8
.github/workflows/ruff.yml
vendored
Normal file
@@ -0,0 +1,8 @@
|
|||||||
|
name: Ruff
|
||||||
|
on: [ push, pull_request ]
|
||||||
|
jobs:
|
||||||
|
ruff:
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
steps:
|
||||||
|
- uses: actions/checkout@v4
|
||||||
|
- uses: astral-sh/ruff-action@v3
|
||||||
13
.gitignore
vendored
@@ -1,7 +1,9 @@
|
|||||||
data/
|
data/
|
||||||
|
data1/
|
||||||
mongodb/
|
mongodb/
|
||||||
NapCat.Framework.Windows.Once/
|
NapCat.Framework.Windows.Once/
|
||||||
log/
|
log/
|
||||||
|
logs/
|
||||||
/test
|
/test
|
||||||
/src/test
|
/src/test
|
||||||
message_queue_content.txt
|
message_queue_content.txt
|
||||||
@@ -188,14 +190,17 @@ cython_debug/
|
|||||||
|
|
||||||
# PyPI configuration file
|
# PyPI configuration file
|
||||||
.pypirc
|
.pypirc
|
||||||
.env
|
|
||||||
|
|
||||||
# jieba
|
# jieba
|
||||||
jieba.cache
|
jieba.cache
|
||||||
|
|
||||||
|
# .vscode
|
||||||
# vscode
|
!.vscode/settings.json
|
||||||
/.vscode
|
|
||||||
|
|
||||||
# direnv
|
# direnv
|
||||||
/.direnv
|
/.direnv
|
||||||
|
|
||||||
|
# JetBrains
|
||||||
|
.idea
|
||||||
|
*.iml
|
||||||
|
*.ipr
|
||||||
|
|||||||
10
.pre-commit-config.yaml
Normal file
@@ -0,0 +1,10 @@
|
|||||||
|
repos:
|
||||||
|
- repo: https://github.com/astral-sh/ruff-pre-commit
|
||||||
|
# Ruff version.
|
||||||
|
rev: v0.9.10
|
||||||
|
hooks:
|
||||||
|
# Run the linter.
|
||||||
|
- id: ruff
|
||||||
|
args: [ --fix ]
|
||||||
|
# Run the formatter.
|
||||||
|
- id: ruff-format
|
||||||
48
CLAUDE.md
Normal file
@@ -0,0 +1,48 @@
|
|||||||
|
# MaiMBot 开发指南
|
||||||
|
|
||||||
|
## 🛠️ 常用命令
|
||||||
|
|
||||||
|
- **运行机器人**: `python run.py` 或 `python bot.py`
|
||||||
|
- **安装依赖**: `pip install --upgrade -r requirements.txt`
|
||||||
|
- **Docker 部署**: `docker-compose up`
|
||||||
|
- **代码检查**: `ruff check .`
|
||||||
|
- **代码格式化**: `ruff format .`
|
||||||
|
- **内存可视化**: `run_memory_vis.bat` 或 `python -m src.plugins.memory_system.draw_memory`
|
||||||
|
- **推理过程可视化**: `script/run_thingking.bat`
|
||||||
|
|
||||||
|
## 🔧 脚本工具
|
||||||
|
|
||||||
|
- **运行MongoDB**: `script/run_db.bat` - 在端口27017启动MongoDB
|
||||||
|
- **Windows完整启动**: `script/run_windows.bat` - 检查Python版本、设置虚拟环境、安装依赖并运行机器人
|
||||||
|
- **快速启动**: `script/run_maimai.bat` - 设置UTF-8编码并执行"nb run"命令
|
||||||
|
|
||||||
|
## 📝 代码风格
|
||||||
|
|
||||||
|
- **Python版本**: 3.9+
|
||||||
|
- **行长度限制**: 88字符
|
||||||
|
- **命名规范**:
|
||||||
|
- `snake_case` 用于函数和变量
|
||||||
|
- `PascalCase` 用于类
|
||||||
|
- `_prefix` 用于私有成员
|
||||||
|
- **导入顺序**: 标准库 → 第三方库 → 本地模块
|
||||||
|
- **异步编程**: 对I/O操作使用async/await
|
||||||
|
- **日志记录**: 使用loguru进行一致的日志记录
|
||||||
|
- **错误处理**: 使用带有具体异常的try/except
|
||||||
|
- **文档**: 为类和公共函数编写docstrings
|
||||||
|
|
||||||
|
## 🧩 系统架构
|
||||||
|
|
||||||
|
- **框架**: NoneBot2框架与插件架构
|
||||||
|
- **数据库**: MongoDB持久化存储
|
||||||
|
- **设计模式**: 工厂模式和单例管理器
|
||||||
|
- **配置管理**: 使用环境变量和TOML文件
|
||||||
|
- **内存系统**: 基于图的记忆结构,支持记忆构建、压缩、检索和遗忘
|
||||||
|
- **情绪系统**: 情绪模拟与概率权重
|
||||||
|
- **LLM集成**: 支持多个LLM服务提供商(ChatAnywhere, SiliconFlow, DeepSeek)
|
||||||
|
|
||||||
|
## ⚙️ 环境配置
|
||||||
|
|
||||||
|
- 使用`template.env`作为环境变量模板
|
||||||
|
- 使用`template/bot_config_template.toml`作为机器人配置模板
|
||||||
|
- MongoDB配置: 主机、端口、数据库名
|
||||||
|
- API密钥配置: 各LLM提供商的API密钥
|
||||||
64
README.md
@@ -1,6 +1,5 @@
|
|||||||
# 麦麦!MaiMBot (编辑中)
|
# 麦麦!MaiMBot (编辑中)
|
||||||
|
|
||||||
|
|
||||||
<div align="center">
|
<div align="center">
|
||||||
|
|
||||||

|

|
||||||
@@ -18,7 +17,11 @@
|
|||||||
- MongoDB 提供数据持久化支持
|
- MongoDB 提供数据持久化支持
|
||||||
- NapCat 作为QQ协议端支持
|
- NapCat 作为QQ协议端支持
|
||||||
|
|
||||||
**最新版本: v0.5.***
|
**最新版本: v0.5.13**
|
||||||
|
> [!WARNING]
|
||||||
|
> 注意,3月12日的v0.5.13, 该版本更新较大,建议单独开文件夹部署,然后转移/data文件 和数据库,数据库可能需要删除messages下的内容(不需要删除记忆)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
<div align="center">
|
<div align="center">
|
||||||
<a href="https://www.bilibili.com/video/BV1amAneGE3P" target="_blank">
|
<a href="https://www.bilibili.com/video/BV1amAneGE3P" target="_blank">
|
||||||
@@ -29,44 +32,56 @@
|
|||||||
</a>
|
</a>
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
> ⚠️ **注意事项**
|
> [!WARNING]
|
||||||
> - 项目处于活跃开发阶段,代码可能随时更改
|
> - 项目处于活跃开发阶段,代码可能随时更改
|
||||||
> - 文档未完善,有问题可以提交 Issue 或者 Discussion
|
> - 文档未完善,有问题可以提交 Issue 或者 Discussion
|
||||||
> - QQ机器人存在被限制风险,请自行了解,谨慎使用
|
> - QQ机器人存在被限制风险,请自行了解,谨慎使用
|
||||||
> - 由于持续迭代,可能存在一些已知或未知的bug
|
> - 由于持续迭代,可能存在一些已知或未知的bug
|
||||||
> - 由于开发中,可能消耗较多token
|
> - 由于开发中,可能消耗较多token
|
||||||
|
|
||||||
**交流群**: 766798517 一群人较多,建议加下面的(开发和建议相关讨论)不一定有空回复,会优先写文档和代码
|
## 💬交流群
|
||||||
**交流群**: 571780722 另一个群(开发和建议相关讨论)不一定有空回复,会优先写文档和代码
|
- [一群](https://qm.qq.com/q/VQ3XZrWgMs) 766798517 ,建议加下面的(开发和建议相关讨论)不一定有空回复,会优先写文档和代码
|
||||||
**交流群**: 1035228475 另一个群(开发和建议相关讨论)不一定有空回复,会优先写文档和代码
|
- [二群](https://qm.qq.com/q/RzmCiRtHEW) 571780722 (开发和建议相关讨论)不一定有空回复,会优先写文档和代码
|
||||||
|
- [三群](https://qm.qq.com/q/wlH5eT8OmQ) 1035228475(开发和建议相关讨论)不一定有空回复,会优先写文档和代码
|
||||||
|
|
||||||
**其他平台版本**
|
|
||||||
|
|
||||||
|
**📚 有热心网友创作的wiki:** https://maimbot.pages.dev/
|
||||||
|
|
||||||
|
|
||||||
|
**😊 其他平台版本**
|
||||||
|
|
||||||
- (由 [CabLate](https://github.com/cablate) 贡献) [Telegram 与其他平台(未来可能会有)的版本](https://github.com/cablate/MaiMBot/tree/telegram) - [集中讨论串](https://github.com/SengokuCola/MaiMBot/discussions/149)
|
- (由 [CabLate](https://github.com/cablate) 贡献) [Telegram 与其他平台(未来可能会有)的版本](https://github.com/cablate/MaiMBot/tree/telegram) - [集中讨论串](https://github.com/SengokuCola/MaiMBot/discussions/149)
|
||||||
|
|
||||||
##
|
|
||||||
<div align="left">
|
<div align="left">
|
||||||
<h2>📚 文档 ⬇️ 快速开始使用麦麦 ⬇️</h2>
|
<h2>📚 文档 ⬇️ 快速开始使用麦麦 ⬇️</h2>
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
### 部署方式
|
### 部署方式
|
||||||
|
|
||||||
如果你不知道Docker是什么,建议寻找相关教程或使用手动部署(现在不建议使用docker,更新慢,可能不适配)
|
- 📦 **Windows 一键傻瓜式部署**:请运行项目根目录中的 `run.bat`,部署完成后请参照后续配置指南进行配置
|
||||||
|
|
||||||
|
- 📦 Linux 自动部署(实验) :请下载并运行项目根目录中的`run.sh`并按照提示安装,部署完成后请参照后续配置指南进行配置
|
||||||
|
|
||||||
|
- [📦 Windows 手动部署指南 ](docs/manual_deploy_windows.md)
|
||||||
|
|
||||||
|
- [📦 Linux 手动部署指南 ](docs/manual_deploy_linux.md)
|
||||||
|
|
||||||
|
如果你不知道Docker是什么,建议寻找相关教程或使用手动部署 **(现在不建议使用docker,更新慢,可能不适配)**
|
||||||
|
|
||||||
- [🐳 Docker部署指南](docs/docker_deploy.md)
|
- [🐳 Docker部署指南](docs/docker_deploy.md)
|
||||||
|
|
||||||
|
|
||||||
- [📦 手动部署指南 Windows](docs/manual_deploy_windows.md)
|
|
||||||
|
|
||||||
|
|
||||||
- [📦 手动部署指南 Linux](docs/manual_deploy_linux.md)
|
|
||||||
|
|
||||||
- 📦 Windows 一键傻瓜式部署,请运行项目根目录中的 ```run.bat```,部署完成后请参照后续配置指南进行配置
|
|
||||||
|
|
||||||
### 配置说明
|
### 配置说明
|
||||||
|
|
||||||
- [🎀 新手配置指南](docs/installation_cute.md) - 通俗易懂的配置教程,适合初次使用的猫娘
|
- [🎀 新手配置指南](docs/installation_cute.md) - 通俗易懂的配置教程,适合初次使用的猫娘
|
||||||
- [⚙️ 标准配置指南](docs/installation_standard.md) - 简明专业的配置说明,适合有经验的用户
|
- [⚙️ 标准配置指南](docs/installation_standard.md) - 简明专业的配置说明,适合有经验的用户
|
||||||
|
|
||||||
|
### 常见问题
|
||||||
|
|
||||||
|
- [❓ 快速 Q & A ](docs/fast_q_a.md) - 针对新手的疑难解答,适合完全没接触过编程的新手
|
||||||
|
|
||||||
<div align="left">
|
<div align="left">
|
||||||
<h3>了解麦麦 </h3>
|
<h3>了解麦麦 </h3>
|
||||||
</div>
|
</div>
|
||||||
@@ -76,6 +91,7 @@
|
|||||||
## 🎯 功能介绍
|
## 🎯 功能介绍
|
||||||
|
|
||||||
### 💬 聊天功能
|
### 💬 聊天功能
|
||||||
|
|
||||||
- 支持关键词检索主动发言:对消息的话题topic进行识别,如果检测到麦麦存储过的话题就会主动进行发言
|
- 支持关键词检索主动发言:对消息的话题topic进行识别,如果检测到麦麦存储过的话题就会主动进行发言
|
||||||
- 支持bot名字呼唤发言:检测到"麦麦"会主动发言,可配置
|
- 支持bot名字呼唤发言:检测到"麦麦"会主动发言,可配置
|
||||||
- 支持多模型,多厂商自定义配置
|
- 支持多模型,多厂商自定义配置
|
||||||
@@ -84,31 +100,33 @@
|
|||||||
- 错别字和多条回复功能:麦麦可以随机生成错别字,会多条发送回复以及对消息进行reply
|
- 错别字和多条回复功能:麦麦可以随机生成错别字,会多条发送回复以及对消息进行reply
|
||||||
|
|
||||||
### 😊 表情包功能
|
### 😊 表情包功能
|
||||||
|
|
||||||
- 支持根据发言内容发送对应情绪的表情包
|
- 支持根据发言内容发送对应情绪的表情包
|
||||||
- 会自动偷群友的表情包
|
- 会自动偷群友的表情包
|
||||||
|
|
||||||
### 📅 日程功能
|
### 📅 日程功能
|
||||||
|
|
||||||
- 麦麦会自动生成一天的日程,实现更拟人的回复
|
- 麦麦会自动生成一天的日程,实现更拟人的回复
|
||||||
|
|
||||||
### 🧠 记忆功能
|
### 🧠 记忆功能
|
||||||
|
|
||||||
- 对聊天记录进行概括存储,在需要时调用,待完善
|
- 对聊天记录进行概括存储,在需要时调用,待完善
|
||||||
|
|
||||||
### 📚 知识库功能
|
### 📚 知识库功能
|
||||||
|
|
||||||
- 基于embedding模型的知识库,手动放入txt会自动识别,写完了,暂时禁用
|
- 基于embedding模型的知识库,手动放入txt会自动识别,写完了,暂时禁用
|
||||||
|
|
||||||
### 👥 关系功能
|
### 👥 关系功能
|
||||||
|
|
||||||
- 针对每个用户创建"关系",可以对不同用户进行个性化回复,目前只有极其简单的好感度(WIP)
|
- 针对每个用户创建"关系",可以对不同用户进行个性化回复,目前只有极其简单的好感度(WIP)
|
||||||
- 针对每个群创建"群印象",可以对不同群进行个性化回复(WIP)
|
- 针对每个群创建"群印象",可以对不同群进行个性化回复(WIP)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 开发计划TODO:LIST
|
## 开发计划TODO:LIST
|
||||||
|
|
||||||
规划主线
|
规划主线
|
||||||
0.6.0:记忆系统更新
|
0.6.0:记忆系统更新
|
||||||
0.7.0: 麦麦RunTime
|
0.7.0: 麦麦RunTime
|
||||||
|
|
||||||
|
|
||||||
- 人格功能:WIP
|
- 人格功能:WIP
|
||||||
- 群氛围功能:WIP
|
- 群氛围功能:WIP
|
||||||
- 图片发送,转发功能:WIP
|
- 图片发送,转发功能:WIP
|
||||||
@@ -128,7 +146,6 @@
|
|||||||
- 采用截断生成加快麦麦的反应速度
|
- 采用截断生成加快麦麦的反应速度
|
||||||
- 改进发送消息的触发
|
- 改进发送消息的触发
|
||||||
|
|
||||||
|
|
||||||
## 设计理念
|
## 设计理念
|
||||||
|
|
||||||
- **千石可乐说:**
|
- **千石可乐说:**
|
||||||
@@ -138,13 +155,14 @@
|
|||||||
- 如果人类真的需要一个AI来陪伴自己,并不是所有人都需要一个完美的,能解决所有问题的helpful assistant,而是一个会犯错的,拥有自己感知和想法的"生命形式"。
|
- 如果人类真的需要一个AI来陪伴自己,并不是所有人都需要一个完美的,能解决所有问题的helpful assistant,而是一个会犯错的,拥有自己感知和想法的"生命形式"。
|
||||||
- 代码会保持开源和开放,但个人希望MaiMbot的运行时数据保持封闭,尽量避免以显式命令来对其进行控制和调试.我认为一个你无法完全掌控的个体才更能让你感觉到它的自主性,而视其成为一个对话机器.
|
- 代码会保持开源和开放,但个人希望MaiMbot的运行时数据保持封闭,尽量避免以显式命令来对其进行控制和调试.我认为一个你无法完全掌控的个体才更能让你感觉到它的自主性,而视其成为一个对话机器.
