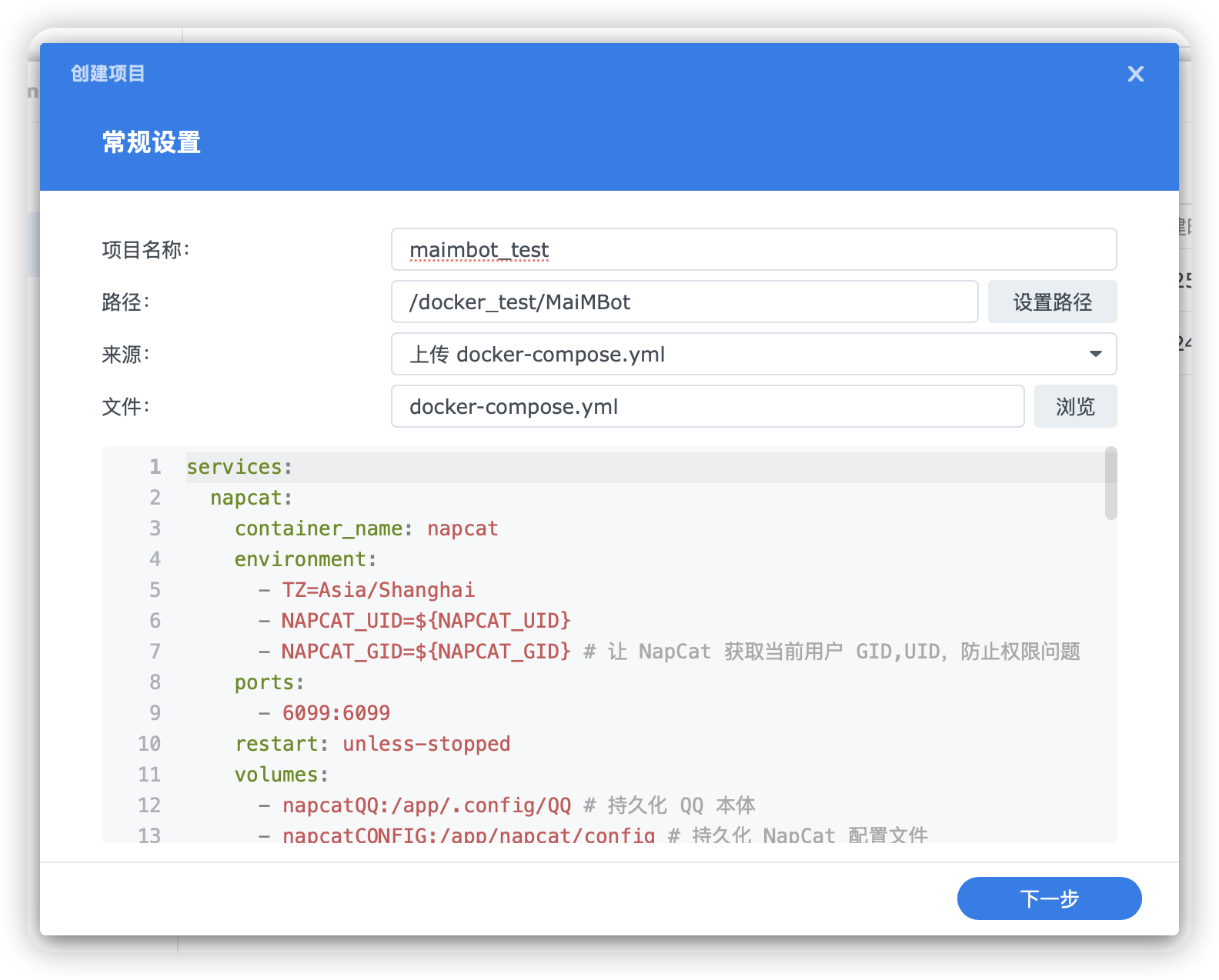
打开 `DSM ➡️ ContainerManager ➡️ 项目`,点击 `新增` 创建项目,填写以下内容:
|
||||
|
||||
- 项目名称: `maimbot`
|
||||
- 路径:之前创建的 `MaiMBot` 文件夹
|
||||
- 来源: `上传 docker-compose.yml`
|
||||
- 文件:之前下载的 `docker-compose.yml` 文件
|
||||
|
||||
图例:
|
||||
|
||||
|
||||
|
||||
一路点下一步,等待项目创建完成
|
||||
|
||||
### 设置 Napcat
|
||||
|
||||
1. 登陆 napcat
|
||||
打开 napcat: `http://<你的nas地址>:6099` ,输入token登陆
|
||||
token可以打开 `DSM ➡️ ContainerManager ➡️ 项目 ➡️ MaiMBot ➡️ 容器 ➡️ Napcat ➡️ 日志`,找到类似 `[WebUi] WebUi Local Panel Url: http://127.0.0.1:6099/webui?token=xxxx` 的日志
|
||||
这个 `token=` 后面的就是你的 napcat token
|
||||
|
||||
2. 按提示,登陆你给麦麦准备的QQ小号
|
||||
|
||||
3. 设置 websocket 客户端
|
||||
`网络配置 -> 新建 -> Websocket客户端`,名称自定,URL栏填入 `ws://maimbot:8080/onebot/v11/ws`,启用并保存即可。
|
||||
若修改过容器名称,则替换 `maimbot` 为你自定的名称
|
||||
|
||||
### 部署完成
|
||||
|
||||
找个群,发送 `麦麦,你在吗` 之类的
|
||||
如果一切正常,应该能正常回复了
|
||||
BIN
docs/synology_docker-compose.png
Normal file
BIN
docs/synology_docker-compose.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 170 KiB |
BIN
docs/synology_how_to_download.png
Normal file
BIN
docs/synology_how_to_download.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 133 KiB |
278
run.sh
Normal file
278
run.sh
Normal file
@@ -0,0 +1,278 @@
|
||||
#!/bin/bash
|
||||
|
||||
# Maimbot 一键安装脚本 by Cookie987
|
||||
# 适用于Debian系
|
||||
# 请小心使用任何一键脚本!
|
||||
|
||||
# 如无法访问GitHub请修改此处镜像地址
|
||||
|
||||
LANG=C.UTF-8
|
||||
|
||||
GITHUB_REPO="https://ghfast.top/https://github.com/SengokuCola/MaiMBot.git"
|
||||
|
||||
# 颜色输出
|
||||
GREEN="\e[32m"
|
||||
RED="\e[31m"
|
||||
RESET="\e[0m"
|
||||
|
||||
# 需要的基本软件包
|
||||
REQUIRED_PACKAGES=("git" "sudo" "python3" "python3-venv" "curl" "gnupg" "python3-pip")
|
||||
|
||||
# 默认项目目录
|
||||
DEFAULT_INSTALL_DIR="/opt/maimbot"
|
||||
|
||||
# 服务名称
|
||||
SERVICE_NAME="maimbot"
|
||||
|
||||
IS_INSTALL_MONGODB=false
|
||||
IS_INSTALL_NAPCAT=false
|
||||
|
||||
# 1/6: 检测是否安装 whiptail
|
||||
if ! command -v whiptail &>/dev/null; then
|
||||
echo -e "${RED}[1/6] whiptail 未安装,正在安装...${RESET}"
|
||||
apt update && apt install -y whiptail
|
||||
fi
|
||||
|
||||
get_os_info() {
|
||||
if command -v lsb_release &>/dev/null; then
|
||||
OS_INFO=$(lsb_release -d | cut -f2)
|
||||
elif [[ -f /etc/os-release ]]; then
|
||||
OS_INFO=$(grep "^PRETTY_NAME=" /etc/os-release | cut -d '"' -f2)
|
||||
else
|
||||
OS_INFO="Unknown OS"
|
||||
fi
|
||||
echo "$OS_INFO"
|
||||
}
|
||||
|
||||
# 检查系统
|
||||
check_system() {
|
||||
# 检查是否为 root 用户
|
||||
if [[ "$(id -u)" -ne 0 ]]; then
|
||||
whiptail --title "🚫 权限不足" --msgbox "请使用 root 用户运行此脚本!\n执行方式: sudo bash $0" 10 60
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [[ -f /etc/os-release ]]; then
|
||||
source /etc/os-release
|
||||
if [[ "$ID" != "debian" || "$VERSION_ID" != "12" ]]; then
|
||||
whiptail --title "🚫 不支持的系统" --msgbox "此脚本仅支持 Debian 12 (Bookworm)!\n当前系统: $PRETTY_NAME\n安装已终止。" 10 60
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
whiptail --title "⚠️ 无法检测系统" --msgbox "无法识别系统版本,安装已终止。" 10 60
|
||||
exit 1
|
||||
fi
|
||||
}
|
||||
|
||||
# 3/6: 询问用户是否安装缺失的软件包
|
||||
install_packages() {
|
||||
missing_packages=()
|
||||
for package in "${REQUIRED_PACKAGES[@]}"; do
|
||||
if ! dpkg -s "$package" &>/dev/null; then
|
||||
missing_packages+=("$package")
|
||||
fi
|
||||
done
|
||||
|
||||
if [[ ${#missing_packages[@]} -gt 0 ]]; then
|
||||
whiptail --title "📦 [3/6] 软件包检查" --yesno "检测到以下必须的依赖项目缺失:\n${missing_packages[*]}\n\n是否要自动安装?" 12 60
|
||||
if [[ $? -eq 0 ]]; then
|
||||
return 0
|
||||
else
|
||||
whiptail --title "⚠️ 注意" --yesno "某些必要的依赖项未安装,可能会影响运行!\n是否继续?" 10 60 || exit 1
|
||||
fi
|
||||
fi
|
||||
}
|
||||
|
||||
# 4/6: Python 版本检查
|
||||
check_python() {
|
||||
PYTHON_VERSION=$(python3 -c 'import sys; print(f"{sys.version_info.major}.{sys.version_info.minor}")')
|
||||
|
||||
python3 -c "import sys; exit(0) if sys.version_info >= (3,9) else exit(1)"
|
||||
if [[ $? -ne 0 ]]; then
|
||||
whiptail --title "⚠️ [4/6] Python 版本过低" --msgbox "检测到 Python 版本为 $PYTHON_VERSION,需要 3.9 或以上!\n请升级 Python 后重新运行本脚本。" 10 60
|
||||
exit 1
|
||||
fi
|
||||
}
|
||||
|
||||
# 5/6: 选择分支
|
||||
choose_branch() {
|
||||
BRANCH=$(whiptail --title "🔀 [5/6] 选择 Maimbot 分支" --menu "请选择要安装的 Maimbot 分支:" 15 60 2 \
|
||||
"main" "稳定版本(推荐)" \
|
||||
"debug" "开发版本(可能不稳定)" 3>&1 1>&2 2>&3)
|
||||
|
||||
if [[ -z "$BRANCH" ]]; then
|
||||
BRANCH="main"
|
||||
whiptail --title "🔀 默认选择" --msgbox "未选择分支,默认安装稳定版本(main)" 10 60
|
||||
fi
|
||||
}
|
||||
|
||||
# 6/6: 选择安装路径
|
||||
choose_install_dir() {
|
||||
INSTALL_DIR=$(whiptail --title "📂 [6/6] 选择安装路径" --inputbox "请输入 Maimbot 的安装目录:" 10 60 "$DEFAULT_INSTALL_DIR" 3>&1 1>&2 2>&3)
|
||||
|
||||
if [[ -z "$INSTALL_DIR" ]]; then
|
||||
whiptail --title "⚠️ 取消输入" --yesno "未输入安装路径,是否退出安装?" 10 60
|
||||
if [[ $? -ne 0 ]]; then
|
||||
INSTALL_DIR="$DEFAULT_INSTALL_DIR"
|
||||
else
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
}
|
||||
|
||||
# 显示确认界面
|
||||
confirm_install() {
|
||||
local confirm_message="请确认以下更改:\n\n"
|
||||
|
||||
if [[ ${#missing_packages[@]} -gt 0 ]]; then
|
||||
confirm_message+="📦 安装缺失的依赖项: ${missing_packages[*]}\n"
|
||||
else
|
||||
confirm_message+="✅ 所有依赖项已安装\n"
|
||||
fi
|
||||
|
||||
confirm_message+="📂 安装麦麦Bot到: $INSTALL_DIR\n"
|
||||
confirm_message+="🔀 分支: $BRANCH\n"
|
||||
|
||||
if [[ "$MONGODB_INSTALLED" == "true" ]]; then
|
||||
confirm_message+="✅ MongoDB 已安装\n"
|
||||
else
|
||||
if [[ "$IS_INSTALL_MONGODB" == "true" ]]; then
|
||||
confirm_message+="📦 安装 MongoDB\n"
|
||||
fi
|
||||
fi
|
||||
|
||||
if [[ "$NAPCAT_INSTALLED" == "true" ]]; then
|
||||
confirm_message+="✅ NapCat 已安装\n"