|
||||||
|
|
||||||
|
|
||||||
## 📌 注意事项
|
## 📌 注意事项
|
||||||
SengokuCola纯编程外行,面向cursor编程,很多代码史一样多多包涵
|
|
||||||
|
|
||||||
> ⚠️ **警告**:本应用生成内容来自人工智能模型,由 AI 生成,请仔细甄别,请勿用于违反法律的用途,AI生成内容不代表本人观点和立场。
|
SengokuCola~~纯编程外行,面向cursor编程,很多代码写得不好多多包涵~~已得到大脑升级
|
||||||
|
> [!WARNING]
|
||||||
|
> 本应用生成内容来自人工智能模型,由 AI 生成,请仔细甄别,请勿用于违反法律的用途,AI生成内容不代表本人观点和立场。
|
||||||
|
|
||||||
## 致谢
|
## 致谢
|
||||||
|
|
||||||
[nonebot2](https://github.com/nonebot/nonebot2): 跨平台 Python 异步聊天机器人框架
|
[nonebot2](https://github.com/nonebot/nonebot2): 跨平台 Python 异步聊天机器人框架
|
||||||
[NapCat](https://github.com/NapNeko/NapCatQQ): 现代化的基于 NTQQ 的 Bot 协议端实现
|
[NapCat](https://github.com/NapNeko/NapCatQQ): 现代化的基于 NTQQ 的 Bot 协议端实现
|
||||||
|
|
||||||
@@ -156,6 +174,6 @@ SengokuCola纯编程外行,面向cursor编程,很多代码史一样多多包
|
|||||||
<img src="https://contrib.rocks/image?repo=SengokuCola/MaiMBot" />
|
<img src="https://contrib.rocks/image?repo=SengokuCola/MaiMBot" />
|
||||||
</a>
|
</a>
|
||||||
|
|
||||||
|
|
||||||
## Stargazers over time
|
## Stargazers over time
|
||||||
|
|
||||||
[](https://starchart.cc/SengokuCola/MaiMBot)
|
[](https://starchart.cc/SengokuCola/MaiMBot)
|
||||||
|
|||||||
120
bot.py
@@ -1,9 +1,12 @@
|
|||||||
|
import asyncio
|
||||||
import os
|
import os
|
||||||
import shutil
|
import shutil
|
||||||
import sys
|
import sys
|
||||||
|
|
||||||
import nonebot
|
import nonebot
|
||||||
import time
|
import time
|
||||||
|
|
||||||
|
import uvicorn
|
||||||
from dotenv import load_dotenv
|
from dotenv import load_dotenv
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
from nonebot.adapters.onebot.v11 import Adapter
|
from nonebot.adapters.onebot.v11 import Adapter
|
||||||
@@ -12,6 +15,8 @@ import platform
|
|||||||
# 获取没有加载env时的环境变量
|
# 获取没有加载env时的环境变量
|
||||||
env_mask = {key: os.getenv(key) for key in os.environ}
|
env_mask = {key: os.getenv(key) for key in os.environ}
|
||||||
|
|
||||||
|
uvicorn_server = None
|
||||||
|
|
||||||
|
|
||||||
def easter_egg():
|
def easter_egg():
|
||||||
# 彩蛋
|
# 彩蛋
|
||||||
@@ -58,7 +63,7 @@ def init_env():
|
|||||||
|
|
||||||
# 首先加载基础环境变量.env
|
# 首先加载基础环境变量.env
|
||||||
if os.path.exists(".env"):
|
if os.path.exists(".env"):
|
||||||
load_dotenv(".env")
|
load_dotenv(".env", override=True)
|
||||||
logger.success("成功加载基础环境变量配置")
|
logger.success("成功加载基础环境变量配置")
|
||||||
|
|
||||||
|
|
||||||
@@ -72,10 +77,7 @@ def load_env():
|
|||||||
logger.success("加载开发环境变量配置")
|
logger.success("加载开发环境变量配置")
|
||||||
load_dotenv(".env.dev", override=True) # override=True 允许覆盖已存在的环境变量
|
load_dotenv(".env.dev", override=True) # override=True 允许覆盖已存在的环境变量
|
||||||
|
|
||||||
fn_map = {
|
fn_map = {"prod": prod, "dev": dev}
|
||||||
"prod": prod,
|
|
||||||
"dev": dev
|
|
||||||
}
|
|
||||||
|
|
||||||
env = os.getenv("ENVIRONMENT")
|
env = os.getenv("ENVIRONMENT")
|
||||||
logger.info(f"[load_env] 当前的 ENVIRONMENT 变量值:{env}")
|
logger.info(f"[load_env] 当前的 ENVIRONMENT 变量值:{env}")
|
||||||
@@ -93,15 +95,43 @@ def load_env():
|
|||||||
|
|
||||||
|
|
||||||
def load_logger():
|
def load_logger():
|
||||||
logger.remove() # 移除默认配置
|
logger.remove()
|
||||||
logger.add(
|
|
||||||
sys.stderr,
|
# 配置日志基础路径
|
||||||
format="<green>{time:YYYY-MM-DD HH:mm:ss.SSS}</green> <fg #777777>|</> <level>{level: <7}</level> <fg "
|
log_path = os.path.join(os.getcwd(), "logs")
|
||||||
"#777777>|</> <cyan>{name:.<8}</cyan>:<cyan>{function:.<8}</cyan>:<cyan>{line: >4}</cyan> <fg "
|
if not os.path.exists(log_path):
|
||||||
"#777777>-</> <level>{message}</level>",
|
os.makedirs(log_path)
|
||||||
colorize=True,
|
|
||||||
level=os.getenv("LOG_LEVEL", "INFO") # 根据环境设置日志级别,默认为INFO
|
current_env = os.getenv("ENVIRONMENT", "dev")
|
||||||
|
|
||||||
|
# 公共配置参数
|
||||||
|
log_level = os.getenv("LOG_LEVEL", "INFO" if current_env == "prod" else "DEBUG")
|
||||||
|
log_filter = lambda record: (
|
||||||
|
("nonebot" not in record["name"] or record["level"].no >= logger.level("ERROR").no)
|
||||||
|
if current_env == "prod"
|
||||||
|
else True
|
||||||
)
|
)
|
||||||
|
log_format = (
|
||||||
|
"<green>{time:YYYY-MM-DD HH:mm:ss.SSS}</green> "
|
||||||
|
"<fg #777777>|</> <level>{level: <7}</level> "
|
||||||
|
"<fg #777777>|</> <cyan>{name:.<8}</cyan>:<cyan>{function:.<8}</cyan>:<cyan>{line: >4}</cyan> "
|
||||||
|
"<fg #777777>-</> <level>{message}</level>"
|
||||||
|
)
|
||||||
|
|
||||||
|
# 日志文件储存至/logs
|
||||||
|
logger.add(
|
||||||
|
os.path.join(log_path, "maimbot_{time:YYYY-MM-DD}.log"),
|
||||||
|
rotation="00:00",
|
||||||
|
retention="30 days",
|
||||||
|
format=log_format,
|
||||||
|
colorize=False,
|
||||||
|
level=log_level,
|
||||||
|
filter=log_filter,
|
||||||
|
encoding="utf-8",
|
||||||
|
)
|
||||||
|
|
||||||
|
# 终端输出
|
||||||
|
logger.add(sys.stderr, format=log_format, colorize=True, level=log_level, filter=log_filter)
|
||||||
|
|
||||||
|
|
||||||
def scan_provider(env_config: dict):
|
def scan_provider(env_config: dict):
|
||||||
@@ -131,24 +161,53 @@ def scan_provider(env_config: dict):
|
|||||||
# 检查每个 provider 是否同时存在 url 和 key
|
# 检查每个 provider 是否同时存在 url 和 key
|
||||||
for provider_name, config in provider.items():
|
for provider_name, config in provider.items():
|
||||||
if config["url"] is None or config["key"] is None:
|
if config["url"] is None or config["key"] is None:
|
||||||
logger.error(
|
logger.error(f"provider 内容:{config}\nenv_config 内容:{env_config}")
|
||||||
f"provider 内容:{config}\n"
|
|
||||||
f"env_config 内容:{env_config}"
|
|
||||||
)
|
|
||||||
raise ValueError(f"请检查 '{provider_name}' 提供商配置是否丢失 BASE_URL 或 KEY 环境变量")
|
raise ValueError(f"请检查 '{provider_name}' 提供商配置是否丢失 BASE_URL 或 KEY 环境变量")
|
||||||
|
|
||||||
|
|
||||||
if __name__ == "__main__":
|
async def graceful_shutdown():
|
||||||
|
try:
|
||||||
|
global uvicorn_server
|
||||||
|
if uvicorn_server:
|
||||||
|
uvicorn_server.force_exit = True # 强制退出
|
||||||
|
await uvicorn_server.shutdown()
|
||||||
|
|
||||||
|
tasks = [t for t in asyncio.all_tasks() if t is not asyncio.current_task()]
|
||||||
|
for task in tasks:
|
||||||
|
task.cancel()
|
||||||
|
await asyncio.gather(*tasks, return_exceptions=True)
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"麦麦关闭失败: {e}")
|
||||||
|
|
||||||
|
|
||||||
|
async def uvicorn_main():
|
||||||
|
global uvicorn_server
|
||||||
|
config = uvicorn.Config(
|
||||||
|
app="__main__:app",
|
||||||
|
host=os.getenv("HOST", "127.0.0.1"),
|
||||||
|
port=int(os.getenv("PORT", 8080)),
|
||||||
|
reload=os.getenv("ENVIRONMENT") == "dev",
|
||||||
|
timeout_graceful_shutdown=5,
|
||||||
|
log_config=None,
|
||||||
|
access_log=False,
|
||||||
|
)
|
||||||
|
server = uvicorn.Server(config)
|
||||||
|
uvicorn_server = server
|
||||||
|
await server.serve()
|
||||||
|
|
||||||
|
|
||||||
|
def raw_main():
|
||||||
# 利用 TZ 环境变量设定程序工作的时区
|
# 利用 TZ 环境变量设定程序工作的时区
|
||||||
# 仅保证行为一致,不依赖 localtime(),实际对生产环境几乎没有作用
|
# 仅保证行为一致,不依赖 localtime(),实际对生产环境几乎没有作用
|
||||||
if platform.system().lower() != 'windows':
|
if platform.system().lower() != "windows":
|
||||||
time.tzset()
|
time.tzset()
|
||||||
|
|
||||||
easter_egg()
|
easter_egg()
|
||||||
load_logger()
|
|
||||||
init_config()
|
init_config()
|
||||||
init_env()
|
init_env()
|
||||||
load_env()
|
load_env()
|
||||||
|
load_logger()
|
||||||
|
|
||||||
env_config = {key: os.getenv(key) for key in os.environ}
|
env_config = {key: os.getenv(key) for key in os.environ}
|
||||||
scan_provider(env_config)
|
scan_provider(env_config)
|
||||||
@@ -164,10 +223,29 @@ if __name__ == "__main__":
|
|||||||
nonebot.init(**base_config, **env_config)
|
nonebot.init(**base_config, **env_config)
|
||||||
|
|
||||||
# 注册适配器
|
# 注册适配器
|
||||||
|
global driver
|
||||||
driver = nonebot.get_driver()
|
driver = nonebot.get_driver()
|
||||||
driver.register_adapter(Adapter)
|
driver.register_adapter(Adapter)
|
||||||
|
|
||||||
# 加载插件
|
# 加载插件
|
||||||
nonebot.load_plugins("src/plugins")
|
nonebot.load_plugins("src/plugins")
|
||||||
|
|
||||||
nonebot.run()
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
try:
|
||||||
|
raw_main()
|
||||||
|
|
||||||
|
global app
|
||||||
|
app = nonebot.get_asgi()
|
||||||
|
|
||||||
|
loop = asyncio.new_event_loop()
|
||||||
|
asyncio.set_event_loop(loop)
|
||||||
|
loop.run_until_complete(uvicorn_main())
|
||||||
|
except KeyboardInterrupt:
|
||||||
|
logger.warning("麦麦会努力做的更好的!正在停止中......")
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"主程序异常: {e}")
|
||||||
|
finally:
|
||||||
|
loop.run_until_complete(graceful_shutdown())
|
||||||
|
loop.close()
|
||||||
|
logger.info("进程终止完毕,麦麦开始休眠......下次再见哦!")
|
||||||
|
|||||||
84
changelog.md
@@ -1,6 +1,84 @@
|
|||||||
# Changelog
|
# Changelog
|
||||||
|
|
||||||
## [0.5.12] - 2025-3-9
|
## [0.5.13] - 2025-3-12
|
||||||
### Added
|
AI总结
|
||||||
- 新增了 我是测试
|
### 🌟 核心功能增强
|
||||||
|
#### 记忆系统升级
|
||||||
|
- 新增了记忆系统的时间戳功能,包括创建时间和最后修改时间
|
||||||
|
- 新增了记忆图节点和边的时间追踪功能
|
||||||
|
- 新增了自动补充缺失时间字段的功能
|
||||||
|
- 新增了记忆遗忘机制,基于时间条件自动遗忘旧记忆
|
||||||
|
- 优化了记忆系统的数据同步机制
|
||||||
|
- 优化了记忆系统的数据结构,确保所有数据类型的一致性
|
||||||
|
|
||||||
|
#### 私聊功能完善
|
||||||
|
- 新增了完整的私聊功能支持,包括消息处理和回复
|
||||||
|
- 新增了聊天流管理器,支持群聊和私聊的上下文管理
|
||||||
|
- 新增了私聊过滤开关功能
|
||||||
|
- 优化了关系管理系统,支持跨平台用户关系
|
||||||
|
|
||||||
|
#### 消息处理升级
|
||||||
|
- 新增了消息队列管理系统,支持按时间顺序处理消息
|
||||||
|
- 新增了消息发送控制器,实现人性化的发送速度和间隔
|
||||||
|
- 新增了JSON格式分享卡片读取支持
|
||||||
|
- 新增了Base64格式表情包CQ码支持
|
||||||
|
- 改进了消息处理流程,支持多种消息类型
|
||||||
|
|
||||||
|
### 💻 系统架构优化
|
||||||
|
#### 配置系统改进
|
||||||
|
- 新增了配置文件自动更新和版本检测功能
|
||||||
|
- 新增了配置文件热重载API接口
|
||||||
|
- 新增了配置文件版本兼容性检查
|
||||||
|
- 新增了根据不同环境(dev/prod)显示不同级别的日志功能
|
||||||
|
- 优化了配置文件格式和结构
|
||||||
|
|
||||||
|
#### 部署支持扩展
|
||||||
|
- 新增了Linux系统部署指南
|
||||||
|
- 新增了Docker部署支持的详细文档
|
||||||
|
- 新增了NixOS环境支持(使用venv方式)
|
||||||
|
- 新增了优雅的shutdown机制
|
||||||
|
- 优化了Docker部署文档
|
||||||
|
|
||||||
|
### 🛠️ 开发体验提升
|
||||||
|
#### 工具链升级
|
||||||
|
- 新增了ruff代码格式化和检查工具
|
||||||
|
- 新增了知识库一键启动脚本
|
||||||
|
- 新增了自动保存脚本,定期保存聊天记录和关系数据
|
||||||
|
- 新增了表情包自动获取脚本
|
||||||
|
- 优化了日志记录(使用logger.debug替代print)
|
||||||
|
- 精简了日志输出,禁用了Uvicorn/NoneBot默认日志
|
||||||
|
|
||||||
|
#### 安全性强化
|
||||||
|
- 新增了API密钥安全管理机制
|
||||||
|
- 新增了数据库完整性检查功能
|
||||||
|
- 新增了表情包文件完整性自动检查
|
||||||
|
- 新增了异常处理和自动恢复机制
|
||||||
|
- 优化了安全性检查机制
|
||||||
|
|
||||||
|
### 🐛 关键问题修复
|
||||||
|
#### 系统稳定性
|
||||||
|
- 修复了systemctl强制停止的问题
|
||||||
|
- 修复了ENVIRONMENT变量在同一终端下不能被覆盖的问题
|
||||||
|
- 修复了libc++.so依赖问题
|
||||||
|
- 修复了数据库索引创建失败的问题
|
||||||
|
- 修复了MongoDB连接配置相关问题
|
||||||
|
- 修复了消息队列溢出问题
|
||||||
|
- 修复了配置文件加载时的版本兼容性问题
|
||||||
|
|
||||||
|
#### 功能完善性
|
||||||
|
- 修复了私聊时产生reply消息的bug
|
||||||
|
- 修复了回复消息无法识别的问题
|
||||||
|
- 修复了CQ码解析错误
|
||||||
|
- 修复了情绪管理器导入问题
|
||||||
|
- 修复了小名无效的问题
|
||||||
|
- 修复了表情包发送时的参数缺失问题
|
||||||
|
- 修复了表情包重复注册问题
|
||||||
|
- 修复了变量拼写错误问题
|
||||||
|
|
||||||
|
### 主要改进方向
|
||||||
|
1. 提升记忆系统的智能性和可靠性
|
||||||
|
2. 完善私聊功能的完整生态
|
||||||
|
3. 优化系统架构和部署便利性
|
||||||
|
4. 提升开发体验和代码质量
|
||||||
|
5. 加强系统安全性和稳定性
|
||||||
|
|
||||||
|
|||||||
@@ -1,6 +1,12 @@
|
|||||||
# Changelog
|
# Changelog
|
||||||
|
|
||||||
|
## [0.0.5] - 2025-3-11
|
||||||
|
### Added
|
||||||
|
- 新增了 `alias_names` 配置项,用于指定麦麦的别名。
|
||||||
|
|
||||||
## [0.0.4] - 2025-3-9
|
## [0.0.4] - 2025-3-9
|
||||||
### Added
|
### Added
|
||||||
- 新增了 `memory_ban_words` 配置项,用于指定不希望记忆的词汇。
|
- 新增了 `memory_ban_words` 配置项,用于指定不希望记忆的词汇。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
59
config/auto_update.py
Normal file
@@ -0,0 +1,59 @@
|
|||||||
|
import os
|
||||||
|
import shutil
|
||||||
|
import tomlkit
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
def update_config():
|
||||||
|
# 获取根目录路径
|
||||||
|
root_dir = Path(__file__).parent.parent
|
||||||
|
template_dir = root_dir / "template"
|
||||||
|
config_dir = root_dir / "config"
|
||||||
|
|
||||||
|
# 定义文件路径
|
||||||
|
template_path = template_dir / "bot_config_template.toml"
|
||||||
|
old_config_path = config_dir / "bot_config.toml"
|
||||||
|
new_config_path = config_dir / "bot_config.toml"
|
||||||
|
|
||||||
|
# 读取旧配置文件
|
||||||
|
old_config = {}
|
||||||
|
if old_config_path.exists():
|
||||||
|
with open(old_config_path, "r", encoding="utf-8") as f:
|
||||||
|
old_config = tomlkit.load(f)
|
||||||
|
|
||||||
|
# 删除旧的配置文件
|
||||||
|
if old_config_path.exists():
|
||||||
|
os.remove(old_config_path)
|
||||||
|
|
||||||
|
# 复制模板文件到配置目录
|
||||||
|
shutil.copy2(template_path, new_config_path)
|
||||||
|
|
||||||
|
# 读取新配置文件
|
||||||
|
with open(new_config_path, "r", encoding="utf-8") as f:
|
||||||
|
new_config = tomlkit.load(f)
|
||||||
|
|
||||||
|
# 递归更新配置
|
||||||
|
def update_dict(target, source):
|
||||||
|
for key, value in source.items():
|
||||||
|
# 跳过version字段的更新
|
||||||
|
if key == "version":
|
||||||
|
continue
|
||||||
|
if key in target:
|
||||||
|
if isinstance(value, dict) and isinstance(target[key], (dict, tomlkit.items.Table)):
|
||||||
|
update_dict(target[key], value)
|
||||||
|
else:
|
||||||
|
try:
|
||||||
|
# 直接使用tomlkit的item方法创建新值
|
||||||
|
target[key] = tomlkit.item(value)
|
||||||
|
except (TypeError, ValueError):
|
||||||
|
# 如果转换失败,直接赋值
|
||||||
|
target[key] = value
|
||||||
|
|
||||||
|
# 将旧配置的值更新到新配置中
|
||||||
|
update_dict(new_config, old_config)
|
||||||
|
|
||||||
|
# 保存更新后的配置(保留注释和格式)
|
||||||
|
with open(new_config_path, "w", encoding="utf-8") as f:
|
||||||
|
f.write(tomlkit.dumps(new_config))
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
update_config()
|
||||||
@@ -6,8 +6,6 @@ services:
|
|||||||
- NAPCAT_UID=${NAPCAT_UID}
|
- NAPCAT_UID=${NAPCAT_UID}
|
||||||
- NAPCAT_GID=${NAPCAT_GID} # 让 NapCat 获取当前用户 GID,UID,防止权限问题
|
- NAPCAT_GID=${NAPCAT_GID} # 让 NapCat 获取当前用户 GID,UID,防止权限问题
|
||||||
ports:
|
ports:
|
||||||
- 3000:3000
|
|
||||||
- 3001:3001
|
|
||||||
- 6099:6099
|
- 6099:6099
|
||||||
restart: unless-stopped
|
restart: unless-stopped
|
||||||
volumes:
|
volumes:
|
||||||
@@ -19,7 +17,7 @@ services:
|
|||||||
mongodb:
|
mongodb:
|
||||||
container_name: mongodb
|
container_name: mongodb
|
||||||
environment:
|
environment:
|
||||||
- tz=Asia/Shanghai
|
- TZ=Asia/Shanghai
|
||||||
# - MONGO_INITDB_ROOT_USERNAME=your_username
|
# - MONGO_INITDB_ROOT_USERNAME=your_username
|
||||||
# - MONGO_INITDB_ROOT_PASSWORD=your_password
|
# - MONGO_INITDB_ROOT_PASSWORD=your_password
|
||||||
expose:
|
expose:
|
||||||
|
|||||||
BIN
docs/API_KEY.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 47 KiB |
20
docs/Jonathan R.md
Normal file
@@ -0,0 +1,20 @@
|
|||||||
|
Jonathan R. Wolpaw 在 “Memory in neuroscience: rhetoric versus reality.” 一文中提到,从神经科学的感觉运动假设出发,整个神经系统的功能是将经验与适当的行为联系起来,而不是单纯的信息存储。
|
||||||
|
Jonathan R,Wolpaw. (2019). Memory in neuroscience: rhetoric versus reality.. Behavioral and cognitive neuroscience reviews(2).