|
||||
else
|
||||
if [[ "$IS_INSTALL_NAPCAT" == "true" ]]; then
|
||||
confirm_message+="📦 安装 NapCat\n"
|
||||
fi
|
||||
fi
|
||||
|
||||
confirm_message+="🛠️ 添加麦麦Bot作为系统服务 ($SERVICE_NAME.service)\n"
|
||||
|
||||
confitm_message+="\n\n注意:本脚本默认使用ghfast.top为GitHub进行加速,如不想使用请手动修改脚本开头的GITHUB_REPO变量。"
|
||||
whiptail --title "🔧 安装确认" --yesno "$confirm_message\n\n是否继续安装?" 15 60
|
||||
if [[ $? -ne 0 ]]; then
|
||||
whiptail --title "🚫 取消安装" --msgbox "安装已取消。" 10 60
|
||||
exit 1
|
||||
fi
|
||||
}
|
||||
|
||||
check_mongodb() {
|
||||
if command -v mongod &>/dev/null; then
|
||||
MONGO_INSTALLED=true
|
||||
else
|
||||
MONGO_INSTALLED=false
|
||||
fi
|
||||
}
|
||||
|
||||
# 安装 MongoDB
|
||||
install_mongodb() {
|
||||
if [[ "$MONGO_INSTALLED" == "true" ]]; then
|
||||
return 0
|
||||
fi
|
||||
|
||||
whiptail --title "📦 [3/6] 软件包检查" --yesno "检测到未安装MongoDB,是否安装?\n如果您想使用远程数据库,请跳过此步。" 10 60
|
||||
if [[ $? -ne 0 ]]; then
|
||||
return 1
|
||||
fi
|
||||
IS_INSTALL_MONGODB=true
|
||||
}
|
||||
|
||||
check_napcat() {
|
||||
if command -v napcat &>/dev/null; then
|
||||
NAPCAT_INSTALLED=true
|
||||
else
|
||||
NAPCAT_INSTALLED=false
|
||||
fi
|
||||
}
|
||||
|
||||
install_napcat() {
|
||||
if [[ "$NAPCAT_INSTALLED" == "true" ]]; then
|
||||
return 0
|
||||
fi
|
||||
|
||||
whiptail --title "📦 [3/6] 软件包检查" --yesno "检测到未安装NapCat,是否安装?\n如果您想使用远程NapCat,请跳过此步。" 10 60
|
||||
if [[ $? -ne 0 ]]; then
|
||||
return 1
|
||||
fi
|
||||
IS_INSTALL_NAPCAT=true
|
||||
}
|
||||
|
||||
# 运行安装步骤
|
||||
check_system
|
||||
check_mongodb
|
||||
check_napcat
|
||||
install_packages
|
||||
install_mongodb
|
||||
install_napcat
|
||||
check_python
|
||||
choose_branch
|
||||
choose_install_dir
|
||||
confirm_install
|
||||
|
||||
# 开始安装
|
||||
whiptail --title "🚀 开始安装" --msgbox "所有环境检查完毕,即将开始安装麦麦Bot!" 10 60
|
||||
|
||||
echo -e "${GREEN}安装依赖项...${RESET}"
|
||||
|
||||
apt update && apt install -y "${missing_packages[@]}"
|
||||
|
||||
|
||||
if [[ "$IS_INSTALL_MONGODB" == "true" ]]; then
|
||||
echo -e "${GREEN}安装 MongoDB...${RESET}"
|
||||
curl -fsSL https://www.mongodb.org/static/pgp/server-8.0.asc | gpg -o /usr/share/keyrings/mongodb-server-8.0.gpg --dearmor
|
||||
echo "deb [ signed-by=/usr/share/keyrings/mongodb-server-8.0.gpg ] http://repo.mongodb.org/apt/debian bookworm/mongodb-org/8.0 main" | sudo tee /etc/apt/sources.list.d/mongodb-org-8.0.list
|
||||
apt-get update
|
||||
apt-get install -y mongodb-org
|
||||
|
||||
systemctl enable mongod
|
||||
systemctl start mongod
|
||||
fi
|
||||
|
||||
if [[ "$IS_INSTALL_NAPCAT" == "true" ]]; then
|
||||
echo -e "${GREEN}安装 NapCat...${RESET}"
|
||||
curl -o napcat.sh https://nclatest.znin.net/NapNeko/NapCat-Installer/main/script/install.sh && bash napcat.sh
|
||||
fi
|
||||
|
||||
echo -e "${GREEN}创建 Python 虚拟环境...${RESET}"
|
||||
mkdir -p "$INSTALL_DIR"
|
||||
cd "$INSTALL_DIR" || exit
|
||||
python3 -m venv venv
|
||||
source venv/bin/activate
|
||||
|
||||
echo -e "${GREEN}克隆仓库...${RESET}"
|
||||
# 安装 Maimbot
|
||||
mkdir -p "$INSTALL_DIR/repo"
|
||||
cd "$INSTALL_DIR/repo" || exit 1
|
||||
git clone -b "$BRANCH" $GITHUB_REPO .
|
||||
|
||||
echo -e "${GREEN}安装 Python 依赖...${RESET}"
|
||||
pip install -r requirements.txt
|
||||
|
||||
echo -e "${GREEN}设置服务...${RESET}"
|
||||
|
||||
# 设置 Maimbot 服务
|
||||
cat <<EOF | tee /etc/systemd/system/$SERVICE_NAME.service
|
||||
[Unit]
|
||||
Description=MaiMbot 麦麦
|
||||
After=network.target mongod.service
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
WorkingDirectory=$INSTALL_DIR/repo/
|
||||
ExecStart=$INSTALL_DIR/venv/bin/python3 bot.py
|
||||
ExecStop=/bin/kill -2 $MAINPID
|
||||
Restart=always
|
||||
RestartSec=10s
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
EOF
|
||||
|
||||
systemctl daemon-reload
|
||||
systemctl enable maimbot
|
||||
systemctl start maimbot
|
||||
|
||||
whiptail --title "🎉 安装完成" --msgbox "麦麦Bot安装完成!\n已经启动麦麦Bot服务。\n\n安装路径: $INSTALL_DIR\n分支: $BRANCH" 12 60
|
||||
@@ -7,7 +7,7 @@ from datetime import datetime
|
||||
from typing import Dict, List
|
||||
from loguru import logger
|
||||
from typing import Optional
|
||||
from ..common.database import db
|
||||
|
||||
|
||||
import customtkinter as ctk
|
||||
from dotenv import load_dotenv
|
||||
@@ -16,6 +16,8 @@ from dotenv import load_dotenv
|
||||
current_dir = os.path.dirname(os.path.abspath(__file__))
|
||||
# 获取项目根目录
|
||||
root_dir = os.path.abspath(os.path.join(current_dir, '..', '..'))
|
||||
sys.path.insert(0, root_dir)
|
||||
from src.common.database import db
|
||||
|
||||
# 加载环境变量
|
||||
if os.path.exists(os.path.join(root_dir, '.env.dev')):
|
||||
|
||||
@@ -139,3 +139,12 @@ async def print_mood_task():
|
||||
"""每30秒打印一次情绪状态"""
|
||||
mood_manager = MoodManager.get_instance()
|
||||
mood_manager.print_mood_status()
|
||||
|
||||
|
||||
@scheduler.scheduled_job("interval", seconds=7200, id="generate_schedule")
|
||||
async def generate_schedule_task():
|
||||
"""每2小时尝试生成一次日程"""
|
||||
logger.debug("尝试生成日程")
|
||||
await bot_schedule.initialize()
|
||||
if not bot_schedule.enable_output:
|
||||
bot_schedule.print_schedule()
|
||||
|
||||
@@ -231,6 +231,7 @@ class ChatBot:
|
||||
config=global_config,
|
||||
is_emoji=message.is_emoji,
|
||||
interested_rate=interested_rate,
|
||||
sender_id=str(message.message_info.user_info.user_id),
|
||||
)
|
||||
current_willing = willing_manager.get_willing(chat_stream=chat)
|
||||
|
||||
@@ -261,6 +262,9 @@ class ChatBot:
|
||||
willing_manager.change_reply_willing_sent(chat)
|
||||
|
||||
response, raw_content = await self.gpt.generate_response(message)
|
||||
else:
|
||||
# 决定不回复时,也更新回复意愿
|
||||
willing_manager.change_reply_willing_not_sent(chat)
|
||||
|
||||
# print(f"response: {response}")
|
||||
if response:
|
||||
|
||||
@@ -86,9 +86,12 @@ class CQCode:
|
||||
else:
|
||||
self.translated_segments = Seg(type="text", data="[图片]")
|
||||
elif self.type == "at":
|
||||
user_nickname = get_user_nickname(self.params.get("qq", ""))
|
||||
self.translated_segments = Seg(
|
||||
type="text", data=f"[@{user_nickname or '某人'}]"
|
||||
if self.params.get("qq") == "all":
|
||||
self.translated_segments = Seg(type="text", data="@[全体成员]")
|
||||
else:
|
||||
user_nickname = get_user_nickname(self.params.get("qq", ""))
|
||||
self.translated_segments = Seg(
|
||||
type="text", data=f"[@{user_nickname or '某人'}]"
|
||||
)
|
||||
elif self.type == "reply":
|
||||
reply_segments = self.translate_reply()
|
||||
|
||||
@@ -31,7 +31,7 @@ image_manager = ImageManager()
|
||||
|
||||
class EmojiManager:
|
||||
_instance = None
|
||||
EMOJI_DIR = "data/emoji" # 表情包存储目录
|
||||
EMOJI_DIR = os.path.join("data", "emoji") # 表情包存储目录
|
||||
|
||||
def __new__(cls):
|
||||
if cls._instance is None:
|
||||
@@ -217,7 +217,7 @@ class EmojiManager:
|
||||
async def scan_new_emojis(self):
|
||||
"""扫描新的表情包"""
|
||||
try:
|
||||
emoji_dir = "data/emoji"
|
||||
emoji_dir = self.EMOJI_DIR
|
||||
os.makedirs(emoji_dir, exist_ok=True)
|
||||
|
||||
# 获取所有支持的图片文件
|
||||
|
||||
@@ -44,18 +44,23 @@ class ImageManager:
|
||||
"""确保images集合存在并创建索引"""
|
||||
if "images" not in db.list_collection_names():
|
||||
db.create_collection("images")
|
||||
# 创建索引
|
||||
db.images.create_index([("hash", 1)], unique=True)
|
||||
db.images.create_index([("url", 1)])
|
||||
db.images.create_index([("path", 1)])
|
||||
|
||||
# 删除旧索引
|
||||
db.images.drop_indexes()
|
||||
# 创建新的复合索引
|
||||
db.images.create_index([("hash", 1), ("type", 1)], unique=True)
|
||||
db.images.create_index([("url", 1)])
|
||||
db.images.create_index([("path", 1)])
|
||||
|
||||
def _ensure_description_collection(self):
|
||||
"""确保image_descriptions集合存在并创建索引"""
|
||||
if "image_descriptions" not in db.list_collection_names():
|
||||
db.create_collection("image_descriptions")
|
||||
# 创建索引
|
||||
db.image_descriptions.create_index([("hash", 1)], unique=True)
|
||||
db.image_descriptions.create_index([("type", 1)])
|
||||
|
||||
# 删除旧索引
|
||||
db.image_descriptions.drop_indexes()
|
||||
# 创建新的复合索引
|
||||
db.image_descriptions.create_index([("hash", 1), ("type", 1)], unique=True)
|
||||
|
||||
def _get_description_from_db(self, image_hash: str, description_type: str) -> Optional[str]:
|
||||
"""从数据库获取图片描述
|
||||
@@ -78,36 +83,21 @@ class ImageManager:
|
||||
description: 描述文本
|
||||
description_type: 描述类型 ('emoji' 或 'image')
|
||||
"""
|
||||
db.image_descriptions.update_one(
|
||||
{"hash": image_hash, "type": description_type},
|
||||
{"$set": {"description": description, "timestamp": int(time.time())}},
|
||||
upsert=True,
|
||||
)
|
||||
|
||||
async def get_image_by_url(self, url: str) -> Optional[str]:
|
||||
"""根据URL获取图像路径(带查重)
|
||||
Args:
|
||||
url: 图像URL
|
||||
Returns:
|
||||
str: 本地文件路径,不存在返回None
|
||||
"""
|
||||
try:
|
||||
# 先查找是否已存在
|
||||
existing = db.images.find_one({"url": url})
|
||||
if existing:
|
||||
return existing["path"]
|
||||
|
||||
# 下载图像
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.get(url) as resp:
|
||||
if resp.status == 200:
|
||||
image_bytes = await resp.read()