|
||||||
|
|
||||||
|
1. **单一过程理论**
|
||||||
|
- 单一过程理论认为,识别记忆主要是基于熟悉性这一单一因素的影响。熟悉性是指对刺激的一种自动的、无意识的感知,它可以使我们在没有回忆起具体细节的情况下,判断一个刺激是否曾经出现过。
|
||||||
|
- 例如,在一些实验中,研究者发现被试可以在没有回忆起具体学习情境的情况下,对曾经出现过的刺激做出正确的判断,这被认为是熟悉性在起作用1。
|
||||||
|
2. **双重过程理论**
|
||||||
|
- 双重过程理论则认为,识别记忆是基于两个过程:回忆和熟悉性。回忆是指对过去经验的有意识的回忆,它可以使我们回忆起具体的细节和情境;熟悉性则是一种自动的、无意识的感知。
|
||||||
|
- 该理论认为,在识别记忆中,回忆和熟悉性共同作用,使我们能够判断一个刺激是否曾经出现过。例如,在 “记得 / 知道” 范式中,被试被要求判断他们对一个刺激的记忆是基于回忆还是熟悉性。研究发现,被试可以区分这两种不同的记忆过程,这为双重过程理论提供了支持1。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
1. **神经元节点与连接**:借鉴神经网络原理,将每个记忆单元视为一个神经元节点。节点之间通过连接相互关联,连接的强度代表记忆之间的关联程度。在形态学联想记忆中,具有相似形态特征的记忆节点连接强度较高。例如,苹果和橘子的记忆节点,由于在形状、都是水果等形态语义特征上相似,它们之间的连接强度大于苹果与汽车记忆节点间的连接强度。
|
||||||
|
2. **记忆聚类与层次结构**:依据形态特征的相似性对记忆进行聚类,形成不同的记忆簇。每个记忆簇内部的记忆具有较高的相似性,而不同记忆簇之间的记忆相似性较低。同时,构建记忆的层次结构,高层次的记忆节点代表更抽象、概括的概念,低层次的记忆节点对应具体的实例。比如,“水果” 作为高层次记忆节点,连接着 “苹果”“橘子”“香蕉” 等低层次具体水果的记忆节点。
|
||||||
|
3. **网络的动态更新**:随着新记忆的不断加入,记忆网络动态调整。新记忆节点根据其形态特征与现有网络中的节点建立连接,同时影响相关连接的强度。若新记忆与某个记忆簇的特征高度相似,则被纳入该记忆簇;若具有独特特征,则可能引发新的记忆簇的形成。例如,当系统学习到一种新的水果 “番石榴”,它会根据番石榴的形态、语义等特征,在记忆网络中找到与之最相似的区域(如水果记忆簇),并建立相应连接,同时调整周围节点连接强度以适应这一新记忆。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
- **相似性联想**:该理论认为,当两个或多个事物在形态上具有相似性时,它们在记忆中会形成关联。例如,梨和苹果在形状和都是水果这一属性上有相似性,所以当我们看到梨时,很容易通过形态学联想记忆联想到苹果。这种相似性联想有助于我们对新事物进行分类和理解,当遇到一个新的类似水果时,我们可以通过与已有的水果记忆进行相似性匹配,来推测它的一些特征。
|
||||||
|
- **时空关联性联想**:除了相似性联想,MAM 还强调时空关联性联想。如果两个事物在时间或空间上经常同时出现,它们也会在记忆中形成关联。比如,每次在公园里看到花的时候,都能听到鸟儿的叫声,那么花和鸟儿叫声的形态特征(花的视觉形态和鸟叫的听觉形态)就会在记忆中形成关联,以后听到鸟叫可能就会联想到公园里的花。
|
||||||
BIN
docs/MONGO_DB_0.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 13 KiB |
BIN
docs/MONGO_DB_1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 27 KiB |
BIN
docs/MONGO_DB_2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 31 KiB |
BIN
docs/avatars/SengokuCola.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
BIN
docs/avatars/default.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 36 KiB |
1
docs/avatars/run.bat
Normal file
@@ -0,0 +1 @@
|
|||||||
|
gource gource.log --user-image-dir docs/avatars/ --default-user-image docs/avatars/default.png
|
||||||
@@ -1,6 +1,7 @@
|
|||||||
# 📂 文件及功能介绍 (2025年更新)
|
# 📂 文件及功能介绍 (2025年更新)
|
||||||
|
|
||||||
## 根目录
|
## 根目录
|
||||||
|
|
||||||
- **README.md**: 项目的概述和使用说明。
|
- **README.md**: 项目的概述和使用说明。
|
||||||
- **requirements.txt**: 项目所需的Python依赖包列表。
|
- **requirements.txt**: 项目所需的Python依赖包列表。
|
||||||
- **bot.py**: 主启动文件,负责环境配置加载和NoneBot初始化。
|
- **bot.py**: 主启动文件,负责环境配置加载和NoneBot初始化。
|
||||||
@@ -10,6 +11,7 @@
|
|||||||
- **run_*.bat**: 各种启动脚本,包括数据库、maimai和thinking功能。
|
- **run_*.bat**: 各种启动脚本,包括数据库、maimai和thinking功能。
|
||||||
|
|
||||||
## `src/` 目录结构
|
## `src/` 目录结构
|
||||||
|
|
||||||
- **`plugins/` 目录**: 存放不同功能模块的插件。
|
- **`plugins/` 目录**: 存放不同功能模块的插件。
|
||||||
- **chat/**: 处理聊天相关的功能,如消息发送和接收。
|
- **chat/**: 处理聊天相关的功能,如消息发送和接收。
|
||||||
- **memory_system/**: 处理机器人的记忆功能。
|
- **memory_system/**: 处理机器人的记忆功能。
|
||||||
@@ -22,9 +24,10 @@
|
|||||||
|
|
||||||
- **`common/` 目录**: 存放通用的工具和库。
|
- **`common/` 目录**: 存放通用的工具和库。
|
||||||
- **database.py**: 处理与数据库的交互,负责数据的存储和检索。
|
- **database.py**: 处理与数据库的交互,负责数据的存储和检索。
|
||||||
- **__init__.py**: 初始化模块。
|
- ****init**.py**: 初始化模块。
|
||||||
|
|
||||||
## `config/` 目录
|
## `config/` 目录
|
||||||
|
|
||||||
- **bot_config_template.toml**: 机器人配置模板。
|
- **bot_config_template.toml**: 机器人配置模板。
|
||||||
- **auto_format.py**: 自动格式化工具。
|
- **auto_format.py**: 自动格式化工具。
|
||||||
|
|
||||||
@@ -110,6 +113,7 @@
|
|||||||
## 消息处理流程
|
## 消息处理流程
|
||||||
|
|
||||||
### 1. 消息接收与预处理
|
### 1. 消息接收与预处理
|
||||||
|
|
||||||
- 通过 `ChatBot.handle_message()` 接收群消息。
|
- 通过 `ChatBot.handle_message()` 接收群消息。
|
||||||
- 进行用户和群组的权限检查。
|
- 进行用户和群组的权限检查。
|
||||||
- 更新用户关系信息。
|
- 更新用户关系信息。
|
||||||
@@ -117,12 +121,14 @@
|
|||||||
- 对消息进行过滤和敏感词检测。
|
- 对消息进行过滤和敏感词检测。
|
||||||
|
|
||||||
### 2. 主题识别与决策
|
### 2. 主题识别与决策
|
||||||
|
|
||||||
- 使用 `topic_identifier` 识别消息主题。
|
- 使用 `topic_identifier` 识别消息主题。
|
||||||
- 通过记忆系统检查对主题的兴趣度。
|
- 通过记忆系统检查对主题的兴趣度。
|
||||||
- `willing_manager` 动态计算回复概率。
|
- `willing_manager` 动态计算回复概率。
|
||||||
- 根据概率决定是否回复消息。
|
- 根据概率决定是否回复消息。
|
||||||
|
|
||||||
### 3. 回复生成与发送
|
### 3. 回复生成与发送
|
||||||
|
|
||||||
- 如需回复,首先创建 `Message_Thinking` 对象表示思考状态。
|
- 如需回复,首先创建 `Message_Thinking` 对象表示思考状态。
|
||||||
- 调用 `ResponseGenerator.generate_response()` 生成回复内容和情感状态。
|
- 调用 `ResponseGenerator.generate_response()` 生成回复内容和情感状态。
|
||||||
- 删除思考消息,创建 `MessageSet` 准备发送回复。
|
- 删除思考消息,创建 `MessageSet` 准备发送回复。
|
||||||
|
|||||||
@@ -1,64 +1,90 @@
|
|||||||
# 🐳 Docker 部署指南
|
# 🐳 Docker 部署指南
|
||||||
|
|
||||||
## 部署步骤(推荐,但不一定是最新)
|
## 部署步骤 (推荐,但不一定是最新)
|
||||||
|
|
||||||
|
**"更新镜像与容器"部分在本文档 [Part 6](#6-更新镜像与容器)**
|
||||||
|
|
||||||
|
### 0. 前提说明
|
||||||
|
|
||||||
|
**本文假设读者已具备一定的 Docker 基础知识。若您对 Docker 不熟悉,建议先参考相关教程或文档进行学习,或选择使用 [📦Linux手动部署指南](./manual_deploy_linux.md) 或 [📦Windows手动部署指南](./manual_deploy_windows.md) 。**
|
||||||
|
|
||||||
|
|
||||||
### 1. 获取Docker配置文件:
|
### 1. 获取Docker配置文件
|
||||||
|
|
||||||
|
- 建议先单独创建好一个文件夹并进入,作为工作目录
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
wget https://raw.githubusercontent.com/SengokuCola/MaiMBot/main/docker-compose.yml -O docker-compose.yml
|
wget https://raw.githubusercontent.com/SengokuCola/MaiMBot/main/docker-compose.yml -O docker-compose.yml
|
||||||
```
|
```
|
||||||
|
|
||||||
- 若需要启用MongoDB数据库的用户名和密码,可进入docker-compose.yml,取消MongoDB处的注释并修改变量`=`后方的值为你的用户名和密码\
|
- 若需要启用MongoDB数据库的用户名和密码,可进入docker-compose.yml,取消MongoDB处的注释并修改变量旁 `=` 后方的值为你的用户名和密码\
|
||||||
修改后请注意在之后配置`.env.prod`文件时指定MongoDB数据库的用户名密码
|
修改后请注意在之后配置 `.env.prod` 文件时指定MongoDB数据库的用户名密码
|
||||||
|
|
||||||
|
### 2. 启动服务
|
||||||
|
|
||||||
### 2. 启动服务:
|
- **!!! 请在第一次启动前确保当前工作目录下 `.env.prod` 与 `bot_config.toml` 文件存在 !!!**\
|
||||||
|
|
||||||
- **!!! 请在第一次启动前确保当前工作目录下`.env.prod`与`bot_config.toml`文件存在 !!!**\
|
|
||||||
由于Docker文件映射行为的特殊性,若宿主机的映射路径不存在,可能导致意外的目录创建,而不会创建文件,由于此处需要文件映射到文件,需提前确保文件存在且路径正确,可使用如下命令:
|
由于Docker文件映射行为的特殊性,若宿主机的映射路径不存在,可能导致意外的目录创建,而不会创建文件,由于此处需要文件映射到文件,需提前确保文件存在且路径正确,可使用如下命令:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
touch .env.prod
|
touch .env.prod
|
||||||
touch bot_config.toml
|
touch bot_config.toml
|
||||||
```
|
```
|
||||||
|
|
||||||
- 启动Docker容器:
|
- 启动Docker容器:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
NAPCAT_UID=$(id -u) NAPCAT_GID=$(id -g) docker compose up -d
|
NAPCAT_UID=$(id -u) NAPCAT_GID=$(id -g) docker compose up -d
|
||||||
|
# 旧版Docker中可能找不到docker compose,请使用docker-compose工具替代
|
||||||
|
NAPCAT_UID=$(id -u) NAPCAT_GID=$(id -g) docker-compose up -d
|
||||||
```
|
```
|
||||||
|
|
||||||
- 旧版Docker中可能找不到docker compose,请使用docker-compose工具替代
|
|
||||||
|
|
||||||
|
### 3. 修改配置并重启Docker
|
||||||
### 3. 修改配置并重启Docker:
|
|
||||||
|
|
||||||
- 请前往 [🎀 新手配置指南](docs/installation_cute.md) 或 [⚙️ 标准配置指南](docs/installation_standard.md) 完成`.env.prod`与`bot_config.toml`配置文件的编写\
|
- 请前往 [🎀 新手配置指南](docs/installation_cute.md) 或 [⚙️ 标准配置指南](docs/installation_standard.md) 完成`.env.prod`与`bot_config.toml`配置文件的编写\
|
||||||
**需要注意`.env.prod`中HOST处IP的填写,Docker中部署和系统中直接安装的配置会有所不同**
|
**需要注意`.env.prod`中HOST处IP的填写,Docker中部署和系统中直接安装的配置会有所不同**
|
||||||
|
|
||||||
- 重启Docker容器:
|
- 重启Docker容器:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
docker restart maimbot # 若修改过容器名称则替换maimbot为你自定的名臣
|
docker restart maimbot # 若修改过容器名称则替换maimbot为你自定的名称
|
||||||
```
|
```
|
||||||
|
|
||||||
- 下方命令可以但不推荐,只是同时重启NapCat、MongoDB、MaiMBot三个服务
|
- 下方命令可以但不推荐,只是同时重启NapCat、MongoDB、MaiMBot三个服务
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
NAPCAT_UID=$(id -u) NAPCAT_GID=$(id -g) docker compose restart
|
NAPCAT_UID=$(id -u) NAPCAT_GID=$(id -g) docker compose restart
|
||||||
|
# 旧版Docker中可能找不到docker compose,请使用docker-compose工具替代
|
||||||
|
NAPCAT_UID=$(id -u) NAPCAT_GID=$(id -g) docker-compose restart
|
||||||
```
|
```
|
||||||
|
|
||||||
- 旧版Docker中可能找不到docker compose,请使用docker-compose工具替代
|
|
||||||
|
|
||||||
|
|
||||||
### 4. 登入NapCat管理页添加反向WebSocket
|
### 4. 登入NapCat管理页添加反向WebSocket
|
||||||
|
|
||||||
- 在浏览器地址栏输入`http://<宿主机IP>:6099/`进入NapCat的管理Web页,添加一个Websocket客户端
|
- 在浏览器地址栏输入 `http://<宿主机IP>:6099/` 进入NapCat的管理Web页,添加一个Websocket客户端
|
||||||
|
|
||||||
> 网络配置 -> 新建 -> Websocket客户端
|
> 网络配置 -> 新建 -> Websocket客户端
|
||||||
|
|
||||||
- Websocket客户端的名称自定,URL栏填入`ws://maimbot:8080/onebot/v11/ws`,启用并保存即可\
|
- Websocket客户端的名称自定,URL栏填入 `ws://maimbot:8080/onebot/v11/ws`,启用并保存即可\
|
||||||
(若修改过容器名称则替换maimbot为你自定的名称)
|
(若修改过容器名称则替换maimbot为你自定的名称)
|
||||||
|
|
||||||
|
### 5. 部署完成,愉快地和麦麦对话吧!
|
||||||
|
|
||||||
### 5. 愉快地和麦麦对话吧!
|
|
||||||
|
|
||||||
|
### 6. 更新镜像与容器
|
||||||
|
|
||||||
|
- 拉取最新镜像
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker-compose pull
|
||||||
|
```
|
||||||
|
|
||||||
|
- 执行启动容器指令,该指令会自动重建镜像有更新的容器并启动
|
||||||
|
|
||||||
|
```bash
|
||||||
|
NAPCAT_UID=$(id -u) NAPCAT_GID=$(id -g) docker compose up -d
|
||||||
|
# 旧版Docker中可能找不到docker compose,请使用docker-compose工具替代
|
||||||
|
NAPCAT_UID=$(id -u) NAPCAT_GID=$(id -g) docker-compose up -d
|
||||||
|
```
|
||||||
|
|
||||||
## ⚠️ 注意事项
|
## ⚠️ 注意事项
|
||||||
|
|
||||||
|
|||||||
149
docs/fast_q_a.md
Normal file
@@ -0,0 +1,149 @@
|
|||||||
|
## 快速更新Q&A❓
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
- 这个文件用来记录一些常见的新手问题。
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
### 完整安装教程
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
[MaiMbot简易配置教程](https://www.bilibili.com/video/BV1zsQ5YCEE6)
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
### Api相关问题
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
- 为什么显示:"缺失必要的API KEY" ❓
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
|
||||||
|
<img src="API_KEY.png" width=650>
|
||||||
|
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
><br>
|
||||||
|
>
|
||||||
|
>你需要在 [Silicon Flow Api](https://cloud.siliconflow.cn/account/ak)
|
||||||
|
>网站上注册一个账号,然后点击这个链接打开API KEY获取页面。
|
||||||
|
>
|
||||||
|
>点击 "新建API密钥" 按钮新建一个给MaiMBot使用的API KEY。不要忘了点击复制。
|
||||||
|
>
|
||||||
|
>之后打开MaiMBot在你电脑上的文件根目录,使用记事本或者其他文本编辑器打开 [.env.prod](../.env.prod)
|
||||||
|
>这个文件。把你刚才复制的API KEY填入到 "SILICONFLOW_KEY=" 这个等号的右边。
|
||||||
|
>
|
||||||
|
>在默认情况下,MaiMBot使用的默认Api都是硅基流动的。
|
||||||
|
>
|
||||||
|
><br>
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
|
||||||
|
- 我想使用硅基流动之外的Api网站,我应该怎么做 ❓
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
><br>
|
||||||
|
>
|
||||||
|
>你需要使用记事本或者其他文本编辑器打开config目录下的 [bot_config.toml](../config/bot_config.toml)
|
||||||
|
>然后修改其中的 "provider = " 字段。同时不要忘记模仿 [.env.prod](../.env.prod)
|
||||||
|
>文件的写法添加 Api Key 和 Base URL。
|
||||||
|
>
|
||||||
|
>举个例子,如果你写了 " provider = \"ABC\" ",那你需要相应的在 [.env.prod](../.env.prod)
|
||||||
|
>文件里添加形如 " ABC_BASE_URL = https://api.abc.com/v1 " 和 " ABC_KEY = sk-1145141919810 " 的字段。
|
||||||
|
>
|
||||||
|
>**如果你对AI没有较深的了解,修改识图模型和嵌入模型的provider字段可能会产生bug,因为你从Api网站调用了一个并不存在的模型**
|
||||||
|
>
|
||||||
|
>这个时候,你需要把字段的值改回 "provider = \"SILICONFLOW\" " 以此解决bug。
|
||||||
|
>
|
||||||
|
><br>
|
||||||
|
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
### MongoDB相关问题
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
- 我应该怎么清空bot内存储的表情包 ❓
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
><br>
|
||||||
|
>
|
||||||
|
>打开你的MongoDB Compass软件,你会在左上角看到这样的一个界面:
|
||||||
|
>
|
||||||
|
><br>
|
||||||
|
>
|
||||||
|
><img src="MONGO_DB_0.png" width=250>
|
||||||
|
>
|
||||||
|
><br>
|
||||||
|
>
|
||||||
|
>点击 "CONNECT" 之后,点击展开 MegBot 标签栏
|
||||||
|
>
|
||||||
|
><br>
|
||||||
|
>
|
||||||
|
><img src="MONGO_DB_1.png" width=250>
|
||||||
|
>
|
||||||
|
><br>
|
||||||
|
>
|
||||||
|
>点进 "emoji" 再点击 "DELETE" 删掉所有条目,如图所示
|
||||||
|
>
|
||||||
|
><br>
|
||||||
|
>
|
||||||
|
><img src="MONGO_DB_2.png" width=450>
|
||||||
|
>
|
||||||
|
><br>
|
||||||
|
>
|
||||||
|
>你可以用类似的方式手动清空MaiMBot的所有服务器数据。
|
||||||
|
>
|
||||||
|
>MaiMBot的所有图片均储存在 [data](../data) 文件夹内,按类型分为 [emoji](../data/emoji) 和 [image](../data/image)
|
||||||
|
>
|
||||||
|
>在删除服务器数据时不要忘记清空这些图片。
|
||||||
|
>
|
||||||
|
><br>
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
- 为什么我连接不上MongoDB服务器 ❓
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
|
||||||
|
><br>
|
||||||
|
>
|
||||||
|
>这个问题比较复杂,但是你可以按照下面的步骤检查,看看具体是什么问题
|
||||||
|
>
|
||||||
|
><br>
|
||||||
|
>
|
||||||
|
> 1. 检查有没有把 mongod.exe 所在的目录添加到 path。 具体可参照
|
||||||
|
>
|
||||||
|
><br>
|
||||||
|
>
|
||||||
|
>  [CSDN-windows10设置环境变量Path详细步骤](https://blog.csdn.net/flame_007/article/details/106401215)
|
||||||
|
>
|
||||||
|
><br>
|
||||||
|
>
|
||||||
|
>  **需要往path里填入的是 exe 所在的完整目录!不带 exe 本体**
|
||||||
|
>
|
||||||
|
><br>
|
||||||
|
>
|
||||||
|
> 2. 待完成
|
||||||
|
>
|
||||||
|
><br>
|
||||||
@@ -1,8 +1,9 @@
|
|||||||
# 🔧 配置指南 喵~
|
# 🔧 配置指南 喵~
|
||||||
|
|
||||||
## 👋 你好呀!
|
## 👋 你好呀
|
||||||
|
|
||||||
让咱来告诉你我们要做什么喵:
|
让咱来告诉你我们要做什么喵:
|
||||||
|
|
||||||
1. 我们要一起设置一个可爱的AI机器人
|
1. 我们要一起设置一个可爱的AI机器人
|
||||||
2. 这个机器人可以在QQ上陪你聊天玩耍哦
|
2. 这个机器人可以在QQ上陪你聊天玩耍哦
|
||||||
3. 需要设置两个文件才能让机器人工作呢
|
3. 需要设置两个文件才能让机器人工作呢
|
||||||
@@ -10,16 +11,19 @@
|
|||||||
## 📝 需要设置的文件喵
|
## 📝 需要设置的文件喵
|
||||||
|
|
||||||
要设置这两个文件才能让机器人跑起来哦:
|
要设置这两个文件才能让机器人跑起来哦:
|
||||||
|
|
||||||
1. `.env.prod` - 这个文件告诉机器人要用哪些AI服务呢
|
1. `.env.prod` - 这个文件告诉机器人要用哪些AI服务呢
|
||||||
2. `bot_config.toml` - 这个文件教机器人怎么和你聊天喵
|
2. `bot_config.toml` - 这个文件教机器人怎么和你聊天喵
|
||||||
|
|
||||||
## 🔑 密钥和域名的对应关系
|
## 🔑 密钥和域名的对应关系
|
||||||
|
|
||||||
想象一下,你要进入一个游乐园,需要:
|
想象一下,你要进入一个游乐园,需要:
|
||||||
|
|
||||||
1. 知道游乐园的地址(这就是域名 base_url)
|
1. 知道游乐园的地址(这就是域名 base_url)
|
||||||
2. 有入场的门票(这就是密钥 key)
|
2. 有入场的门票(这就是密钥 key)
|
||||||
|
|
||||||
在 `.env.prod` 文件里,我们定义了三个游乐园的地址和门票喵:
|
在 `.env.prod` 文件里,我们定义了三个游乐园的地址和门票喵:
|
||||||
|
|
||||||
```ini
|
```ini
|
||||||
# 硅基流动游乐园
|
# 硅基流动游乐园
|
||||||
SILICONFLOW_KEY=your_key # 硅基流动的门票
|
SILICONFLOW_KEY=your_key # 硅基流动的门票
|
||||||
@@ -35,6 +39,7 @@ CHAT_ANY_WHERE_BASE_URL=https://api.chatanywhere.tech/v1 # ChatAnyWhere的地
|
|||||||
```
|
```
|
||||||
|
|
||||||
然后在 `bot_config.toml` 里,机器人会用这些门票和地址去游乐园玩耍:
|
然后在 `bot_config.toml` 里,机器人会用这些门票和地址去游乐园玩耍:
|
||||||
|
|
||||||
```toml
|
```toml
|
||||||
[model.llm_reasoning]
|
[model.llm_reasoning]
|
||||||
name = "Pro/deepseek-ai/DeepSeek-R1"
|
name = "Pro/deepseek-ai/DeepSeek-R1"
|
||||||
@@ -47,22 +52,24 @@ base_url = "SILICONFLOW_BASE_URL" # 还是去硅基流动游乐园
|
|||||||
key = "SILICONFLOW_KEY" # 用同一张门票就可以啦
|
key = "SILICONFLOW_KEY" # 用同一张门票就可以啦
|
||||||
```
|
```
|
||||||
|
|
||||||
### 🎪 举个例子喵:
|
### 🎪 举个例子喵
|
||||||
|
|
||||||
如果你想用DeepSeek官方的服务,就要这样改:
|
如果你想用DeepSeek官方的服务,就要这样改:
|
||||||
|
|
||||||
```toml
|
```toml
|
||||||
[model.llm_reasoning]
|
[model.llm_reasoning]
|
||||||
name = "Pro/deepseek-ai/DeepSeek-R1"
|
name = "deepseek-reasoner" # 改成对应的模型名称,这里为DeepseekR1
|
||||||
base_url = "DEEP_SEEK_BASE_URL" # 改成去DeepSeek游乐园
|
base_url = "DEEP_SEEK_BASE_URL" # 改成去DeepSeek游乐园
|
||||||
key = "DEEP_SEEK_KEY" # 用DeepSeek的门票
|
key = "DEEP_SEEK_KEY" # 用DeepSeek的门票
|
||||||
|
|
||||||
[model.llm_normal]
|
[model.llm_normal]
|
||||||
name = "Pro/deepseek-ai/DeepSeek-V3"
|
name = "deepseek-chat" # 改成对应的模型名称,这里为DeepseekV3
|
||||||
base_url = "DEEP_SEEK_BASE_URL" # 也去DeepSeek游乐园
|
base_url = "DEEP_SEEK_BASE_URL" # 也去DeepSeek游乐园
|
||||||
key = "DEEP_SEEK_KEY" # 用同一张DeepSeek门票
|
key = "DEEP_SEEK_KEY" # 用同一张DeepSeek门票
|
||||||
```
|
```
|
||||||
|
|
||||||
### 🎯 简单来说:
|
### 🎯 简单来说
|
||||||
|
|
||||||
- `.env.prod` 文件就像是你的票夹,存放着各个游乐园的门票和地址
|
- `.env.prod` 文件就像是你的票夹,存放着各个游乐园的门票和地址
|
||||||
- `bot_config.toml` 就是告诉机器人:用哪张票去哪个游乐园玩
|
- `bot_config.toml` 就是告诉机器人:用哪张票去哪个游乐园玩
|
||||||
- 所有模型都可以用同一个游乐园的票,也可以去不同的游乐园玩耍
|
- 所有模型都可以用同一个游乐园的票,也可以去不同的游乐园玩耍
|
||||||
@@ -88,19 +95,25 @@ CHAT_ANY_WHERE_KEY=your_key
|
|||||||
CHAT_ANY_WHERE_BASE_URL=https://api.chatanywhere.tech/v1
|
CHAT_ANY_WHERE_BASE_URL=https://api.chatanywhere.tech/v1
|
||||||
|
|
||||||
# 如果你不知道这是什么,那么下面这些不用改,保持原样就好啦
|
# 如果你不知道这是什么,那么下面这些不用改,保持原样就好啦
|
||||||
HOST=127.0.0.1 # 如果使用Docker部署,需要改成0.0.0.0喵,不然听不见群友讲话了喵
|
# 如果使用Docker部署,需要改成0.0.0.0喵,不然听不见群友讲话了喵
|
||||||
|
HOST=127.0.0.1
|
||||||
PORT=8080
|
PORT=8080
|
||||||
|
|
||||||
# 这些是数据库设置,一般也不用改呢
|
# 这些是数据库设置,一般也不用改呢
|
||||||
MONGODB_HOST=127.0.0.1 # 如果使用Docker部署,需要改成数据库容器的名字喵,默认是mongodb喵
|
# 如果使用Docker部署,需要把MONGODB_HOST改成数据库容器的名字喵,默认是mongodb喵
|
||||||
|
MONGODB_HOST=127.0.0.1
|
||||||
MONGODB_PORT=27017
|
MONGODB_PORT=27017
|
||||||
DATABASE_NAME=MegBot
|
DATABASE_NAME=MegBot
|
||||||
MONGODB_USERNAME = "" # 如果数据库需要用户名,就在这里填写喵
|
# 数据库认证信息,如果需要认证就取消注释并填写下面三行喵
|
||||||
MONGODB_PASSWORD = "" # 如果数据库需要密码,就在这里填写呢
|
# MONGODB_USERNAME = ""
|
||||||
MONGODB_AUTH_SOURCE = "" # 数据库认证源,一般不用改哦
|
# MONGODB_PASSWORD = ""
|
||||||
|
# MONGODB_AUTH_SOURCE = ""
|
||||||
|
|
||||||
# 插件设置喵
|
# 也可以使用URI连接数据库,取消注释填写在下面这行喵(URI的优先级比上面的高)
|
||||||
PLUGINS=["src2.plugins.chat"] # 这里是机器人的插件列表呢
|
# MONGODB_URI=mongodb://127.0.0.1:27017/MegBot
|
||||||
|
|
||||||
|
# 这里是机器人的插件列表呢
|
||||||
|
PLUGINS=["src2.plugins.chat"]
|
||||||
```
|
```
|
||||||
|
|
||||||
### 第二个文件:机器人配置 (bot_config.toml)
|
### 第二个文件:机器人配置 (bot_config.toml)
|
||||||
@@ -110,7 +123,8 @@ PLUGINS=["src2.plugins.chat"] # 这里是机器人的插件列表呢
|
|||||||
```toml
|
```toml
|
||||||
[bot]
|
[bot]
|
||||||
qq = "把这里改成你的机器人QQ号喵" # 填写你的机器人QQ号
|
qq = "把这里改成你的机器人QQ号喵" # 填写你的机器人QQ号
|
||||||
nickname = "麦麦" # 机器人的名字,你可以改成你喜欢的任何名字哦
|
nickname = "麦麦" # 机器人的名字,你可以改成你喜欢的任何名字哦,建议和机器人QQ名称/群昵称一样哦
|
||||||
|
alias_names = ["小麦", "阿麦"] # 也可以用这个招呼机器人,可以不设置呢
|
||||||
|
|
||||||
[personality]
|
[personality]
|
||||||
# 这里可以设置机器人的性格呢,让它更有趣一些喵
|
# 这里可以设置机器人的性格呢,让它更有趣一些喵
|
||||||
@@ -198,10 +212,12 @@ key = "SILICONFLOW_KEY"
|
|||||||
- `topic`: 负责理解对话主题的能力呢
|
- `topic`: 负责理解对话主题的能力呢
|
||||||
|
|
||||||
## 🌟 小提示
|
## 🌟 小提示
|
||||||
|
|
||||||
- 如果你刚开始使用,建议保持默认配置呢
|
- 如果你刚开始使用,建议保持默认配置呢
|
||||||
- 不同的模型有不同的特长,可以根据需要调整它们的使用比例哦
|
- 不同的模型有不同的特长,可以根据需要调整它们的使用比例哦
|
||||||
|
|
||||||
## 🌟 小贴士喵
|
## 🌟 小贴士喵
|
||||||
|
|
||||||
- 记得要好好保管密钥(key)哦,不要告诉别人呢
|
- 记得要好好保管密钥(key)哦,不要告诉别人呢
|
||||||
- 配置文件要小心修改,改错了机器人可能就不能和你玩了喵
|
- 配置文件要小心修改,改错了机器人可能就不能和你玩了喵
|
||||||
- 如果想让机器人更聪明,可以调整 personality 里的设置呢
|
- 如果想让机器人更聪明,可以调整 personality 里的设置呢
|
||||||
@@ -209,6 +225,7 @@ key = "SILICONFLOW_KEY"
|
|||||||
- QQ群号和QQ号都要用数字填写,不要加引号哦(除了机器人自己的QQ号)
|
- QQ群号和QQ号都要用数字填写,不要加引号哦(除了机器人自己的QQ号)
|
||||||
|
|
||||||
## ⚠️ 注意事项
|
## ⚠️ 注意事项
|
||||||
|
|
||||||
- 这个机器人还在测试中呢,可能会有一些小问题喵
|
- 这个机器人还在测试中呢,可能会有一些小问题喵
|
||||||
- 如果不知道怎么改某个设置,就保持原样不要动它哦~
|
- 如果不知道怎么改某个设置,就保持原样不要动它哦~
|
||||||
- 记得要先有AI服务的密钥,不然机器人就不能和你说话了呢
|
- 记得要先有AI服务的密钥,不然机器人就不能和你说话了呢
|
||||||
|
|||||||
@@ -3,14 +3,16 @@
|
|||||||
## 简介
|
## 简介
|
||||||
|
|
||||||
本项目需要配置两个主要文件:
|
本项目需要配置两个主要文件:
|
||||||
|
|
||||||
1. `.env.prod` - 配置API服务和系统环境
|
1. `.env.prod` - 配置API服务和系统环境
|
||||||
2. `bot_config.toml` - 配置机器人行为和模型
|
2. `bot_config.toml` - 配置机器人行为和模型
|
||||||
|
|
||||||
## API配置说明
|
## API配置说明
|
||||||
|
|
||||||
`.env.prod`和`bot_config.toml`中的API配置关系如下:
|
`.env.prod` 和 `bot_config.toml` 中的API配置关系如下:
|
||||||
|
|
||||||
|
### 在.env.prod中定义API凭证
|
||||||
|
|
||||||
### 在.env.prod中定义API凭证:
|
|
||||||
```ini
|
```ini
|
||||||
# API凭证配置
|
# API凭证配置
|
||||||
SILICONFLOW_KEY=your_key # 硅基流动API密钥
|
SILICONFLOW_KEY=your_key # 硅基流动API密钥
|
||||||
@@ -23,7 +25,8 @@ CHAT_ANY_WHERE_KEY=your_key # ChatAnyWhere API密钥
|
|||||||
CHAT_ANY_WHERE_BASE_URL=https://api.chatanywhere.tech/v1 # ChatAnyWhere API地址
|
CHAT_ANY_WHERE_BASE_URL=https://api.chatanywhere.tech/v1 # ChatAnyWhere API地址
|
||||||
```
|
```
|
||||||
|
|
||||||
### 在bot_config.toml中引用API凭证:
|
### 在bot_config.toml中引用API凭证
|
||||||
|
|
||||||
```toml
|
```toml
|
||||||
[model.llm_reasoning]
|
[model.llm_reasoning]
|
||||||
name = "Pro/deepseek-ai/DeepSeek-R1"
|
name = "Pro/deepseek-ai/DeepSeek-R1"
|
||||||
@@ -32,9 +35,10 @@ key = "SILICONFLOW_KEY" # 引用.env.prod中定义的密钥
|
|||||||
```
|
```
|
||||||
|
|
||||||
如需切换到其他API服务,只需修改引用:
|
如需切换到其他API服务,只需修改引用:
|
||||||
|
|
||||||
```toml
|
```toml
|
||||||
[model.llm_reasoning]
|
[model.llm_reasoning]
|
||||||
name = "Pro/deepseek-ai/DeepSeek-R1"
|
name = "deepseek-reasoner" # 改成对应的模型名称,这里为DeepseekR1
|
||||||
base_url = "DEEP_SEEK_BASE_URL" # 切换为DeepSeek服务
|
base_url = "DEEP_SEEK_BASE_URL" # 切换为DeepSeek服务
|
||||||
key = "DEEP_SEEK_KEY" # 使用DeepSeek密钥
|
key = "DEEP_SEEK_KEY" # 使用DeepSeek密钥
|
||||||
```
|
```
|
||||||
@@ -42,6 +46,7 @@ key = "DEEP_SEEK_KEY" # 使用DeepSeek密钥
|
|||||||
## 配置文件详解
|
## 配置文件详解
|
||||||
|
|
||||||
### 环境配置文件 (.env.prod)
|
### 环境配置文件 (.env.prod)
|
||||||
|
|
||||||
```ini
|
```ini
|
||||||
# API配置
|
# API配置
|
||||||
SILICONFLOW_KEY=your_key
|
SILICONFLOW_KEY=your_key
|
||||||
@@ -52,26 +57,36 @@ CHAT_ANY_WHERE_KEY=your_key
|
|||||||
CHAT_ANY_WHERE_BASE_URL=https://api.chatanywhere.tech/v1
|
CHAT_ANY_WHERE_BASE_URL=https://api.chatanywhere.tech/v1
|
||||||
|
|
||||||
# 服务配置
|
# 服务配置
|
||||||
|
|
||||||
HOST=127.0.0.1 # 如果使用Docker部署,需要改成0.0.0.0,否则QQ消息无法传入
|
HOST=127.0.0.1 # 如果使用Docker部署,需要改成0.0.0.0,否则QQ消息无法传入
|
||||||
PORT=8080
|
PORT=8080 # 与反向端口相同
|
||||||
|
|
||||||
# 数据库配置
|
# 数据库配置
|
||||||
MONGODB_HOST=127.0.0.1 # 如果使用Docker部署,需要改成数据库容器的名字,默认是mongodb
|
MONGODB_HOST=127.0.0.1 # 如果使用Docker部署,需要改成数据库容器的名字,默认是mongodb
|
||||||
MONGODB_PORT=27017
|
MONGODB_PORT=27017 # MongoDB端口
|
||||||
|
|
||||||
DATABASE_NAME=MegBot
|
DATABASE_NAME=MegBot
|
||||||
MONGODB_USERNAME = "" # 数据库用户名
|
# 数据库认证信息,如果需要认证就取消注释并填写下面三行
|
||||||
MONGODB_PASSWORD = "" # 数据库密码
|
# MONGODB_USERNAME = ""
|
||||||
MONGODB_AUTH_SOURCE = "" # 认证数据库
|
# MONGODB_PASSWORD = ""
|
||||||
|
# MONGODB_AUTH_SOURCE = ""
|
||||||
|
|
||||||
|
# 也可以使用URI连接数据库,取消注释填写在下面这行(URI的优先级比上面的高)
|
||||||
|
# MONGODB_URI=mongodb://127.0.0.1:27017/MegBot
|
||||||
|
|
||||||
# 插件配置
|
# 插件配置
|
||||||
PLUGINS=["src2.plugins.chat"]
|
PLUGINS=["src2.plugins.chat"]
|
||||||
```
|
```
|
||||||
|
|
||||||
### 机器人配置文件 (bot_config.toml)
|
### 机器人配置文件 (bot_config.toml)
|
||||||
|
|
||||||
```toml
|
```toml
|
||||||
[bot]
|
[bot]
|
||||||
qq = "机器人QQ号" # 必填
|
qq = "机器人QQ号" # 必填
|
||||||
nickname = "麦麦" # 机器人昵称
|
nickname = "麦麦" # 机器人昵称
|
||||||
|
# alias_names: 配置机器人可使用的别名。当机器人在群聊或对话中被调用时,别名可以作为直接命令或提及机器人的关键字使用。
|
||||||
|
# 该配置项为字符串数组。例如: ["小麦", "阿麦"]
|
||||||
|
alias_names = ["小麦", "阿麦"] # 机器人别名
|
||||||
|
|
||||||
[personality]
|
[personality]
|
||||||
prompt_personality = [
|
prompt_personality = [
|
||||||
|
|||||||
444
docs/linux_deploy_guide_for_beginners.md
Normal file
@@ -0,0 +1,444 @@
|
|||||||
|
# 面向纯新手的Linux服务器麦麦部署指南
|
||||||
|
|
||||||
|
## 你得先有一个服务器
|
||||||
|
|
||||||
|
为了能使麦麦在你的电脑关机之后还能运行,你需要一台不间断开机的主机,也就是我们常说的服务器。
|
||||||
|
|
||||||
|
华为云、阿里云、腾讯云等等都是在国内可以选择的选择。
|
||||||
|
|
||||||
|
你可以去租一台最低配置的就足敷需要了,按月租大概十几块钱就能租到了。
|
||||||
|
|
||||||
|
我们假设你已经租好了一台Linux架构的云服务器。我用的是阿里云ubuntu24.04,其他的原理相似。
|
||||||
|
|
||||||
|
## 0.我们就从零开始吧
|
||||||
|
|
||||||
|
### 网络问题
|
||||||
|
|
||||||
|
为访问github相关界面,推荐去下一款加速器,新手可以试试watttoolkit。
|
||||||
|
|
||||||
|
### 安装包下载
|
||||||
|
|
||||||
|
#### MongoDB
|
||||||
|
|
||||||
|
对于ubuntu24.04 x86来说是这个:
|
||||||
|
|
||||||
|
https://repo.mongodb.org/apt/ubuntu/dists/noble/mongodb-org/8.0/multiverse/binary-amd64/mongodb-org-server_8.0.5_amd64.deb
|
||||||
|
|
||||||
|
如果不是就在这里自行选择对应版本
|
||||||
|
|
||||||
|
https://www.mongodb.com/try/download/community-kubernetes-operator
|
||||||
|
|
||||||
|
#### Napcat
|
||||||
|
|
||||||
|
在这里选择对应版本。
|
||||||
|
|
||||||
|
https://github.com/NapNeko/NapCatQQ/releases/tag/v4.6.7
|
||||||
|
|
||||||
|
对于ubuntu24.04 x86来说是这个:
|
||||||
|
|
||||||
|
https://dldir1.qq.com/qqfile/qq/QQNT/ee4bd910/linuxqq_3.2.16-32793_amd64.deb
|
||||||
|
|
||||||
|
#### 麦麦
|
||||||
|
|
||||||
|
https://github.com/SengokuCola/MaiMBot/archive/refs/tags/0.5.8-alpha.zip
|
||||||
|
|
||||||
|
下载这个官方压缩包。
|
||||||
|
|
||||||
|
### 路径
|
||||||
|
|
||||||
|
我把麦麦相关文件放在了/moi/mai里面,你可以凭喜好更改,记得适当调整下面涉及到的部分即可。
|
||||||
|
|
||||||
|
文件结构:
|
||||||
|
|
||||||
|
```
|
||||||
|
moi
|
||||||
|
└─ mai
|
||||||
|
├─ linuxqq_3.2.16-32793_amd64.deb
|
||||||
|
├─ mongodb-org-server_8.0.5_amd64.deb
|
||||||
|
└─ bot
|
||||||
|
└─ MaiMBot-0.5.8-alpha.zip
|
||||||
|
```
|
||||||
|
|
||||||
|
### 网络
|
||||||
|
|
||||||
|
你可以在你的服务器控制台网页更改防火墙规则,允许6099,8080,27017这几个端口的出入。
|
||||||
|
|
||||||
|
## 1.正式开始!
|
||||||
|
|
||||||
|
远程连接你的服务器,你会看到一个黑框框闪着白方格,这就是我们要进行设置的场所——终端了。以下的bash命令都是在这里输入。
|
||||||
|
|
||||||
|
## 2. Python的安装
|
||||||
|
|
||||||
|
- 导入 Python 的稳定版 PPA:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo add-apt-repository ppa:deadsnakes/ppa
|
||||||
|
```
|
||||||
|
|
||||||
|
- 导入 PPA 后,更新 APT 缓存:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo apt update
|
||||||
|
```
|
||||||
|
|
||||||
|
- 在「终端」中执行以下命令来安装 Python 3.12:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo apt install python3.12
|
||||||
|
```
|
||||||
|
|
||||||
|
- 验证安装是否成功:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python3.12 --version
|
||||||
|
```
|
||||||
|
|
||||||
|
- 在「终端」中,执行以下命令安装 pip:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo apt install python3-pip
|
||||||
|
```
|
||||||
|
|
||||||
|
- 检查Pip是否安装成功:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip --version
|
||||||
|
```
|
||||||
|
|
||||||
|
- 安装必要组件
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
sudo apt install python-is-python3
|
||||||
|
```
|
||||||
|
|
||||||
|
## 3.MongoDB的安装
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
cd /moi/mai
|
||||||
|
```
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
dpkg -i mongodb-org-server_8.0.5_amd64.deb
|
||||||
|
```
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
mkdir -p /root/data/mongodb/{data,log}
|
||||||
|
```
|
||||||
|
|
||||||
|
## 4.MongoDB的运行
|
||||||
|
|
||||||
|
```bash
|
||||||
|
service mongod start
|
||||||
|
```
|
||||||
|
|
||||||
|
```bash
|
||||||
|
systemctl status mongod #通过这条指令检查运行状态
|
||||||
|
```
|
||||||
|
|
||||||
|
有需要的话可以把这个服务注册成开机自启
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo systemctl enable mongod
|
||||||
|
```
|
||||||
|
|
||||||
|
## 5.napcat的安装
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
curl -o napcat.sh https://nclatest.znin.net/NapNeko/NapCat-Installer/main/script/install.sh && sudo bash napcat.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的不行试试下面的
|
||||||
|
|
||||||
|
``` bash
|
||||||
|
dpkg -i linuxqq_3.2.16-32793_amd64.deb
|
||||||
|
apt-get install -f
|
||||||
|
dpkg -i linuxqq_3.2.16-32793_amd64.deb
|
||||||
|
```
|
||||||
|
|
||||||
|
成功的标志是输入``` napcat ```出来炫酷的彩虹色界面
|
||||||
|
|
||||||
|
## 6.napcat的运行
|
||||||
|
|
||||||
|
此时你就可以根据提示在```napcat```里面登录你的QQ号了。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
napcat start <你的QQ号>
|
||||||
|
napcat status #检查运行状态
|
||||||
|
```
|
||||||
|
|
||||||
|
然后你就可以登录napcat的webui进行设置了:
|
||||||
|
|
||||||
|
```http://<你服务器的公网IP>:6099/webui?token=napcat```
|
||||||
|
|
||||||
|
第一次是这个,后续改了密码之后token就会对应修改。你也可以使用```napcat log <你的QQ号>```来查看webui地址。把里面的```127.0.0.1```改成<你服务器的公网IP>即可。
|
||||||
|
|
||||||
|
登录上之后在网络配置界面添加websocket客户端,名称随便输一个,url改成`ws://127.0.0.1:8080/onebot/v11/ws`保存之后点启用,就大功告成了。
|
||||||
|
|
||||||
|
## 7.麦麦的安装
|
||||||
|
|
||||||
|
### step 1 安装解压软件
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt-get install unzip
|
||||||
|
```
|
||||||
|
|
||||||
|
### step 2 解压文件
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cd /moi/mai/bot # 注意:要切换到压缩包的目录中去
|
||||||
|
unzip MaiMBot-0.5.8-alpha.zip
|
||||||
|
```
|
||||||
|
|
||||||
|
### step 3 进入虚拟环境安装库
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cd /moi/mai/bot
|
||||||
|
python -m venv venv
|
||||||
|
source venv/bin/activate
|
||||||
|
pip install -r requirements.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
### step 4 试运行
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cd /moi/mai/bot
|
||||||
|
python -m venv venv
|
||||||
|
source venv/bin/activate
|
||||||
|
python bot.py
|
||||||
|
```
|
||||||
|
|
||||||
|
肯定运行不成功,不过你会发现结束之后多了一些文件
|
||||||
|
|
||||||
|
```
|
||||||
|
bot
|
||||||
|
├─ .env.prod
|
||||||
|
└─ config
|
||||||
|
└─ bot_config.toml
|
||||||
|
```
|
||||||
|
|
||||||
|
你要会vim直接在终端里修改也行,不过也可以把它们下到本地改好再传上去:
|
||||||
|
|
||||||
|
### step 5 文件配置
|
||||||
|
|
||||||
|
本项目需要配置两个主要文件:
|
||||||
|
|
||||||
|
1. `.env.prod` - 配置API服务和系统环境
|
||||||
|
2. `bot_config.toml` - 配置机器人行为和模型
|
||||||
|
|
||||||
|
#### API
|
||||||
|
|
||||||
|
你可以注册一个硅基流动的账号,通过邀请码注册有14块钱的免费额度:https://cloud.siliconflow.cn/i/7Yld7cfg。
|
||||||
|
|
||||||
|
#### 在.env.prod中定义API凭证:
|
||||||
|
|
||||||
|
```
|
||||||
|
# API凭证配置
|
||||||
|
SILICONFLOW_KEY=your_key # 硅基流动API密钥
|
||||||
|
SILICONFLOW_BASE_URL=https://api.siliconflow.cn/v1/ # 硅基流动API地址
|
||||||
|
|
||||||
|
DEEP_SEEK_KEY=your_key # DeepSeek API密钥
|
||||||
|
DEEP_SEEK_BASE_URL=https://api.deepseek.com/v1 # DeepSeek API地址
|
||||||
|
|
||||||
|
CHAT_ANY_WHERE_KEY=your_key # ChatAnyWhere API密钥
|
||||||
|
CHAT_ANY_WHERE_BASE_URL=https://api.chatanywhere.tech/v1 # ChatAnyWhere API地址
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 在bot_config.toml中引用API凭证:
|
||||||
|
|
||||||
|
```
|
||||||
|
[model.llm_reasoning]
|
||||||
|
name = "Pro/deepseek-ai/DeepSeek-R1"
|
||||||
|
base_url = "SILICONFLOW_BASE_URL" # 引用.env.prod中定义的地址
|
||||||
|
key = "SILICONFLOW_KEY" # 引用.env.prod中定义的密钥
|
||||||
|
```
|
||||||
|
|
||||||
|
如需切换到其他API服务,只需修改引用:
|
||||||
|
|
||||||
|
```
|
||||||
|
[model.llm_reasoning]
|
||||||
|
name = "Pro/deepseek-ai/DeepSeek-R1"
|
||||||
|
base_url = "DEEP_SEEK_BASE_URL" # 切换为DeepSeek服务
|
||||||
|
key = "DEEP_SEEK_KEY" # 使用DeepSeek密钥
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 配置文件详解
|
||||||
|
|
||||||
|
##### 环境配置文件 (.env.prod)
|
||||||
|
|
||||||
|
```
|
||||||
|
# API配置
|
||||||
|
SILICONFLOW_KEY=your_key
|
||||||
|
SILICONFLOW_BASE_URL=https://api.siliconflow.cn/v1/
|
||||||
|
DEEP_SEEK_KEY=your_key
|
||||||
|
DEEP_SEEK_BASE_URL=https://api.deepseek.com/v1
|
||||||
|
CHAT_ANY_WHERE_KEY=your_key
|
||||||
|
CHAT_ANY_WHERE_BASE_URL=https://api.chatanywhere.tech/v1
|
||||||
|
|
||||||
|
# 服务配置
|
||||||
|
HOST=127.0.0.1 # 如果使用Docker部署,需要改成0.0.0.0,否则QQ消息无法传入
|
||||||
|
PORT=8080
|
||||||
|
|
||||||
|
# 数据库配置
|
||||||
|
MONGODB_HOST=127.0.0.1 # 如果使用Docker部署,需要改成数据库容器的名字,默认是mongodb
|
||||||
|
MONGODB_PORT=27017
|
||||||
|
DATABASE_NAME=MegBot
|
||||||
|
MONGODB_USERNAME = "" # 数据库用户名
|
||||||
|
MONGODB_PASSWORD = "" # 数据库密码
|
||||||
|
MONGODB_AUTH_SOURCE = "" # 认证数据库
|
||||||
|
|
||||||
|
# 插件配置
|
||||||
|
PLUGINS=["src2.plugins.chat"]
|
||||||
|
```
|
||||||
|
|
||||||
|
##### 机器人配置文件 (bot_config.toml)
|
||||||
|
|
||||||
|
```
|
||||||
|
[bot]
|
||||||
|
qq = "机器人QQ号" # 必填
|
||||||
|
nickname = "麦麦" # 机器人昵称(你希望机器人怎么称呼它自己)
|
||||||
|
|
||||||
|
[personality]
|
||||||
|
prompt_personality = [
|
||||||
|
"曾经是一个学习地质的女大学生,现在学习心理学和脑科学,你会刷贴吧",
|
||||||
|
"是一个女大学生,你有黑色头发,你会刷小红书"
|
||||||
|
]
|
||||||
|
prompt_schedule = "一个曾经学习地质,现在学习心理学和脑科学的女大学生,喜欢刷qq,贴吧,知乎和小红书"
|
||||||
|
|
||||||
|
[message]
|
||||||
|
min_text_length = 2 # 最小回复长度
|
||||||
|
max_context_size = 15 # 上下文记忆条数
|
||||||
|
emoji_chance = 0.2 # 表情使用概率
|
||||||
|
ban_words = [] # 禁用词列表
|
||||||
|
|
||||||
|
[emoji]
|
||||||
|
auto_save = true # 自动保存表情
|
||||||
|
enable_check = false # 启用表情审核
|
||||||
|
check_prompt = "符合公序良俗"
|
||||||
|
|
||||||
|
[groups]
|
||||||
|
talk_allowed = [] # 允许对话的群号
|
||||||
|
talk_frequency_down = [] # 降低回复频率的群号
|
||||||
|
ban_user_id = [] # 禁止回复的用户QQ号
|
||||||
|
|
||||||
|
[others]
|
||||||
|
enable_advance_output = true # 启用详细日志
|
||||||
|
enable_kuuki_read = true # 启用场景理解
|
||||||
|
|
||||||
|
# 模型配置
|
||||||
|
[model.llm_reasoning] # 推理模型
|
||||||
|
name = "Pro/deepseek-ai/DeepSeek-R1"
|
||||||
|
base_url = "SILICONFLOW_BASE_URL"
|
||||||
|
key = "SILICONFLOW_KEY"
|
||||||
|
|
||||||
|
[model.llm_reasoning_minor] # 轻量推理模型
|
||||||
|
name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
|
||||||
|
base_url = "SILICONFLOW_BASE_URL"
|
||||||
|
key = "SILICONFLOW_KEY"
|
||||||
|
|
||||||
|
[model.llm_normal] # 对话模型
|
||||||
|
name = "Pro/deepseek-ai/DeepSeek-V3"
|
||||||
|
base_url = "SILICONFLOW_BASE_URL"
|
||||||
|
key = "SILICONFLOW_KEY"
|
||||||
|
|
||||||
|
[model.llm_normal_minor] # 备用对话模型
|
||||||
|
name = "deepseek-ai/DeepSeek-V2.5"
|
||||||
|
base_url = "SILICONFLOW_BASE_URL"
|
||||||
|
key = "SILICONFLOW_KEY"
|
||||||
|
|
||||||
|
[model.vlm] # 图像识别模型
|
||||||
|
name = "deepseek-ai/deepseek-vl2"
|
||||||
|
base_url = "SILICONFLOW_BASE_URL"
|
||||||
|
key = "SILICONFLOW_KEY"
|
||||||
|
|
||||||
|
[model.embedding] # 文本向量模型
|
||||||
|
name = "BAAI/bge-m3"
|
||||||
|
base_url = "SILICONFLOW_BASE_URL"
|
||||||
|
key = "SILICONFLOW_KEY"
|
||||||
|
|
||||||
|
|
||||||
|
[topic.llm_topic]
|
||||||
|
name = "Pro/deepseek-ai/DeepSeek-V3"
|
||||||
|
base_url = "SILICONFLOW_BASE_URL"
|
||||||
|
key = "SILICONFLOW_KEY"
|
||||||
|
```
|
||||||
|
|
||||||
|
**step # 6** 运行
|
||||||
|
|
||||||
|
现在再运行
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cd /moi/mai/bot
|
||||||
|
python -m venv venv
|
||||||
|
source venv/bin/activate
|
||||||
|
python bot.py
|
||||||
|
```
|
||||||
|
|
||||||
|
应该就能运行成功了。
|
||||||
|
|
||||||
|
## 8.事后配置
|
||||||
|
|
||||||
|
可是现在还有个问题:只要你一关闭终端,bot.py就会停止运行。那该怎么办呢?我们可以把bot.py注册成服务。
|
||||||
|
|
||||||
|
重启服务器,打开MongoDB和napcat服务。
|
||||||
|
|
||||||
|
新建一个文件,名为`bot.service`,内容如下
|
||||||
|
|
||||||
|
```
|
||||||
|
[Unit]
|
||||||
|
Description=maimai bot
|
||||||
|
|
||||||
|
[Service]
|
||||||
|
WorkingDirectory=/moi/mai/bot
|
||||||
|
ExecStart=/moi/mai/bot/venv/bin/python /moi/mai/bot/bot.py
|
||||||
|
Restart=on-failure
|
||||||
|
User=root
|
||||||
|
|
||||||
|
[Install]
|
||||||
|
WantedBy=multi-user.target
|
||||||
|
```
|
||||||
|
|
||||||
|
里面的路径视自己的情况更改。
|
||||||
|
|
||||||
|
把它放到`/etc/systemd/system`里面。
|
||||||
|
|
||||||
|
重新加载 `systemd` 配置:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo systemctl daemon-reload
|
||||||
|
```
|
||||||
|
|
||||||
|
启动服务:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo systemctl start bot.service # 启动服务
|
||||||
|
sudo systemctl restart bot.service # 或者重启服务
|
||||||
|
```
|
||||||
|
|
||||||
|
检查服务状态:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo systemctl status bot.service
|
||||||
|
```
|
||||||
|
|
||||||
|
现在再关闭终端,检查麦麦能不能正常回复QQ信息。如果可以的话就大功告成了!
|
||||||
|
|
||||||
|
## 9.命令速查
|
||||||
|
|
||||||
|
```bash
|
||||||
|
service mongod start # 启动mongod服务
|
||||||
|
napcat start <你的QQ号> # 登录napcat
|
||||||
|
cd /moi/mai/bot # 切换路径
|
||||||
|
python -m venv venv # 创建虚拟环境
|
||||||
|
source venv/bin/activate # 激活虚拟环境
|
||||||
|
|
||||||
|
sudo systemctl daemon-reload # 重新加载systemd配置
|
||||||
|
sudo systemctl start bot.service # 启动bot服务
|
||||||
|
sudo systemctl enable bot.service # 启动bot服务
|
||||||
|
|
||||||
|
sudo systemctl status bot.service # 检查bot服务状态
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
python bot.py
|
||||||
|
```
|
||||||
|
|
||||||
@@ -1,6 +1,7 @@
|
|||||||
# 📦 Linux系统如何手动部署MaiMbot麦麦?
|
# 📦 Linux系统如何手动部署MaiMbot麦麦?
|
||||||
|
|
||||||
## 准备工作
|
## 准备工作
|
||||||
|
|
||||||
- 一台联网的Linux设备(本教程以Ubuntu/Debian系为例)
|
- 一台联网的Linux设备(本教程以Ubuntu/Debian系为例)
|
||||||
- QQ小号(QQ框架的使用可能导致qq被风控,严重(小概率)可能会导致账号封禁,强烈不推荐使用大号)
|
- QQ小号(QQ框架的使用可能导致qq被风控,严重(小概率)可能会导致账号封禁,强烈不推荐使用大号)
|
||||||
- 可用的大模型API
|
- 可用的大模型API
|
||||||
@@ -20,6 +21,7 @@
|
|||||||
- 数据库是什么?如何安装并启动MongoDB
|
- 数据库是什么?如何安装并启动MongoDB
|
||||||
|
|
||||||
- 如何运行一个QQ机器人,以及NapCat框架是什么
|
- 如何运行一个QQ机器人,以及NapCat框架是什么
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
## 环境配置
|
## 环境配置
|
||||||
@@ -33,7 +35,9 @@ python --version
|
|||||||
# 或
|
# 或
|
||||||
python3 --version
|
python3 --version
|
||||||
```
|
```
|
||||||
|
|
||||||
如果版本低于3.9,请更新Python版本。
|
如果版本低于3.9,请更新Python版本。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# Ubuntu/Debian
|
# Ubuntu/Debian
|
||||||
sudo apt update
|
sudo apt update
|
||||||
@@ -45,6 +49,7 @@ sudo update-alternatives --config python3
|
|||||||
```
|
```
|
||||||
|
|
||||||
### 2️⃣ **创建虚拟环境**
|
### 2️⃣ **创建虚拟环境**
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# 方法1:使用venv(推荐)
|
# 方法1:使用venv(推荐)
|
||||||
python3 -m venv maimbot
|
python3 -m venv maimbot
|
||||||
@@ -65,32 +70,37 @@ pip install -r requirements.txt
|
|||||||
---
|
---
|
||||||
|
|
||||||
## 数据库配置
|
## 数据库配置
|
||||||
### 3️⃣ **安装并启动MongoDB**
|
|
||||||