|
||||
return await self.save_image(image_bytes, url=url)
|
||||
return None
|
||||
|
||||
db.image_descriptions.update_one(
|
||||
{"hash": image_hash, "type": description_type},
|
||||
{
|
||||
"$set": {
|
||||
"description": description,
|
||||
"timestamp": int(time.time()),
|
||||
"hash": image_hash, # 确保hash字段存在
|
||||
"type": description_type, # 确保type字段存在
|
||||
}
|
||||
},
|
||||
upsert=True,
|
||||
)
|
||||
except Exception as e:
|
||||
logger.error(f"获取图像失败: {str(e)}")
|
||||
return None
|
||||
logger.error(f"保存描述到数据库失败: {str(e)}")
|
||||
|
||||
async def get_emoji_description(self, image_base64: str) -> str:
|
||||
"""获取表情包描述,带查重和保存功能"""
|
||||
@@ -129,7 +119,7 @@ class ImageManager:
|
||||
|
||||
cached_description = self._get_description_from_db(image_hash, "emoji")
|
||||
if cached_description:
|
||||
logger.warning(f"虽然生成了描述,但找到缓存表情包描述: {cached_description}")
|
||||
logger.warning(f"虽然生成了描述,但是找到缓存表情包描述: {cached_description}")
|
||||
return f"[表情包:{cached_description}]"
|
||||
|
||||
# 根据配置决定是否保存图片
|
||||
@@ -170,7 +160,6 @@ class ImageManager:
|
||||
async def get_image_description(self, image_base64: str) -> str:
|
||||
"""获取普通图片描述,带查重和保存功能"""
|
||||
try:
|
||||
print("处理图片中")
|
||||
# 计算图片哈希
|
||||
image_bytes = base64.b64decode(image_base64)
|
||||
image_hash = hashlib.md5(image_bytes).hexdigest()
|
||||
@@ -179,7 +168,7 @@ class ImageManager:
|
||||
# 查询缓存的描述
|
||||
cached_description = self._get_description_from_db(image_hash, "image")
|
||||
if cached_description:
|
||||
print("图片描述缓存中")
|
||||
logger.info(f"图片描述缓存中 {cached_description}")
|
||||
return f"[图片:{cached_description}]"
|
||||
|
||||
# 调用AI获取描述
|
||||
@@ -187,12 +176,13 @@ class ImageManager:
|
||||
"请用中文描述这张图片的内容。如果有文字,请把文字都描述出来。并尝试猜测这个图片的含义。最多200个字。"
|
||||
)
|
||||
description, _ = await self._llm.generate_response_for_image(prompt, image_base64, image_format)
|
||||
cached_description = self._get_description_from_db(image_hash, "emoji")
|
||||
|
||||
cached_description = self._get_description_from_db(image_hash, "image")
|
||||
if cached_description:
|
||||
logger.info(f"缓存图片描述: {cached_description}")
|
||||
logger.warning(f"虽然生成了描述,但是找到缓存图片描述 {cached_description}")
|
||||
return f"[图片:{cached_description}]"
|
||||
|
||||
print(f"描述是{description}")
|
||||
logger.info(f"描述是{description}")
|
||||
|
||||
if description is None:
|
||||
logger.warning("AI未能生成图片描述")
|
||||
|
||||
@@ -5,14 +5,16 @@ from .relationship_manager import relationship_manager
|
||||
def get_user_nickname(user_id: int) -> str:
|
||||
if int(user_id) == int(global_config.BOT_QQ):
|
||||
return global_config.BOT_NICKNAME
|
||||
# print(user_id)
|
||||
# print(user_id)
|
||||
return relationship_manager.get_name(user_id)
|
||||
|
||||
|
||||
def get_user_cardname(user_id: int) -> str:
|
||||
if int(user_id) == int(global_config.BOT_QQ):
|
||||
return global_config.BOT_NICKNAME
|
||||
# print(user_id)
|
||||
return ''
|
||||
# print(user_id)
|
||||
return ""
|
||||
|
||||
|
||||
def get_groupname(group_id: int) -> str:
|
||||
return f"群{group_id}"
|
||||
return f"群{group_id}"
|
||||
|
||||
@@ -1,109 +1,259 @@
|
||||
import asyncio
|
||||
import random
|
||||
import time
|
||||
from typing import Dict
|
||||
from loguru import logger
|
||||
|
||||
|
||||
from .config import global_config
|
||||
from .chat_stream import ChatStream
|
||||
|
||||
from loguru import logger
|
||||
|
||||
|
||||
class WillingManager:
|
||||
def __init__(self):
|
||||
self.chat_reply_willing: Dict[str, float] = {} # 存储每个聊天流的回复意愿
|
||||
self.chat_high_willing_mode: Dict[str, bool] = {} # 存储每个聊天流是否处于高回复意愿期
|
||||
self.chat_msg_count: Dict[str, int] = {} # 存储每个聊天流接收到的消息数量
|
||||
self.chat_last_mode_change: Dict[str, float] = {} # 存储每个聊天流上次模式切换的时间
|
||||
self.chat_high_willing_duration: Dict[str, int] = {} # 高意愿期持续时间(秒)
|
||||
self.chat_low_willing_duration: Dict[str, int] = {} # 低意愿期持续时间(秒)
|
||||
self.chat_last_reply_time: Dict[str, float] = {} # 存储每个聊天流上次回复的时间
|
||||
self.chat_last_sender_id: Dict[str, str] = {} # 存储每个聊天流上次回复的用户ID
|
||||
self.chat_conversation_context: Dict[str, bool] = {} # 标记是否处于对话上下文中
|
||||
self._decay_task = None
|
||||
self._mode_switch_task = None
|
||||
self._started = False
|
||||
|
||||
|
||||
async def _decay_reply_willing(self):
|
||||
"""定期衰减回复意愿"""
|
||||
while True:
|
||||
await asyncio.sleep(5)
|
||||
for chat_id in self.chat_reply_willing:
|
||||
self.chat_reply_willing[chat_id] = max(0, self.chat_reply_willing[chat_id] * 0.6)
|
||||
|
||||
is_high_mode = self.chat_high_willing_mode.get(chat_id, False)
|
||||
if is_high_mode:
|