- 安装与启动:Debian参考[官方文档](https://docs.mongodb.com/manual/tutorial/install-mongodb-on-debian/),Ubuntu参考[官方文档](https://docs.mongodb.com/manual/tutorial/install-mongodb-on-ubuntu/)
|
|
||||||
|
|
||||||
|
### 3️⃣ **安装并启动MongoDB**
|
||||||
|
|
||||||
|
- 安装与启动:Debian参考[官方文档](https://docs.mongodb.com/manual/tutorial/install-mongodb-on-debian/),Ubuntu参考[官方文档](https://docs.mongodb.com/manual/tutorial/install-mongodb-on-ubuntu/)
|
||||||
- 默认连接本地27017端口
|
- 默认连接本地27017端口
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
## NapCat配置
|
## NapCat配置
|
||||||
|
|
||||||
### 4️⃣ **安装NapCat框架**
|
### 4️⃣ **安装NapCat框架**
|
||||||
|
|
||||||
- 参考[NapCat官方文档](https://www.napcat.wiki/guide/boot/Shell#napcat-installer-linux%E4%B8%80%E9%94%AE%E4%BD%BF%E7%94%A8%E8%84%9A%E6%9C%AC-%E6%94%AF%E6%8C%81ubuntu-20-debian-10-centos9)安装
|
- 参考[NapCat官方文档](https://www.napcat.wiki/guide/boot/Shell#napcat-installer-linux%E4%B8%80%E9%94%AE%E4%BD%BF%E7%94%A8%E8%84%9A%E6%9C%AC-%E6%94%AF%E6%8C%81ubuntu-20-debian-10-centos9)安装
|
||||||
|
|
||||||
- 使用QQ小号登录,添加反向WS地址:
|
- 使用QQ小号登录,添加反向WS地址: `ws://127.0.0.1:8080/onebot/v11/ws`
|
||||||
`ws://127.0.0.1:8080/onebot/v11/ws`
|
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
## 配置文件设置
|
## 配置文件设置
|
||||||
|
|
||||||
### 5️⃣ **配置文件设置,让麦麦Bot正常工作**
|
### 5️⃣ **配置文件设置,让麦麦Bot正常工作**
|
||||||
|
|
||||||
- 修改环境配置文件:`.env.prod`
|
- 修改环境配置文件:`.env.prod`
|
||||||
- 修改机器人配置文件:`bot_config.toml`
|
- 修改机器人配置文件:`bot_config.toml`
|
||||||
|
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
## 启动机器人
|
## 启动机器人
|
||||||
|
|
||||||
### 6️⃣ **启动麦麦机器人**
|
### 6️⃣ **启动麦麦机器人**
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# 在项目目录下操作
|
# 在项目目录下操作
|
||||||
nb run
|
nb run
|
||||||
@@ -100,16 +110,70 @@ python3 bot.py
|
|||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
## **其他组件(可选)**
|
### 7️⃣ **使用systemctl管理maimbot**
|
||||||
- 直接运行 knowledge.py生成知识库
|
|
||||||
|
|
||||||
|
使用以下命令添加服务文件:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo nano /etc/systemd/system/maimbot.service
|
||||||
|
```
|
||||||
|
|
||||||
|
输入以下内容:
|
||||||
|
|
||||||
|
`<maimbot_directory>`:你的maimbot目录
|
||||||
|
|
||||||
|
`<venv_directory>`:你的venv环境(就是上文创建环境后,执行的代码`source maimbot/bin/activate`中source后面的路径的绝对路径)
|
||||||
|
|
||||||
|
```ini
|
||||||
|
[Unit]
|
||||||
|
Description=MaiMbot 麦麦
|
||||||
|
After=network.target mongod.service
|
||||||
|
|
||||||
|
[Service]
|
||||||
|
Type=simple
|
||||||
|
WorkingDirectory=<maimbot_directory>
|
||||||
|
ExecStart=<venv_directory>/python3 bot.py
|
||||||
|
ExecStop=/bin/kill -2 $MAINPID
|
||||||
|
Restart=always
|
||||||
|
RestartSec=10s
|
||||||
|
|
||||||
|
[Install]
|
||||||
|
WantedBy=multi-user.target
|
||||||
|
```
|
||||||
|
|
||||||
|
输入以下命令重新加载systemd:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo systemctl daemon-reload
|
||||||
|
```
|
||||||
|
|
||||||
|
启动并设置开机自启:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo systemctl start maimbot
|
||||||
|
sudo systemctl enable maimbot
|
||||||
|
```
|
||||||
|
|
||||||
|
输入以下命令查看日志:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo journalctl -xeu maimbot
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## **其他组件(可选)**
|
||||||
|
|
||||||
|
- 直接运行 knowledge.py生成知识库
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
## 常见问题
|
## 常见问题
|
||||||
|
|
||||||
🔧 权限问题:在命令前加`sudo`
|
🔧 权限问题:在命令前加`sudo`
|
||||||
🔌 端口占用:使用`sudo lsof -i :8080`查看端口占用
|
🔌 端口占用:使用`sudo lsof -i :8080`查看端口占用
|
||||||
🛡️ 防火墙:确保8080/27017端口开放
|
🛡️ 防火墙:确保8080/27017端口开放
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
sudo ufw allow 8080/tcp
|
sudo ufw allow 8080/tcp
|
||||||
sudo ufw allow 27017/tcp
|
sudo ufw allow 27017/tcp
|
||||||
|
|||||||
@@ -30,12 +30,13 @@
|
|||||||
|
|
||||||
在创建虚拟环境之前,请确保你的电脑上安装了Python 3.9及以上版本。如果没有,可以按以下步骤安装:
|
在创建虚拟环境之前,请确保你的电脑上安装了Python 3.9及以上版本。如果没有,可以按以下步骤安装:
|
||||||
|
|
||||||
1. 访问Python官网下载页面:https://www.python.org/downloads/release/python-3913/
|
1. 访问Python官网下载页面:<https://www.python.org/downloads/release/python-3913/>
|
||||||
2. 下载Windows安装程序 (64-bit): `python-3.9.13-amd64.exe`
|
2. 下载Windows安装程序 (64-bit): `python-3.9.13-amd64.exe`
|
||||||
3. 运行安装程序,并确保勾选"Add Python 3.9 to PATH"选项
|
3. 运行安装程序,并确保勾选"Add Python 3.9 to PATH"选项
|
||||||
4. 点击"Install Now"开始安装
|
4. 点击"Install Now"开始安装
|
||||||
|
|
||||||
或者使用PowerShell自动下载安装(需要管理员权限):
|
或者使用PowerShell自动下载安装(需要管理员权限):
|
||||||
|
|
||||||
```powershell
|
```powershell
|
||||||
# 下载并安装Python 3.9.13
|
# 下载并安装Python 3.9.13
|
||||||
$pythonUrl = "https://www.python.org/ftp/python/3.9.13/python-3.9.13-amd64.exe"
|
$pythonUrl = "https://www.python.org/ftp/python/3.9.13/python-3.9.13-amd64.exe"
|
||||||
@@ -46,7 +47,7 @@ Start-Process -Wait -FilePath $pythonInstaller -ArgumentList "/quiet", "InstallA
|
|||||||
|
|
||||||
### 2️⃣ **创建Python虚拟环境来运行程序**
|
### 2️⃣ **创建Python虚拟环境来运行程序**
|
||||||
|
|
||||||
你可以选择使用以下两种方法之一来创建Python环境:
|
> 你可以选择使用以下两种方法之一来创建Python环境:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# ---方法1:使用venv(Python自带)
|
# ---方法1:使用venv(Python自带)
|
||||||
@@ -60,6 +61,7 @@ maimbot\\Scripts\\activate
|
|||||||
# 安装依赖
|
# 安装依赖
|
||||||
pip install -r requirements.txt
|
pip install -r requirements.txt
|
||||||
```
|
```
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# ---方法2:使用conda
|
# ---方法2:使用conda
|
||||||
# 创建一个新的conda环境(环境名为maimbot)
|
# 创建一个新的conda环境(环境名为maimbot)
|
||||||
@@ -74,27 +76,35 @@ pip install -r requirements.txt
|
|||||||
```
|
```
|
||||||
|
|
||||||
### 2️⃣ **然后你需要启动MongoDB数据库,来存储信息**
|
### 2️⃣ **然后你需要启动MongoDB数据库,来存储信息**
|
||||||
|
|
||||||
- 安装并启动MongoDB服务
|
- 安装并启动MongoDB服务
|
||||||
- 默认连接本地27017端口
|
- 默认连接本地27017端口
|
||||||
|
|
||||||
### 3️⃣ **配置NapCat,让麦麦bot与qq取得联系**
|
### 3️⃣ **配置NapCat,让麦麦bot与qq取得联系**
|
||||||
|
|
||||||
- 安装并登录NapCat(用你的qq小号)
|
- 安装并登录NapCat(用你的qq小号)
|
||||||
- 添加反向WS:`ws://127.0.0.1:8080/onebot/v11/ws`
|
- 添加反向WS: `ws://127.0.0.1:8080/onebot/v11/ws`
|
||||||
|
|
||||||
### 4️⃣ **配置文件设置,让麦麦Bot正常工作**
|
### 4️⃣ **配置文件设置,让麦麦Bot正常工作**
|
||||||
|
|
||||||
- 修改环境配置文件:`.env.prod`
|
- 修改环境配置文件:`.env.prod`
|
||||||
- 修改机器人配置文件:`bot_config.toml`
|
- 修改机器人配置文件:`bot_config.toml`
|
||||||
|
|
||||||
### 5️⃣ **启动麦麦机器人**
|
### 5️⃣ **启动麦麦机器人**
|
||||||
|
|
||||||
- 打开命令行,cd到对应路径
|
- 打开命令行,cd到对应路径
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
nb run
|
nb run
|
||||||
```
|
```
|
||||||
|
|
||||||
- 或者cd到对应路径后
|
- 或者cd到对应路径后
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
python bot.py
|
python bot.py
|
||||||
```
|
```
|
||||||
|
|
||||||
### 6️⃣ **其他组件(可选)**
|
### 6️⃣ **其他组件(可选)**
|
||||||
|
|
||||||
- `run_thingking.bat`: 启动可视化推理界面(未完善)
|
- `run_thingking.bat`: 启动可视化推理界面(未完善)
|
||||||
- 直接运行 knowledge.py生成知识库
|
- 直接运行 knowledge.py生成知识库
|
||||||
|
|||||||
BIN
docs/synology_.env.prod.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 107 KiB |
BIN
docs/synology_create_project.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 208 KiB |
67
docs/synology_deploy.md
Normal file
@@ -0,0 +1,67 @@
|
|||||||
|
# 群晖 NAS 部署指南
|
||||||
|
|
||||||
|
**笔者使用的是 DSM 7.2.2,其他 DSM 版本的操作可能不完全一样**
|
||||||
|
**需要使用 Container Manager,群晖的部分部分入门级 NAS 可能不支持**
|
||||||
|
|
||||||
|
## 部署步骤
|
||||||
|
|
||||||
|
### 创建配置文件目录
|
||||||
|
|
||||||
|
打开 `DSM ➡️ 控制面板 ➡️ 共享文件夹`,点击 `新增` ,创建一个共享文件夹
|
||||||
|
只需要设置名称,其他设置均保持默认即可。如果你已经有 docker 专用的共享文件夹了,就跳过这一步
|
||||||
|
|
||||||
|
打开 `DSM ➡️ FileStation`, 在共享文件夹中创建一个 `MaiMBot` 文件夹
|
||||||
|
|
||||||
|
### 准备配置文件
|
||||||
|
|
||||||
|
docker-compose.yml: https://github.com/SengokuCola/MaiMBot/blob/main/docker-compose.yml
|
||||||
|
下载后打开,将 `services-mongodb-image` 修改为 `mongo:4.4.24`。这是因为最新的 MongoDB 强制要求 AVX 指令集,而群晖似乎不支持这个指令集
|
||||||
|
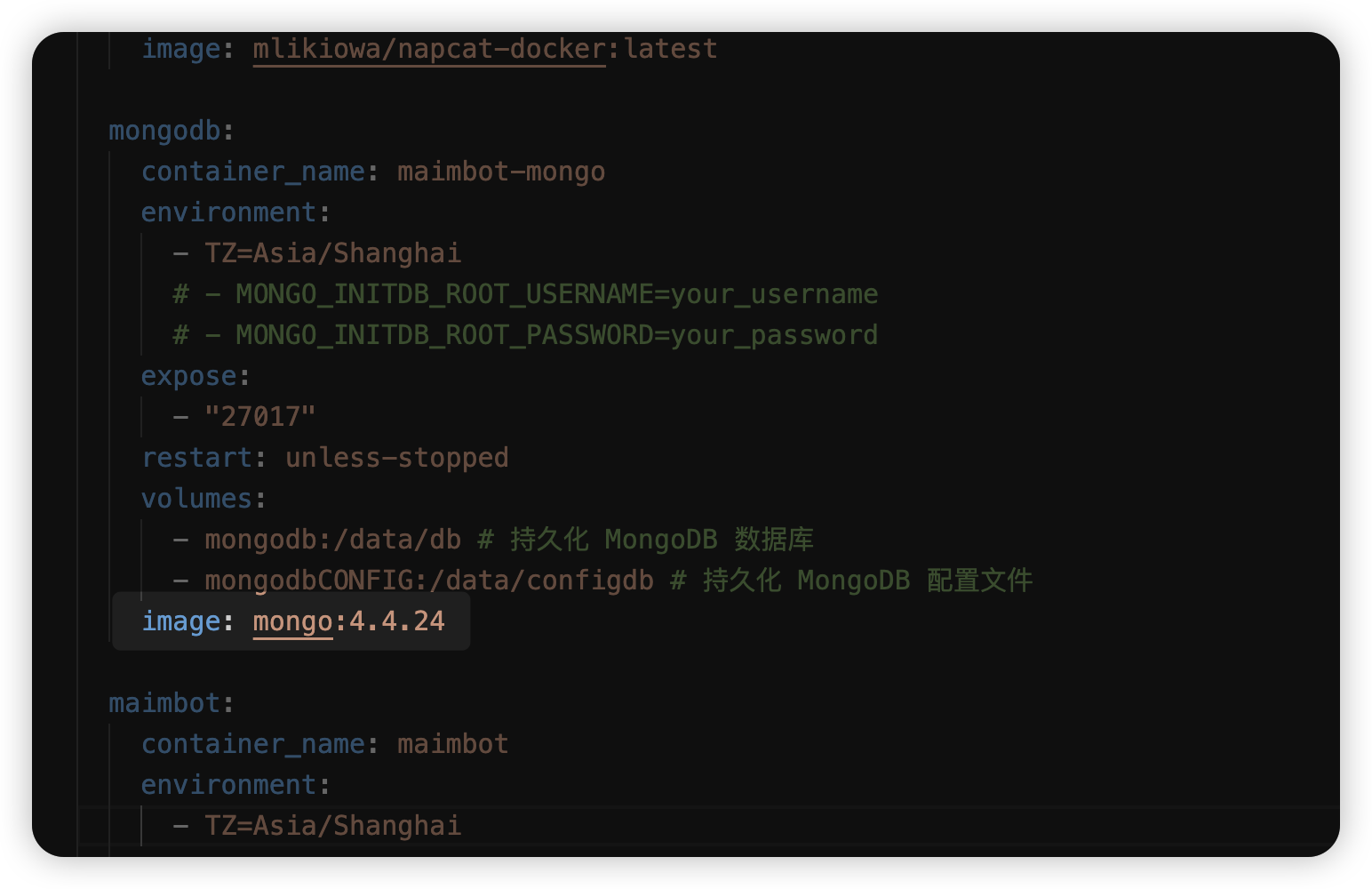
|
||||||
|
|
||||||
|
bot_config.toml: https://github.com/SengokuCola/MaiMBot/blob/main/template/bot_config_template.toml
|
||||||
|
下载后,重命名为 `bot_config.toml`
|
||||||
|
打开它,按自己的需求填写配置文件
|
||||||
|
|
||||||
|
.env.prod: https://github.com/SengokuCola/MaiMBot/blob/main/template.env
|
||||||
|
下载后,重命名为 `.env.prod`
|
||||||
|
按下图修改 mongodb 设置,使用 `MONGODB_URI`
|
||||||
|
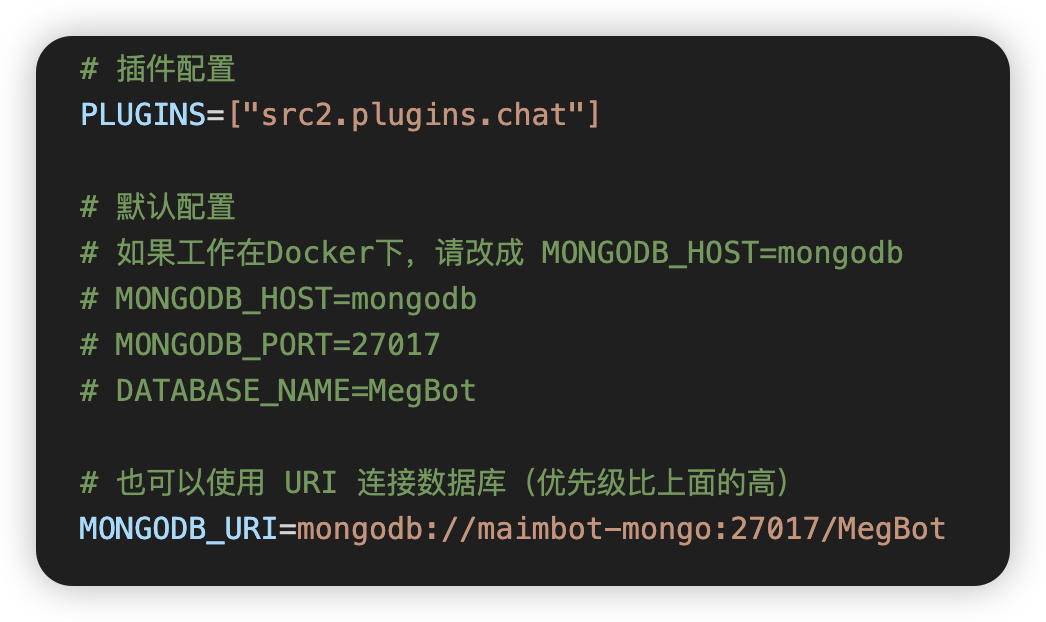
|
||||||
|
|
||||||
|
把 `bot_config.toml` 和 `.env.prod` 放入之前创建的 `MaiMBot`文件夹
|
||||||
|
|
||||||
|
#### 如何下载?
|
||||||
|
|
||||||
|
点这里!
|
||||||
|
|
||||||
|
### 创建项目
|
||||||
|
|
||||||
|
打开 `DSM ➡️ ContainerManager ➡️ 项目`,点击 `新增` 创建项目,填写以下内容:
|
||||||
|
|
||||||
|
- 项目名称: `maimbot`
|
||||||
|
- 路径:之前创建的 `MaiMBot` 文件夹
|
||||||
|
- 来源: `上传 docker-compose.yml`
|
||||||
|
- 文件:之前下载的 `docker-compose.yml` 文件
|
||||||
|
|
||||||
|
图例:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
一路点下一步,等待项目创建完成
|
||||||
|
|
||||||
|
### 设置 Napcat
|
||||||
|
|
||||||
|
1. 登陆 napcat
|
||||||
|
打开 napcat: `http://<你的nas地址>:6099` ,输入token登陆
|
||||||
|
token可以打开 `DSM ➡️ ContainerManager ➡️ 项目 ➡️ MaiMBot ➡️ 容器 ➡️ Napcat ➡️ 日志`,找到类似 `[WebUi] WebUi Local Panel Url: http://127.0.0.1:6099/webui?token=xxxx` 的日志
|
||||||
|
这个 `token=` 后面的就是你的 napcat token
|
||||||
|
|
||||||
|
2. 按提示,登陆你给麦麦准备的QQ小号
|
||||||
|
|
||||||
|
3. 设置 websocket 客户端
|
||||||
|
`网络配置 -> 新建 -> Websocket客户端`,名称自定,URL栏填入 `ws://maimbot:8080/onebot/v11/ws`,启用并保存即可。
|
||||||
|
若修改过容器名称,则替换 `maimbot` 为你自定的名称
|
||||||
|
|
||||||
|
### 部署完成
|
||||||
|
|
||||||
|
找个群,发送 `麦麦,你在吗` 之类的
|
||||||
|
如果一切正常,应该能正常回复了
|
||||||
BIN
docs/synology_docker-compose.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 170 KiB |
BIN
docs/synology_how_to_download.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 133 KiB |
56
flake.lock
generated
@@ -1,43 +1,21 @@
|
|||||||
{
|
{
|
||||||
"nodes": {
|
"nodes": {
|
||||||
"flake-utils": {
|
|
||||||
"inputs": {
|
|
||||||
"systems": "systems"
|
|
||||||
},
|
|
||||||
"locked": {
|
|
||||||
"lastModified": 1731533236,
|
|
||||||
"narHash": "sha256-l0KFg5HjrsfsO/JpG+r7fRrqm12kzFHyUHqHCVpMMbI=",
|
|
||||||
"owner": "numtide",
|
|
||||||
"repo": "flake-utils",
|
|
||||||
"rev": "11707dc2f618dd54ca8739b309ec4fc024de578b",
|
|
||||||
"type": "github"
|
|
||||||
},
|
|
||||||
"original": {
|
|
||||||
"owner": "numtide",
|
|
||||||
"repo": "flake-utils",
|
|
||||||
"type": "github"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"nixpkgs": {
|
"nixpkgs": {
|
||||||
"locked": {
|
"locked": {
|
||||||
"lastModified": 1741196730,
|
"lastModified": 0,
|
||||||
"narHash": "sha256-0Sj6ZKjCpQMfWnN0NURqRCQn2ob7YtXTAOTwCuz7fkA=",
|
"narHash": "sha256-nJj8f78AYAxl/zqLiFGXn5Im1qjFKU8yBPKoWEeZN5M=",
|
||||||
"owner": "NixOS",
|
"path": "/nix/store/f30jn7l0bf7a01qj029fq55i466vmnkh-source",
|
||||||
"repo": "nixpkgs",
|
"type": "path"
|
||||||
"rev": "48913d8f9127ea6530a2a2f1bd4daa1b8685d8a3",
|
|
||||||
"type": "github"
|
|
||||||
},
|
},
|
||||||
"original": {
|
"original": {
|
||||||
"owner": "NixOS",
|
"id": "nixpkgs",
|
||||||
"ref": "nixos-24.11",
|
"type": "indirect"
|
||||||
"repo": "nixpkgs",
|
|
||||||
"type": "github"
|
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"root": {
|
"root": {
|
||||||
"inputs": {
|
"inputs": {
|
||||||
"flake-utils": "flake-utils",
|
"nixpkgs": "nixpkgs",
|
||||||
"nixpkgs": "nixpkgs"
|
"utils": "utils"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"systems": {
|
"systems": {
|
||||||
@@ -54,6 +32,24 @@
|
|||||||
"repo": "default",
|
"repo": "default",
|
||||||
"type": "github"
|
"type": "github"
|
||||||
}
|
}
|
||||||
|
},
|
||||||
|
"utils": {
|
||||||
|
"inputs": {
|
||||||
|
"systems": "systems"
|
||||||
|
},
|
||||||
|
"locked": {
|
||||||
|
"lastModified": 1731533236,
|
||||||
|
"narHash": "sha256-l0KFg5HjrsfsO/JpG+r7fRrqm12kzFHyUHqHCVpMMbI=",
|
||||||
|
"owner": "numtide",
|
||||||
|
"repo": "flake-utils",
|
||||||
|
"rev": "11707dc2f618dd54ca8739b309ec4fc024de578b",
|
||||||
|
"type": "github"
|
||||||
|
},
|
||||||
|
"original": {
|
||||||
|
"owner": "numtide",
|
||||||
|
"repo": "flake-utils",
|
||||||
|
"type": "github"
|
||||||
|
}
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"root": "root",
|
"root": "root",
|
||||||
|
|||||||
69
flake.nix
@@ -1,61 +1,38 @@
|
|||||||
{
|
{
|
||||||
description = "MaiMBot Nix Dev Env";
|
description = "MaiMBot Nix Dev Env";
|
||||||
# 本配置仅方便用于开发,但是因为 nb-cli 上游打包中并未包含 nonebot2,因此目前本配置并不能用于运行和调试
|
|
||||||
|
|
||||||
inputs = {
|
inputs = {
|
||||||
nixpkgs.url = "github:NixOS/nixpkgs/nixos-24.11";
|
utils.url = "github:numtide/flake-utils";
|
||||||
flake-utils.url = "github:numtide/flake-utils";
|
|
||||||
};
|
};
|
||||||
|
|
||||||
outputs =
|
outputs = {
|
||||||
{
|
|
||||||
self,
|
self,
|
||||||
nixpkgs,
|
nixpkgs,
|
||||||
flake-utils,
|
utils,
|
||||||
|
...
|
||||||
}:
|
}:
|
||||||
flake-utils.lib.eachDefaultSystem (
|
utils.lib.eachDefaultSystem (system: let
|
||||||
system:
|
pkgs = import nixpkgs {inherit system;};
|
||||||
let
|
pythonPackages = pkgs.python3Packages;
|
||||||
pkgs = import nixpkgs {
|
in {
|
||||||
inherit system;
|
devShells.default = pkgs.mkShell {
|
||||||
};
|
name = "python-venv";
|
||||||
|
venvDir = "./.venv";
|
||||||
pythonEnv = pkgs.python3.withPackages (
|
|
||||||
ps: with ps; [
|
|
||||||
pymongo
|
|
||||||
python-dotenv
|
|
||||||
pydantic
|
|
||||||
jieba
|
|
||||||
openai
|
|
||||||
aiohttp
|
|
||||||
requests
|
|
||||||
urllib3
|
|
||||||
numpy
|
|
||||||
pandas
|
|
||||||
matplotlib
|
|
||||||
networkx
|
|
||||||
python-dateutil
|
|
||||||
APScheduler
|
|
||||||
loguru
|
|
||||||
tomli
|
|
||||||
customtkinter
|
|
||||||
colorama
|
|
||||||
pypinyin
|
|
||||||
pillow
|
|
||||||
setuptools
|
|
||||||
]
|
|
||||||
);
|
|
||||||
in
|
|
||||||
{
|
|
||||||
devShell = pkgs.mkShell {
|
|
||||||
buildInputs = [
|
buildInputs = [
|
||||||
pythonEnv
|
pythonPackages.python
|
||||||
pkgs.nb-cli
|
pythonPackages.venvShellHook
|
||||||
|
pythonPackages.numpy
|
||||||
];
|
];
|
||||||
|
|
||||||
shellHook = ''
|
postVenvCreation = ''
|
||||||
|
unset SOURCE_DATE_EPOCH
|
||||||
|
pip install -r requirements.txt
|
||||||
|
'';
|
||||||
|
|
||||||
|
postShellHook = ''
|
||||||
|
# allow pip to install wheels
|
||||||
|
unset SOURCE_DATE_EPOCH
|
||||||
'';
|
'';
|
||||||
};
|
};
|
||||||
}
|
});
|
||||||
);
|
|
||||||
}
|
}
|
||||||
@@ -1,23 +1,51 @@
|
|||||||
[project]
|
[project]
|
||||||
name = "Megbot"
|
name = "MaiMaiBot"
|
||||||
version = "0.1.0"
|
version = "0.1.0"
|
||||||
description = "New Bot Project"
|
description = "MaiMaiBot"
|
||||||
|
|
||||||
[tool.nonebot]
|
[tool.nonebot]
|
||||||
plugins = ["src.plugins.chat"]
|
plugins = ["src.plugins.chat"]
|
||||||
plugin_dirs = ["src/plugins"]
|
plugin_dirs = ["src/plugins"]
|
||||||
|
|
||||||
[tool.ruff]
|
[tool.ruff]
|
||||||
# 设置 Python 版本
|
|
||||||
target-version = "py39"
|
include = ["*.py"]
|
||||||
|
|
||||||
|
# 行长度设置
|
||||||
|
line-length = 120
|
||||||
|
|
||||||
|
[tool.ruff.lint]
|
||||||
|
fixable = ["ALL"]
|
||||||
|
unfixable = []
|
||||||
|
|
||||||
|
# 如果一个变量的名称以下划线开头,即使它未被使用,也不应该被视为错误或警告。
|
||||||
|
dummy-variable-rgx = "^(_+|(_+[a-zA-Z0-9_]*[a-zA-Z0-9]+?))$"
|
||||||
|
|
||||||
# 启用的规则
|
# 启用的规则
|
||||||
select = [
|
select = [
|
||||||
"E", # pycodestyle 错误
|
"E", # pycodestyle 错误
|
||||||
"F", # pyflakes
|
"F", # pyflakes
|
||||||
"I", # isort
|
|
||||||
"B", # flake8-bugbear
|
"B", # flake8-bugbear
|
||||||
]
|
]
|
||||||
|
|
||||||
# 行长度设置
|
ignore = ["E711"]
|
||||||
line-length = 88
|
|
||||||
|
[tool.ruff.format]
|
||||||
|
docstring-code-format = true
|
||||||
|
indent-style = "space"
|
||||||
|
|
||||||
|
|
||||||
|
# 使用双引号表示字符串
|
||||||
|
quote-style = "double"
|
||||||
|
|
||||||
|
# 尊重魔法尾随逗号
|
||||||
|
# 例如:
|
||||||
|
# items = [
|
||||||
|
# "apple",
|
||||||
|
# "banana",
|
||||||
|
# "cherry",
|
||||||
|
# ]
|
||||||
|
skip-magic-trailing-comma = false
|
||||||
|
|
||||||
|
# 自动检测合适的换行符
|
||||||
|
line-ending = "auto"
|
||||||
|
|||||||
BIN
requirements.txt
2
run.bat
@@ -3,7 +3,7 @@ chcp 65001
|
|||||||
if not exist "venv" (
|
if not exist "venv" (
|
||||||
python -m venv venv
|
python -m venv venv
|
||||||
call venv\Scripts\activate.bat
|
call venv\Scripts\activate.bat
|
||||||
pip install -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple --upgrade -r requirements.txt
|
pip install -i https://mirrors.aliyun.com/pypi/simple --upgrade -r requirements.txt
|
||||||
) else (
|
) else (
|
||||||
call venv\Scripts\activate.bat
|
call venv\Scripts\activate.bat
|
||||||
)
|
)
|
||||||
|
|||||||
10
run.py
@@ -107,6 +107,8 @@ def install_napcat():
|
|||||||
napcat_filename = input(
|
napcat_filename = input(
|
||||||
"下载完成后请把文件复制到此文件夹,并将**不包含后缀的文件名**输入至此窗口,如 NapCat.32793.Shell:"
|
"下载完成后请把文件复制到此文件夹,并将**不包含后缀的文件名**输入至此窗口,如 NapCat.32793.Shell:"
|
||||||
)
|
)
|
||||||
|
if(napcat_filename[-4:] == ".zip"):
|
||||||
|
napcat_filename = napcat_filename[:-4]
|
||||||
extract_files(napcat_filename + ".zip", "napcat")
|
extract_files(napcat_filename + ".zip", "napcat")
|
||||||
print("NapCat 安装完成")
|
print("NapCat 安装完成")
|
||||||
os.remove(napcat_filename + ".zip")
|
os.remove(napcat_filename + ".zip")
|
||||||
@@ -126,13 +128,17 @@ if __name__ == "__main__":
|
|||||||
)
|
)
|
||||||
os.system("cls")
|
os.system("cls")
|
||||||
if choice == "1":
|
if choice == "1":
|
||||||
|
confirm = input("首次安装将下载并配置所需组件\n1.确认\n2.取消\n")
|
||||||
|
if confirm == "1":
|
||||||
install_napcat()
|
install_napcat()
|
||||||
install_mongodb()
|
install_mongodb()
|
||||||
|
else:
|
||||||
|
print("已取消安装")
|
||||||
elif choice == "2":
|
elif choice == "2":
|
||||||
run_maimbot()
|
run_maimbot()
|
||||||
choice = input("是否启动推理可视化?(y/N)").upper()
|
choice = input("是否启动推理可视化?(未完善)(y/N)").upper()
|
||||||
if choice == "Y":
|
if choice == "Y":
|
||||||
run_cmd(r"python src\gui\reasoning_gui.py")
|
run_cmd(r"python src\gui\reasoning_gui.py")
|
||||||
choice = input("是否启动记忆可视化?(y/N)").upper()
|
choice = input("是否启动记忆可视化?(未完善)(y/N)").upper()
|
||||||
if choice == "Y":
|
if choice == "Y":
|
||||||
run_cmd(r"python src/plugins/memory_system/memory_manual_build.py")
|
run_cmd(r"python src/plugins/memory_system/memory_manual_build.py")
|
||||||
|
|||||||
278
run.sh
Normal file
@@ -0,0 +1,278 @@
|
|||||||
|
#!/bin/bash
|
||||||
|
|
||||||
|
# Maimbot 一键安装脚本 by Cookie987
|
||||||
|
# 适用于Debian系
|
||||||
|
# 请小心使用任何一键脚本!
|
||||||
|
|
||||||
|
# 如无法访问GitHub请修改此处镜像地址
|
||||||
|
|
||||||
|
LANG=C.UTF-8
|
||||||
|
|
||||||
|
GITHUB_REPO="https://ghfast.top/https://github.com/SengokuCola/MaiMBot.git"
|
||||||
|
|
||||||
|
# 颜色输出
|
||||||
|
GREEN="\e[32m"
|
||||||
|
RED="\e[31m"
|
||||||
|
RESET="\e[0m"
|
||||||
|
|
||||||
|
# 需要的基本软件包
|
||||||
|
REQUIRED_PACKAGES=("git" "sudo" "python3" "python3-venv" "curl" "gnupg" "python3-pip")
|
||||||
|
|
||||||
|
# 默认项目目录
|
||||||
|
DEFAULT_INSTALL_DIR="/opt/maimbot"
|
||||||
|
|
||||||
|
# 服务名称
|
||||||
|
SERVICE_NAME="maimbot"
|
||||||
|
|
||||||
|
IS_INSTALL_MONGODB=false
|
||||||
|
IS_INSTALL_NAPCAT=false
|
||||||
|
|
||||||
|
# 1/6: 检测是否安装 whiptail
|
||||||
|
if ! command -v whiptail &>/dev/null; then
|
||||||
|
echo -e "${RED}[1/6] whiptail 未安装,正在安装...${RESET}"
|
||||||
|
apt update && apt install -y whiptail
|
||||||
|
fi
|
||||||
|
|
||||||
|
get_os_info() {
|
||||||
|
if command -v lsb_release &>/dev/null; then
|
||||||
|
OS_INFO=$(lsb_release -d | cut -f2)
|
||||||
|
elif [[ -f /etc/os-release ]]; then
|
||||||
|
OS_INFO=$(grep "^PRETTY_NAME=" /etc/os-release | cut -d '"' -f2)
|
||||||
|
else
|
||||||
|
OS_INFO="Unknown OS"
|
||||||
|
fi
|
||||||
|
echo "$OS_INFO"
|
||||||
|
}
|
||||||
|
|
||||||
|
# 检查系统
|
||||||
|
check_system() {
|
||||||
|
# 检查是否为 root 用户
|
||||||
|
if [[ "$(id -u)" -ne 0 ]]; then
|
||||||
|
whiptail --title "🚫 权限不足" --msgbox "请使用 root 用户运行此脚本!\n执行方式: sudo bash $0" 10 60
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
|
||||||
|
if [[ -f /etc/os-release ]]; then
|
||||||
|
source /etc/os-release
|
||||||
|
if [[ "$ID" != "debian" || "$VERSION_ID" != "12" ]]; then
|
||||||
|
whiptail --title "🚫 不支持的系统" --msgbox "此脚本仅支持 Debian 12 (Bookworm)!\n当前系统: $PRETTY_NAME\n安装已终止。" 10 60
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
else
|
||||||
|
whiptail --title "⚠️ 无法检测系统" --msgbox "无法识别系统版本,安装已终止。" 10 60
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
# 3/6: 询问用户是否安装缺失的软件包
|
||||||
|
install_packages() {
|
||||||
|
missing_packages=()
|
||||||
|
for package in "${REQUIRED_PACKAGES[@]}"; do
|
||||||
|
if ! dpkg -s "$package" &>/dev/null; then
|
||||||
|
missing_packages+=("$package")
|
||||||
|
fi
|
||||||
|
done
|
||||||
|
|
||||||
|
if [[ ${#missing_packages[@]} -gt 0 ]]; then
|
||||||
|
whiptail --title "📦 [3/6] 软件包检查" --yesno "检测到以下必须的依赖项目缺失:\n${missing_packages[*]}\n\n是否要自动安装?" 12 60
|
||||||
|
if [[ $? -eq 0 ]]; then
|
||||||
|
return 0
|
||||||
|
else
|
||||||
|
whiptail --title "⚠️ 注意" --yesno "某些必要的依赖项未安装,可能会影响运行!\n是否继续?" 10 60 || exit 1
|
||||||
|
fi
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
# 4/6: Python 版本检查
|
||||||
|
check_python() {
|
||||||
|
PYTHON_VERSION=$(python3 -c 'import sys; print(f"{sys.version_info.major}.{sys.version_info.minor}")')
|
||||||
|
|
||||||
|
python3 -c "import sys; exit(0) if sys.version_info >= (3,9) else exit(1)"
|
||||||
|
if [[ $? -ne 0 ]]; then
|
||||||
|
whiptail --title "⚠️ [4/6] Python 版本过低" --msgbox "检测到 Python 版本为 $PYTHON_VERSION,需要 3.9 或以上!\n请升级 Python 后重新运行本脚本。" 10 60
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
# 5/6: 选择分支
|
||||||
|
choose_branch() {
|
||||||
|
BRANCH=$(whiptail --title "🔀 [5/6] 选择 Maimbot 分支" --menu "请选择要安装的 Maimbot 分支:" 15 60 2 \
|
||||||
|
"main" "稳定版本(推荐)" \
|
||||||
|
"debug" "开发版本(可能不稳定)" 3>&1 1>&2 2>&3)
|
||||||
|
|
||||||
|
if [[ -z "$BRANCH" ]]; then
|
||||||
|
BRANCH="main"
|
||||||
|
whiptail --title "🔀 默认选择" --msgbox "未选择分支,默认安装稳定版本(main)" 10 60
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
# 6/6: 选择安装路径
|
||||||
|
choose_install_dir() {
|
||||||
|
INSTALL_DIR=$(whiptail --title "📂 [6/6] 选择安装路径" --inputbox "请输入 Maimbot 的安装目录:" 10 60 "$DEFAULT_INSTALL_DIR" 3>&1 1>&2 2>&3)
|
||||||
|
|
||||||
|
if [[ -z "$INSTALL_DIR" ]]; then
|
||||||
|
whiptail --title "⚠️ 取消输入" --yesno "未输入安装路径,是否退出安装?" 10 60
|
||||||
|
if [[ $? -ne 0 ]]; then
|
||||||
|
INSTALL_DIR="$DEFAULT_INSTALL_DIR"
|
||||||
|
else
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
# 显示确认界面
|
||||||
|
confirm_install() {
|
||||||
|
local confirm_message="请确认以下更改:\n\n"
|
||||||
|
|
||||||
|
if [[ ${#missing_packages[@]} -gt 0 ]]; then
|
||||||
|
confirm_message+="📦 安装缺失的依赖项: ${missing_packages[*]}\n"
|
||||||
|
else
|
||||||
|
confirm_message+="✅ 所有依赖项已安装\n"
|
||||||
|
fi
|
||||||
|
|
||||||
|
confirm_message+="📂 安装麦麦Bot到: $INSTALL_DIR\n"
|
||||||
|
confirm_message+="🔀 分支: $BRANCH\n"
|
||||||
|
|
||||||
|
if [[ "$MONGODB_INSTALLED" == "true" ]]; then
|
||||||
|
confirm_message+="✅ MongoDB 已安装\n"
|
||||||
|
else
|
||||||
|
if [[ "$IS_INSTALL_MONGODB" == "true" ]]; then
|
||||||
|
confirm_message+="📦 安装 MongoDB\n"
|
||||||
|
fi
|
||||||
|
fi
|
||||||
|
|
||||||
|
if [[ "$NAPCAT_INSTALLED" == "true" ]]; then
|
||||||
|
confirm_message+="✅ NapCat 已安装\n"
|
||||||
|
else
|
||||||
|
if [[ "$IS_INSTALL_NAPCAT" == "true" ]]; then
|
||||||
|
confirm_message+="📦 安装 NapCat\n"
|
||||||
|
fi
|
||||||
|
fi
|
||||||
|
|
||||||
|
confirm_message+="🛠️ 添加麦麦Bot作为系统服务 ($SERVICE_NAME.service)\n"
|
||||||
|
|
||||||
|
confitm_message+="\n\n注意:本脚本默认使用ghfast.top为GitHub进行加速,如不想使用请手动修改脚本开头的GITHUB_REPO变量。"
|
||||||
|
whiptail --title "🔧 安装确认" --yesno "$confirm_message\n\n是否继续安装?" 15 60
|
||||||
|
if [[ $? -ne 0 ]]; then
|
||||||
|
whiptail --title "🚫 取消安装" --msgbox "安装已取消。" 10 60
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
check_mongodb() {
|
||||||
|
if command -v mongod &>/dev/null; then
|
||||||
|
MONGO_INSTALLED=true
|
||||||
|
else
|
||||||
|
MONGO_INSTALLED=false
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
# 安装 MongoDB
|
||||||
|
install_mongodb() {
|
||||||
|
if [[ "$MONGO_INSTALLED" == "true" ]]; then
|
||||||
|
return 0
|
||||||
|
fi
|
||||||
|
|
||||||
|
whiptail --title "📦 [3/6] 软件包检查" --yesno "检测到未安装MongoDB,是否安装?\n如果您想使用远程数据库,请跳过此步。" 10 60
|
||||||
|
if [[ $? -ne 0 ]]; then
|
||||||
|
return 1
|
||||||
|
fi
|
||||||
|
IS_INSTALL_MONGODB=true
|
||||||
|
}
|
||||||
|
|
||||||
|
check_napcat() {
|
||||||
|
if command -v napcat &>/dev/null; then
|
||||||
|
NAPCAT_INSTALLED=true
|
||||||
|
else
|
||||||
|
NAPCAT_INSTALLED=false
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
install_napcat() {
|
||||||
|
if [[ "$NAPCAT_INSTALLED" == "true" ]]; then
|
||||||
|
return 0
|
||||||
|
fi
|
||||||
|
|
||||||
|
whiptail --title "📦 [3/6] 软件包检查" --yesno "检测到未安装NapCat,是否安装?\n如果您想使用远程NapCat,请跳过此步。" 10 60
|
||||||
|
if [[ $? -ne 0 ]]; then
|
||||||
|
return 1
|
||||||
|
fi
|
||||||
|
IS_INSTALL_NAPCAT=true
|
||||||
|
}
|
||||||
|
|
||||||
|
# 运行安装步骤
|
||||||
|
check_system
|
||||||
|
check_mongodb
|
||||||
|
check_napcat
|
||||||
|
install_packages
|
||||||
|
install_mongodb
|
||||||
|
install_napcat
|
||||||
|
check_python
|
||||||
|
choose_branch
|
||||||
|
choose_install_dir
|
||||||
|
confirm_install
|
||||||
|
|
||||||
|
# 开始安装
|
||||||
|
whiptail --title "🚀 开始安装" --msgbox "所有环境检查完毕,即将开始安装麦麦Bot!" 10 60
|
||||||
|
|
||||||
|
echo -e "${GREEN}安装依赖项...${RESET}"
|
||||||
|
|
||||||
|
apt update && apt install -y "${missing_packages[@]}"
|
||||||
|
|
||||||
|
|
||||||
|
if [[ "$IS_INSTALL_MONGODB" == "true" ]]; then
|
||||||
|
echo -e "${GREEN}安装 MongoDB...${RESET}"
|
||||||
|
curl -fsSL https://www.mongodb.org/static/pgp/server-8.0.asc | gpg -o /usr/share/keyrings/mongodb-server-8.0.gpg --dearmor
|
||||||
|
echo "deb [ signed-by=/usr/share/keyrings/mongodb-server-8.0.gpg ] http://repo.mongodb.org/apt/debian bookworm/mongodb-org/8.0 main" | sudo tee /etc/apt/sources.list.d/mongodb-org-8.0.list
|
||||||
|
apt-get update
|
||||||
|
apt-get install -y mongodb-org
|
||||||
|
|
||||||
|
systemctl enable mongod
|
||||||
|
systemctl start mongod
|
||||||
|
fi
|
||||||
|
|
||||||
|
if [[ "$IS_INSTALL_NAPCAT" == "true" ]]; then
|
||||||
|
echo -e "${GREEN}安装 NapCat...${RESET}"
|
||||||
|
curl -o napcat.sh https://nclatest.znin.net/NapNeko/NapCat-Installer/main/script/install.sh && bash napcat.sh
|
||||||
|
fi
|
||||||
|
|
||||||
|
echo -e "${GREEN}创建 Python 虚拟环境...${RESET}"
|
||||||
|
mkdir -p "$INSTALL_DIR"
|
||||||
|
cd "$INSTALL_DIR" || exit
|
||||||
|
python3 -m venv venv
|
||||||
|
source venv/bin/activate
|
||||||
|
|
||||||
|
echo -e "${GREEN}克隆仓库...${RESET}"
|
||||||
|
# 安装 Maimbot
|
||||||
|
mkdir -p "$INSTALL_DIR/repo"
|
||||||
|
cd "$INSTALL_DIR/repo" || exit 1
|
||||||
|
git clone -b "$BRANCH" $GITHUB_REPO .