||||
# 高回复意愿期内轻微衰减
|
||||
self.chat_reply_willing[chat_id] = max(0.5, self.chat_reply_willing[chat_id] * 0.95)
|
||||
else:
|
||||
# 低回复意愿期内正常衰减
|
||||
self.chat_reply_willing[chat_id] = max(0, self.chat_reply_willing[chat_id] * 0.8)
|
||||
|
||||
async def _mode_switch_check(self):
|
||||
"""定期检查是否需要切换回复意愿模式"""
|
||||
while True:
|
||||
current_time = time.time()
|
||||
await asyncio.sleep(10) # 每10秒检查一次
|
||||
|
||||
for chat_id in self.chat_high_willing_mode:
|
||||
last_change_time = self.chat_last_mode_change.get(chat_id, 0)
|
||||
is_high_mode = self.chat_high_willing_mode.get(chat_id, False)
|
||||
|
||||
# 获取当前模式的持续时间
|
||||
duration = 0
|
||||
if is_high_mode:
|
||||
duration = self.chat_high_willing_duration.get(chat_id, 180) # 默认3分钟
|
||||
else:
|
||||
duration = self.chat_low_willing_duration.get(chat_id, random.randint(300, 1200)) # 默认5-20分钟
|
||||
|
||||
# 检查是否需要切换模式
|
||||
if current_time - last_change_time > duration:
|
||||
self._switch_willing_mode(chat_id)
|
||||
elif not is_high_mode and random.random() < 0.1:
|
||||
# 低回复意愿期有10%概率随机切换到高回复期
|
||||
self._switch_willing_mode(chat_id)
|
||||
|
||||
# 检查对话上下文状态是否需要重置
|
||||
last_reply_time = self.chat_last_reply_time.get(chat_id, 0)
|
||||
if current_time - last_reply_time > 300: # 5分钟无交互,重置对话上下文
|
||||
self.chat_conversation_context[chat_id] = False
|
||||
|
||||
def _switch_willing_mode(self, chat_id: str):
|
||||
"""切换聊天流的回复意愿模式"""
|
||||
is_high_mode = self.chat_high_willing_mode.get(chat_id, False)
|
||||
|
||||
if is_high_mode:
|
||||
# 从高回复期切换到低回复期
|
||||
self.chat_high_willing_mode[chat_id] = False
|
||||
self.chat_reply_willing[chat_id] = 0.1 # 设置为最低回复意愿
|
||||
self.chat_low_willing_duration[chat_id] = random.randint(600, 1200) # 10-20分钟
|
||||
logger.debug(f"聊天流 {chat_id} 切换到低回复意愿期,持续 {self.chat_low_willing_duration[chat_id]} 秒")
|
||||
else:
|
||||
# 从低回复期切换到高回复期
|
||||
self.chat_high_willing_mode[chat_id] = True
|
||||
self.chat_reply_willing[chat_id] = 1.0 # 设置为较高回复意愿
|
||||
self.chat_high_willing_duration[chat_id] = random.randint(180, 240) # 3-4分钟
|
||||
logger.debug(f"聊天流 {chat_id} 切换到高回复意愿期,持续 {self.chat_high_willing_duration[chat_id]} 秒")
|
||||
|
||||
self.chat_last_mode_change[chat_id] = time.time()
|
||||
self.chat_msg_count[chat_id] = 0 # 重置消息计数
|
||||
|
||||
def get_willing(self, chat_stream: ChatStream) -> float:
|
||||
"""获取指定聊天流的回复意愿"""
|
||||
stream = chat_stream
|
||||
if stream:
|
||||
return self.chat_reply_willing.get(stream.stream_id, 0)
|
||||
return 0
|
||||
|
||||
|
||||
def set_willing(self, chat_id: str, willing: float):
|
||||
"""设置指定聊天流的回复意愿"""
|
||||
self.chat_reply_willing[chat_id] = willing
|
||||
|
||||
async def change_reply_willing_received(
|
||||
self,
|
||||
chat_stream: ChatStream,
|
||||
topic: str = None,
|
||||
is_mentioned_bot: bool = False,
|
||||
config=None,
|
||||
is_emoji: bool = False,
|
||||
interested_rate: float = 0,
|
||||
) -> float:
|
||||
|
||||
def _ensure_chat_initialized(self, chat_id: str):
|
||||
"""确保聊天流的所有数据已初始化"""
|
||||
if chat_id not in self.chat_reply_willing:
|
||||
self.chat_reply_willing[chat_id] = 0.1
|
||||
|
||||
if chat_id not in self.chat_high_willing_mode:
|
||||
self.chat_high_willing_mode[chat_id] = False
|
||||
self.chat_last_mode_change[chat_id] = time.time()
|
||||
self.chat_low_willing_duration[chat_id] = random.randint(300, 1200) # 5-20分钟
|
||||
|
||||
if chat_id not in self.chat_msg_count:
|
||||
self.chat_msg_count[chat_id] = 0
|
||||
|
||||
if chat_id not in self.chat_conversation_context:
|
||||
self.chat_conversation_context[chat_id] = False
|
||||
|
||||
async def change_reply_willing_received(self,
|
||||
chat_stream: ChatStream,
|
||||
topic: str = None,
|
||||
is_mentioned_bot: bool = False,
|
||||
config = None,
|
||||
is_emoji: bool = False,
|
||||
interested_rate: float = 0,
|
||||
sender_id: str = None) -> float:
|
||||
"""改变指定聊天流的回复意愿并返回回复概率"""
|
||||
# 获取或创建聊天流
|
||||
stream = chat_stream
|
||||
chat_id = stream.stream_id
|
||||
|
||||
current_time = time.time()
|
||||
|
||||
self._ensure_chat_initialized(chat_id)
|
||||
|
||||
# 增加消息计数
|
||||
self.chat_msg_count[chat_id] = self.chat_msg_count.get(chat_id, 0) + 1
|
||||
|
||||
current_willing = self.chat_reply_willing.get(chat_id, 0)
|
||||
|
||||
if is_mentioned_bot and current_willing < 1.0:
|
||||
current_willing += 0.9
|
||||
is_high_mode = self.chat_high_willing_mode.get(chat_id, False)
|
||||
msg_count = self.chat_msg_count.get(chat_id, 0)
|
||||
in_conversation_context = self.chat_conversation_context.get(chat_id, False)
|
||||
|
||||
# 检查是否是对话上下文中的追问
|
||||
last_reply_time = self.chat_last_reply_time.get(chat_id, 0)
|
||||
last_sender = self.chat_last_sender_id.get(chat_id, "")
|
||||
is_follow_up_question = False
|
||||
|
||||
# 如果是同一个人在短时间内(2分钟内)发送消息,且消息数量较少(<=5条),视为追问
|
||||
if sender_id and sender_id == last_sender and current_time - last_reply_time < 120 and msg_count <= 5:
|
||||
is_follow_up_question = True
|
||||
in_conversation_context = True
|
||||
self.chat_conversation_context[chat_id] = True
|
||||
logger.debug(f"检测到追问 (同一用户), 提高回复意愿")
|
||||
current_willing += 0.3
|
||||
|
||||
# 特殊情况处理
|
||||
if is_mentioned_bot:
|
||||
current_willing += 0.5
|
||||
in_conversation_context = True
|
||||
self.chat_conversation_context[chat_id] = True
|
||||
logger.debug(f"被提及, 当前意愿: {current_willing}")
|
||||
elif is_mentioned_bot:
|
||||
current_willing += 0.05
|
||||
logger.debug(f"被重复提及, 当前意愿: {current_willing}")
|
||||
|
||||
|
||||
if is_emoji:
|
||||
current_willing *= 0.1
|
||||
logger.debug(f"表情包, 当前意愿: {current_willing}")
|
||||
|
||||
logger.debug(f"放大系数_interested_rate: {global_config.response_interested_rate_amplifier}")
|
||||
interested_rate *= global_config.response_interested_rate_amplifier # 放大回复兴趣度
|
||||
if interested_rate > 0.4:
|
||||
# print(f"兴趣度: {interested_rate}, 当前意愿: {current_willing}")
|
||||
current_willing += interested_rate - 0.4
|
||||
|
||||
current_willing *= global_config.response_willing_amplifier # 放大回复意愿
|
||||
# print(f"放大系数_willing: {global_config.response_willing_amplifier}, 当前意愿: {current_willing}")
|
||||
|
||||
reply_probability = max((current_willing - 0.45) * 2, 0)
|
||||
|
||||
|
||||
# 根据话题兴趣度适当调整
|
||||
if interested_rate > 0.5:
|
||||
current_willing += (interested_rate - 0.5) * 0.5
|
||||
|
||||
# 根据当前模式计算回复概率
|
||||
base_probability = 0.0
|
||||
|
||||
if in_conversation_context:
|
||||
# 在对话上下文中,降低基础回复概率
|
||||
base_probability = 0.5 if is_high_mode else 0.25
|
||||
logger.debug(f"处于对话上下文中,基础回复概率: {base_probability}")
|
||||
elif is_high_mode:
|
||||
# 高回复周期:4-8句话有50%的概率会回复一次
|
||||
base_probability = 0.50 if 4 <= msg_count <= 8 else 0.2
|
||||
else:
|
||||
# 低回复周期:需要最少15句才有30%的概率会回一句
|
||||
base_probability = 0.30 if msg_count >= 15 else 0.03 * min(msg_count, 10)
|
||||
|
||||
# 考虑回复意愿的影响
|
||||
reply_probability = base_probability * current_willing
|
||||
|
||||
# 检查群组权限(如果是群聊)
|
||||
if chat_stream.group_info:
|
||||
if chat_stream.group_info and config:
|
||||
if chat_stream.group_info.group_id in config.talk_frequency_down_groups:
|
||||
reply_probability = reply_probability / global_config.down_frequency_rate
|
||||
|
||||
reply_probability = min(reply_probability, 1)
|
||||
# 限制最大回复概率
|
||||
reply_probability = min(reply_probability, 0.75) # 设置最大回复概率为75%
|
||||
if reply_probability < 0:
|
||||
reply_probability = 0
|
||||
|
||||
|
||||
# 记录当前发送者ID以便后续追踪
|
||||
if sender_id:
|
||||
self.chat_last_sender_id[chat_id] = sender_id
|
||||
|
||||
self.chat_reply_willing[chat_id] = min(current_willing, 3.0)
|
||||
return reply_probability
|
||||
|
||||
|
||||
def change_reply_willing_sent(self, chat_stream: ChatStream):
|
||||
"""开始思考后降低聊天流的回复意愿"""
|
||||
stream = chat_stream
|
||||
if stream:
|
||||
current_willing = self.chat_reply_willing.get(stream.stream_id, 0)
|
||||
self.chat_reply_willing[stream.stream_id] = max(0, current_willing - 2)
|
||||
|
||||
def change_reply_willing_after_sent(self, chat_stream: ChatStream):
|
||||
"""发送消息后提高聊天流的回复意愿"""
|
||||
chat_id = stream.stream_id
|
||||
self._ensure_chat_initialized(chat_id)
|
||||
is_high_mode = self.chat_high_willing_mode.get(chat_id, False)
|
||||
current_willing = self.chat_reply_willing.get(chat_id, 0)
|
||||
|
||||
# 回复后减少回复意愿
|
||||
self.chat_reply_willing[chat_id] = max(0, current_willing - 0.3)
|
||||
|
||||
# 标记为对话上下文中
|
||||
self.chat_conversation_context[chat_id] = True
|
||||
|
||||
# 记录最后回复时间
|
||||
self.chat_last_reply_time[chat_id] = time.time()
|
||||
|
||||
# 重置消息计数
|
||||
self.chat_msg_count[chat_id] = 0
|
||||
|
||||
def change_reply_willing_not_sent(self, chat_stream: ChatStream):
|
||||
"""决定不回复后提高聊天流的回复意愿"""
|
||||
stream = chat_stream
|
||||
if stream:
|
||||
current_willing = self.chat_reply_willing.get(stream.stream_id, 0)
|
||||
if current_willing < 1:
|
||||
self.chat_reply_willing[stream.stream_id] = min(1, current_willing + 0.2)
|
||||
|
||||
chat_id = stream.stream_id
|
||||
self._ensure_chat_initialized(chat_id)
|
||||
is_high_mode = self.chat_high_willing_mode.get(chat_id, False)
|
||||
current_willing = self.chat_reply_willing.get(chat_id, 0)
|
||||
in_conversation_context = self.chat_conversation_context.get(chat_id, False)
|
||||
|
||||
# 根据当前模式调整不回复后的意愿增加
|
||||
if is_high_mode:
|
||||
willing_increase = 0.1
|
||||
elif in_conversation_context:
|
||||
# 在对话上下文中但决定不回复,小幅增加回复意愿
|
||||
willing_increase = 0.15
|
||||
else:
|
||||
willing_increase = random.uniform(0.05, 0.1)
|
||||
|
||||
self.chat_reply_willing[chat_id] = min(2.0, current_willing + willing_increase)
|
||||
|
||||
def change_reply_willing_after_sent(self, chat_stream: ChatStream):
|
||||
"""发送消息后提高聊天流的回复意愿"""
|
||||
# 由于已经在sent中处理,这个方法保留但不再需要额外调整
|
||||
pass
|
||||
|
||||
async def ensure_started(self):
|
||||
"""确保衰减任务已启动"""
|
||||
"""确保所有任务已启动"""
|
||||
if not self._started:
|
||||
if self._decay_task is None:
|
||||
self._decay_task = asyncio.create_task(self._decay_reply_willing())
|
||||
if self._mode_switch_task is None:
|
||||
self._mode_switch_task = asyncio.create_task(self._mode_switch_check())
|
||||
self._started = True
|
||||
|
||||
|
||||
# 创建全局实例
|
||||
willing_manager = WillingManager()
|
||||
willing_manager = WillingManager()
|
||||
@@ -14,7 +14,10 @@ from ..models.utils_model import LLM_request
|
||||
driver = get_driver()
|
||||
config = driver.config
|
||||
|
||||
|
||||
class ScheduleGenerator:
|
||||
enable_output: bool = True
|
||||
|
||||
def __init__(self):
|
||||
# 根据global_config.llm_normal这一字典配置指定模型
|
||||
# self.llm_scheduler = LLMModel(model = global_config.llm_normal,temperature=0.9)
|
||||
@@ -32,14 +35,16 @@ class ScheduleGenerator:
|
||||
yesterday = datetime.datetime.now() - datetime.timedelta(days=1)
|
||||
|
||||
self.today_schedule_text, self.today_schedule = await self.generate_daily_schedule(target_date=today)
|
||||
self.tomorrow_schedule_text, self.tomorrow_schedule = await self.generate_daily_schedule(target_date=tomorrow,
|
||||
read_only=True)
|
||||
self.tomorrow_schedule_text, self.tomorrow_schedule = await self.generate_daily_schedule(
|
||||
target_date=tomorrow, read_only=True
|
||||
)
|
||||
self.yesterday_schedule_text, self.yesterday_schedule = await self.generate_daily_schedule(
|
||||
target_date=yesterday, read_only=True)
|
||||
|
||||
async def generate_daily_schedule(self, target_date: datetime.datetime = None, read_only: bool = False) -> Dict[
|
||||
str, str]:
|
||||
target_date=yesterday, read_only=True
|
||||
)
|
||||
|
||||
async def generate_daily_schedule(
|
||||
self, target_date: datetime.datetime = None, read_only: bool = False
|
||||
) -> Dict[str, str]:
|
||||
date_str = target_date.strftime("%Y-%m-%d")
|
||||
weekday = target_date.strftime("%A")
|
||||
|
||||
@@ -47,28 +52,33 @@ class ScheduleGenerator:
|
||||
|
||||
existing_schedule = db.schedule.find_one({"date": date_str})
|
||||
if existing_schedule:
|
||||
logger.debug(f"{date_str}的日程已存在:")
|
||||
if self.enable_output:
|
||||
logger.debug(f"{date_str}的日程已存在:")
|
||||
schedule_text = existing_schedule["schedule"]
|
||||
# print(self.schedule_text)
|
||||
|
||||
elif not read_only:
|
||||
logger.debug(f"{date_str}的日程不存在,准备生成新的日程。")
|
||||
prompt = f"""我是{global_config.BOT_NICKNAME},{global_config.PROMPT_SCHEDULE_GEN},请为我生成{date_str}({weekday})的日程安排,包括:""" + \
|
||||
"""
|
||||
prompt = (
|
||||
f"""我是{global_config.BOT_NICKNAME},{global_config.PROMPT_SCHEDULE_GEN},请为我生成{date_str}({weekday})的日程安排,包括:"""
|
||||
+ """
|
||||
1. 早上的学习和工作安排
|
||||
2. 下午的活动和任务
|
||||
3. 晚上的计划和休息时间
|
||||
请按照时间顺序列出具体时间点和对应的活动,用一个时间点而不是时间段来表示时间,用JSON格式返回日程表,仅返回内容,不要返回注释,不要添加任何markdown或代码块样式,时间采用24小时制,格式为{"时间": "活动","时间": "活动",...}。"""
|
||||
)
|
||||
|
||||
try:
|
||||
schedule_text, _ = await self.llm_scheduler.generate_response(prompt)
|
||||
db.schedule.insert_one({"date": date_str, "schedule": schedule_text})
|
||||
self.enable_output = True
|
||||
except Exception as e:
|
||||
logger.error(f"生成日程失败: {str(e)}")
|
||||
schedule_text = "生成日程时出错了"
|
||||
# print(self.schedule_text)
|
||||
else:
|
||||
logger.debug(f"{date_str}的日程不存在。")
|
||||
if self.enable_output:
|
||||
logger.debug(f"{date_str}的日程不存在。")
|
||||
schedule_text = "忘了"
|
||||
|
||||
return schedule_text, None
|
||||
@@ -95,7 +105,7 @@ class ScheduleGenerator:
|
||||
|
||||
# 找到最接近当前时间的任务
|
||||
closest_time = None
|
||||
min_diff = float('inf')
|
||||
min_diff = float("inf")
|
||||
|
||||
# 检查今天的日程
|
||||
if not self.today_schedule:
|
||||
@@ -148,6 +158,7 @@ class ScheduleGenerator:
|
||||
for time_str, activity in self.today_schedule.items():
|
||||
logger.info(f"时间[{time_str}]: 活动[{activity}]")
|
||||
logger.info("==================")
|
||||
self.enable_output = False
|
||||
|
||||
|
||||
# def main():
|
||||
|
||||
Reference in New Issue
Block a user