|
||||||
|
|
||||||
|
echo -e "${GREEN}安装 Python 依赖...${RESET}"
|
||||||
|
pip install -r requirements.txt
|
||||||
|
|
||||||
|
echo -e "${GREEN}设置服务...${RESET}"
|
||||||
|
|
||||||
|
# 设置 Maimbot 服务
|
||||||
|
cat <<EOF | tee /etc/systemd/system/$SERVICE_NAME.service
|
||||||
|
[Unit]
|
||||||
|
Description=MaiMbot 麦麦
|
||||||
|
After=network.target mongod.service
|
||||||
|
|
||||||
|
[Service]
|
||||||
|
Type=simple
|
||||||
|
WorkingDirectory=$INSTALL_DIR/repo/
|
||||||
|
ExecStart=$INSTALL_DIR/venv/bin/python3 bot.py
|
||||||
|
ExecStop=/bin/kill -2 $MAINPID
|
||||||
|
Restart=always
|
||||||
|
RestartSec=10s
|
||||||
|
|
||||||
|
[Install]
|
||||||
|
WantedBy=multi-user.target
|
||||||
|
EOF
|
||||||
|
|
||||||
|
systemctl daemon-reload
|
||||||
|
systemctl enable maimbot
|
||||||
|
systemctl start maimbot
|
||||||
|
|
||||||
|
whiptail --title "🎉 安装完成" --msgbox "麦麦Bot安装完成!\n已经启动麦麦Bot服务。\n\n安装路径: $INSTALL_DIR\n分支: $BRANCH" 12 60
|
||||||
@@ -1,50 +1,51 @@
|
|||||||
from typing import Optional
|
import os
|
||||||
|
from typing import cast
|
||||||
from pymongo import MongoClient
|
from pymongo import MongoClient
|
||||||
|
from pymongo.database import Database
|
||||||
|
|
||||||
|
_client = None
|
||||||
|
_db = None
|
||||||
|
|
||||||
|
|
||||||
class Database:
|
def __create_database_instance():
|
||||||
_instance: Optional["Database"] = None
|
uri = os.getenv("MONGODB_URI")
|
||||||
|
host = os.getenv("MONGODB_HOST", "127.0.0.1")
|
||||||
|
port = int(os.getenv("MONGODB_PORT", "27017"))
|
||||||
|
db_name = os.getenv("DATABASE_NAME", "MegBot")
|
||||||
|
username = os.getenv("MONGODB_USERNAME")
|
||||||
|
password = os.getenv("MONGODB_PASSWORD")
|
||||||
|
auth_source = os.getenv("MONGODB_AUTH_SOURCE")
|
||||||
|
|
||||||
|
if uri and uri.startswith("mongodb://"):
|
||||||
|
# 优先使用URI连接
|
||||||
|
return MongoClient(uri)
|
||||||
|
|
||||||
def __init__(self, host: str, port: int, db_name: str, username: Optional[str] = None, password: Optional[str] = None, auth_source: Optional[str] = None):
|
|
||||||
if username and password:
|
if username and password:
|
||||||
# 如果有用户名和密码,使用认证连接
|
# 如果有用户名和密码,使用认证连接
|
||||||
# TODO: 复杂情况直接支持URI吧
|
return MongoClient(host, port, username=username, password=password, authSource=auth_source)
|
||||||
self.client = MongoClient(host, port, username=username, password=password, authSource=auth_source)
|
|
||||||
else:
|
|
||||||
# 否则使用无认证连接
|
# 否则使用无认证连接
|
||||||
self.client = MongoClient(host, port)
|
return MongoClient(host, port)
|
||||||
self.db = self.client[db_name]
|
|
||||||
|
|
||||||
@classmethod
|
|
||||||
def initialize(cls, host: str, port: int, db_name: str, username: Optional[str] = None, password: Optional[str] = None, auth_source: Optional[str] = None) -> "Database":
|
|
||||||
if cls._instance is None:
|
|
||||||
cls._instance = cls(host, port, db_name, username, password, auth_source)
|
|
||||||
return cls._instance
|
|
||||||
|
|
||||||
@classmethod
|
|
||||||
def get_instance(cls) -> "Database":
|
|
||||||
if cls._instance is None:
|
|
||||||
raise RuntimeError("Database not initialized")
|
|
||||||
return cls._instance
|
|
||||||
|
|
||||||
|
|
||||||
#测试用
|
def get_db():
|
||||||
|
"""获取数据库连接实例,延迟初始化。"""
|
||||||
|
global _client, _db
|
||||||
|
if _client is None:
|
||||||
|
_client = __create_database_instance()
|
||||||
|
_db = _client[os.getenv("DATABASE_NAME", "MegBot")]
|
||||||
|
return _db
|
||||||
|
|
||||||
def get_random_group_messages(self, group_id: str, limit: int = 5):
|
|
||||||
# 先随机获取一条消息
|
|
||||||
random_message = list(self.db.messages.aggregate([
|
|
||||||
{"$match": {"group_id": group_id}},
|
|
||||||
{"$sample": {"size": 1}}
|
|
||||||
]))[0]
|
|
||||||
|
|
||||||
# 获取该消息之后的消息
|
class DBWrapper:
|
||||||
subsequent_messages = list(self.db.messages.find({
|
"""数据库代理类,保持接口兼容性同时实现懒加载。"""
|
||||||
"group_id": group_id,
|
|
||||||
"time": {"$gt": random_message["time"]}
|
|
||||||
}).sort("time", 1).limit(limit))
|
|
||||||
|
|
||||||
# 将随机消息和后续消息合并
|
def __getattr__(self, name):
|
||||||
messages = [random_message] + subsequent_messages
|
return getattr(get_db(), name)
|
||||||
|
|
||||||
return messages
|
def __getitem__(self, key):
|
||||||
|
return get_db()[key]
|
||||||
|
|
||||||
|
|
||||||
|
# 全局数据库访问点
|
||||||
|
db: Database = DBWrapper()
|
||||||
|
|||||||
@@ -5,6 +5,9 @@ import threading
|
|||||||
import time
|
import time
|
||||||
from datetime import datetime
|
from datetime import datetime
|
||||||
from typing import Dict, List
|
from typing import Dict, List
|
||||||
|
from loguru import logger
|
||||||
|
from typing import Optional
|
||||||
|
|
||||||
|
|
||||||
import customtkinter as ctk
|
import customtkinter as ctk
|
||||||
from dotenv import load_dotenv
|
from dotenv import load_dotenv
|
||||||
@@ -13,58 +16,25 @@ from dotenv import load_dotenv
|
|||||||
current_dir = os.path.dirname(os.path.abspath(__file__))
|
current_dir = os.path.dirname(os.path.abspath(__file__))
|
||||||
# 获取项目根目录
|
# 获取项目根目录
|
||||||
root_dir = os.path.abspath(os.path.join(current_dir, '..', '..'))
|
root_dir = os.path.abspath(os.path.join(current_dir, '..', '..'))
|
||||||
|
sys.path.insert(0, root_dir)
|
||||||
|
from src.common.database import db
|
||||||
|
|
||||||
# 加载环境变量
|
# 加载环境变量
|
||||||
if os.path.exists(os.path.join(root_dir, '.env.dev')):
|
if os.path.exists(os.path.join(root_dir, '.env.dev')):
|
||||||
load_dotenv(os.path.join(root_dir, '.env.dev'))
|
load_dotenv(os.path.join(root_dir, '.env.dev'))
|
||||||
print("成功加载开发环境配置")
|
logger.info("成功加载开发环境配置")
|
||||||
elif os.path.exists(os.path.join(root_dir, '.env.prod')):
|
elif os.path.exists(os.path.join(root_dir, '.env.prod')):
|
||||||
load_dotenv(os.path.join(root_dir, '.env.prod'))
|
load_dotenv(os.path.join(root_dir, '.env.prod'))
|
||||||
print("成功加载生产环境配置")
|
logger.info("成功加载生产环境配置")
|
||||||
else:
|
else:
|
||||||
print("未找到环境配置文件")
|
logger.error("未找到环境配置文件")
|
||||||
sys.exit(1)
|
sys.exit(1)
|
||||||
|
|
||||||
from typing import Optional
|
|
||||||
|
|
||||||
from pymongo import MongoClient
|
|
||||||
|
|
||||||
|
|
||||||
class Database:
|
|
||||||
_instance: Optional["Database"] = None
|
|
||||||
|
|
||||||
def __init__(self, host: str, port: int, db_name: str, username: str = None, password: str = None, auth_source: str = None):
|
|
||||||
if username and password:
|
|
||||||
self.client = MongoClient(
|
|
||||||
host=host,
|
|
||||||
port=port,
|
|
||||||
username=username,
|
|
||||||
password=password,
|
|
||||||
authSource=auth_source or 'admin'
|
|
||||||
)
|
|
||||||
else:
|
|
||||||
self.client = MongoClient(host, port)
|
|
||||||
self.db = self.client[db_name]
|
|
||||||
|
|
||||||
@classmethod
|
|
||||||
def initialize(cls, host: str, port: int, db_name: str, username: str = None, password: str = None, auth_source: str = None) -> "Database":
|
|
||||||
if cls._instance is None:
|
|
||||||
cls._instance = cls(host, port, db_name, username, password, auth_source)
|
|
||||||
return cls._instance
|
|
||||||
|
|
||||||
@classmethod
|
|
||||||
def get_instance(cls) -> "Database":
|
|
||||||
if cls._instance is None:
|
|
||||||
raise RuntimeError("Database not initialized")
|
|
||||||
return cls._instance
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
class ReasoningGUI:
|
class ReasoningGUI:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
# 记录启动时间戳,转换为Unix时间戳
|
# 记录启动时间戳,转换为Unix时间戳
|
||||||
self.start_timestamp = datetime.now().timestamp()
|
self.start_timestamp = datetime.now().timestamp()
|
||||||
print(f"程序启动时间戳: {self.start_timestamp}")
|
logger.info(f"程序启动时间戳: {self.start_timestamp}")
|
||||||
|
|
||||||
# 设置主题
|
# 设置主题
|
||||||
ctk.set_appearance_mode("dark")
|
ctk.set_appearance_mode("dark")
|
||||||
@@ -76,20 +46,6 @@ class ReasoningGUI:
|
|||||||
self.root.geometry('800x600')
|
self.root.geometry('800x600')
|
||||||
self.root.protocol("WM_DELETE_WINDOW", self._on_closing)
|
self.root.protocol("WM_DELETE_WINDOW", self._on_closing)
|
||||||
|
|
||||||
# 初始化数据库连接
|
|
||||||
try:
|
|
||||||
self.db = Database.get_instance().db
|
|
||||||
print("数据库连接成功")
|
|
||||||
except RuntimeError:
|
|
||||||
print("数据库未初始化,正在尝试初始化...")
|
|
||||||
try:
|
|
||||||
Database.initialize("127.0.0.1", 27017, "maimai_bot")
|
|
||||||
self.db = Database.get_instance().db
|
|
||||||
print("数据库初始化成功")
|
|
||||||
except Exception as e:
|
|
||||||
print(f"数据库初始化失败: {e}")
|
|
||||||
sys.exit(1)
|
|
||||||
|
|
||||||
# 存储群组数据
|
# 存储群组数据
|
||||||
self.group_data: Dict[str, List[dict]] = {}
|
self.group_data: Dict[str, List[dict]] = {}
|
||||||
|
|
||||||
@@ -274,7 +230,7 @@ class ReasoningGUI:
|
|||||||
self.content_text.insert("end", f"{item.get('response', '')}\n", "response")
|
self.content_text.insert("end", f"{item.get('response', '')}\n", "response")
|
||||||
|
|
||||||
# 分隔符
|
# 分隔符
|
||||||
self.content_text.insert("end", f"\n{'='*50}\n\n", "separator")
|
self.content_text.insert("end", f"\n{'=' * 50}\n\n", "separator")
|
||||||
|
|
||||||
# 滚动到顶部
|
# 滚动到顶部
|
||||||
self.content_text.see("1.0")
|
self.content_text.see("1.0")
|
||||||
@@ -285,21 +241,21 @@ class ReasoningGUI:
|
|||||||
try:
|
try:
|
||||||
# 从数据库获取最新数据,只获取启动时间之后的记录
|
# 从数据库获取最新数据,只获取启动时间之后的记录
|
||||||
query = {"time": {"$gt": self.start_timestamp}}
|
query = {"time": {"$gt": self.start_timestamp}}
|
||||||
print(f"查询条件: {query}")
|
logger.debug(f"查询条件: {query}")
|
||||||
|
|
||||||
# 先获取一条记录检查时间格式
|
# 先获取一条记录检查时间格式
|
||||||
sample = self.db.reasoning_logs.find_one()
|
sample = db.reasoning_logs.find_one()
|
||||||
if sample:
|
if sample:
|
||||||
print(f"样本记录时间格式: {type(sample['time'])} 值: {sample['time']}")
|
logger.debug(f"样本记录时间格式: {type(sample['time'])} 值: {sample['time']}")
|
||||||
|
|
||||||
cursor = self.db.reasoning_logs.find(query).sort("time", -1)
|
cursor = db.reasoning_logs.find(query).sort("time", -1)
|
||||||
new_data = {}
|
new_data = {}
|
||||||
total_count = 0
|
total_count = 0
|
||||||
|
|
||||||
for item in cursor:
|
for item in cursor:
|
||||||
# 调试输出
|
# 调试输出
|
||||||
if total_count == 0:
|
if total_count == 0:
|
||||||
print(f"记录时间: {item['time']}, 类型: {type(item['time'])}")
|
logger.debug(f"记录时间: {item['time']}, 类型: {type(item['time'])}")
|
||||||
|
|
||||||
total_count += 1
|
total_count += 1
|
||||||
group_id = str(item.get('group_id', 'unknown'))
|
group_id = str(item.get('group_id', 'unknown'))
|
||||||
@@ -312,7 +268,7 @@ class ReasoningGUI:
|
|||||||
elif isinstance(item['time'], datetime):
|
elif isinstance(item['time'], datetime):
|
||||||
time_obj = item['time']
|
time_obj = item['time']
|
||||||
else:
|
else:
|
||||||
print(f"未知的时间格式: {type(item['time'])}")
|
logger.warning(f"未知的时间格式: {type(item['time'])}")
|
||||||
time_obj = datetime.now() # 使用当前时间作为后备
|
time_obj = datetime.now() # 使用当前时间作为后备
|
||||||
|
|
||||||
new_data[group_id].append({
|
new_data[group_id].append({
|
||||||
@@ -325,12 +281,12 @@ class ReasoningGUI:
|
|||||||
'prompt': item.get('prompt', '') # 添加prompt字段
|
'prompt': item.get('prompt', '') # 添加prompt字段
|
||||||
})
|
})
|
||||||
|
|
||||||
print(f"从数据库加载了 {total_count} 条记录,分布在 {len(new_data)} 个群组中")
|
logger.info(f"从数据库加载了 {total_count} 条记录,分布在 {len(new_data)} 个群组中")
|
||||||
|
|
||||||
# 更新数据
|
# 更新数据
|
||||||
if new_data != self.group_data:
|
if new_data != self.group_data:
|
||||||
self.group_data = new_data
|
self.group_data = new_data
|
||||||
print("数据已更新,正在刷新显示...")
|
logger.info("数据已更新,正在刷新显示...")
|
||||||
# 将更新任务添加到队列
|
# 将更新任务添加到队列
|
||||||
self.update_queue.put({'type': 'update_group_list'})
|
self.update_queue.put({'type': 'update_group_list'})
|
||||||
if self.group_data:
|
if self.group_data:
|
||||||
@@ -341,8 +297,8 @@ class ReasoningGUI:
|
|||||||
'type': 'update_display',
|
'type': 'update_display',
|
||||||
'group_id': self.selected_group_id
|
'group_id': self.selected_group_id
|
||||||
})
|
})
|
||||||
except Exception as e:
|
except Exception:
|
||||||
print(f"自动更新出错: {e}")
|
logger.exception("自动更新出错")
|
||||||
|
|
||||||
# 每5秒更新一次
|
# 每5秒更新一次
|
||||||
time.sleep(5)
|
time.sleep(5)
|
||||||
@@ -357,20 +313,9 @@ class ReasoningGUI:
|
|||||||
|
|
||||||
|
|
||||||
def main():
|
def main():
|
||||||
"""主函数"""
|
|
||||||
Database.initialize(
|
|
||||||
host= os.getenv("MONGODB_HOST"),
|
|
||||||
port= int(os.getenv("MONGODB_PORT")),
|
|
||||||
db_name= os.getenv("DATABASE_NAME"),
|
|
||||||
username= os.getenv("MONGODB_USERNAME"),
|
|
||||||
password= os.getenv("MONGODB_PASSWORD"),
|
|
||||||
auth_source=os.getenv("MONGODB_AUTH_SOURCE")
|
|
||||||
)
|
|
||||||
|
|
||||||
app = ReasoningGUI()
|
app = ReasoningGUI()
|
||||||
app.run()
|
app.run()
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
if __name__ == "__main__":
|
if __name__ == "__main__":
|
||||||
main()
|
main()
|
||||||
|
|||||||
@@ -1,13 +1,13 @@
|
|||||||
import asyncio
|
import asyncio
|
||||||
import time
|
import time
|
||||||
|
import os
|
||||||
|
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
from nonebot import get_driver, on_command, on_message, require
|
from nonebot import get_driver, on_message, on_notice, require
|
||||||
from nonebot.adapters.onebot.v11 import Bot, GroupMessageEvent, Message, MessageSegment
|
|
||||||
from nonebot.rule import to_me
|
from nonebot.rule import to_me
|
||||||
|
from nonebot.adapters.onebot.v11 import Bot, GroupMessageEvent, Message, MessageSegment, MessageEvent, NoticeEvent
|
||||||
from nonebot.typing import T_State
|
from nonebot.typing import T_State
|
||||||
|
|
||||||
from ...common.database import Database
|
|
||||||
from ..moods.moods import MoodManager # 导入情绪管理器
|
from ..moods.moods import MoodManager # 导入情绪管理器
|
||||||
from ..schedule.schedule_generator import bot_schedule
|
from ..schedule.schedule_generator import bot_schedule
|
||||||
from ..utils.statistic import LLMStatistics
|
from ..utils.statistic import LLMStatistics
|
||||||
@@ -16,6 +16,11 @@ from .config import global_config
|
|||||||
from .emoji_manager import emoji_manager
|
from .emoji_manager import emoji_manager
|
||||||
from .relationship_manager import relationship_manager
|
from .relationship_manager import relationship_manager
|
||||||
from .willing_manager import willing_manager
|
from .willing_manager import willing_manager
|
||||||
|
from .chat_stream import chat_manager
|
||||||
|
from ..memory_system.memory import hippocampus, memory_graph
|
||||||
|
from .bot import ChatBot
|
||||||
|
from .message_sender import message_manager, message_sender
|
||||||
|
|
||||||
|
|
||||||
# 创建LLM统计实例
|
# 创建LLM统计实例
|
||||||
llm_stats = LLMStatistics("llm_statistics.txt")
|
llm_stats = LLMStatistics("llm_statistics.txt")
|
||||||
@@ -27,31 +32,16 @@ _message_manager_started = False
|
|||||||
driver = get_driver()
|
driver = get_driver()
|
||||||
config = driver.config
|
config = driver.config
|
||||||
|
|
||||||
Database.initialize(
|
|
||||||
host=config.MONGODB_HOST,
|
|
||||||
port=int(config.MONGODB_PORT),
|
|
||||||
db_name=config.DATABASE_NAME,
|
|
||||||
username=config.MONGODB_USERNAME,
|
|
||||||
password=config.MONGODB_PASSWORD,
|
|
||||||
auth_source=config.MONGODB_AUTH_SOURCE
|
|
||||||
)
|
|
||||||
print("\033[1;32m[初始化数据库完成]\033[0m")
|
|
||||||
|
|
||||||
# 导入其他模块
|
|
||||||
from ..memory_system.memory import hippocampus, memory_graph
|
|
||||||
from .bot import ChatBot
|
|
||||||
|
|
||||||
# from .message_send_control import message_sender
|
|
||||||
from .message_sender import message_manager, message_sender
|
|
||||||
|
|
||||||
# 初始化表情管理器
|
# 初始化表情管理器
|
||||||
emoji_manager.initialize()
|
emoji_manager.initialize()
|
||||||
|
|
||||||
print(f"\033[1;32m正在唤醒{global_config.BOT_NICKNAME}......\033[0m")
|
logger.debug(f"正在唤醒{global_config.BOT_NICKNAME}......")
|
||||||
# 创建机器人实例
|
# 创建机器人实例
|
||||||
chat_bot = ChatBot()
|
chat_bot = ChatBot()
|
||||||
# 注册群消息处理器
|
# 注册消息处理器
|
||||||
group_msg = on_message(priority=5)
|
msg_in = on_message(priority=5)
|
||||||
|
# 注册和bot相关的通知处理器
|
||||||
|
notice_matcher = on_notice(priority=1)
|
||||||
# 创建定时任务
|
# 创建定时任务
|
||||||
scheduler = require("nonebot_plugin_apscheduler").scheduler
|
scheduler = require("nonebot_plugin_apscheduler").scheduler
|
||||||
|
|
||||||
@@ -61,12 +51,12 @@ async def start_background_tasks():
|
|||||||
"""启动后台任务"""
|
"""启动后台任务"""
|
||||||
# 启动LLM统计
|
# 启动LLM统计
|
||||||
llm_stats.start()
|
llm_stats.start()
|
||||||
logger.success("[初始化]LLM统计功能已启动")
|
logger.success("LLM统计功能启动成功")
|
||||||
|
|
||||||
# 初始化并启动情绪管理器
|
# 初始化并启动情绪管理器
|
||||||
mood_manager = MoodManager.get_instance()
|
mood_manager = MoodManager.get_instance()
|
||||||
mood_manager.start_mood_update(update_interval=global_config.mood_update_interval)
|
mood_manager.start_mood_update(update_interval=global_config.mood_update_interval)
|
||||||
logger.success("[初始化]情绪管理器已启动")
|
logger.success("情绪管理器启动成功")
|
||||||
|
|
||||||
# 只启动表情包管理任务
|
# 只启动表情包管理任务
|
||||||
asyncio.create_task(emoji_manager.start_periodic_check(interval_MINS=global_config.EMOJI_CHECK_INTERVAL))
|
asyncio.create_task(emoji_manager.start_periodic_check(interval_MINS=global_config.EMOJI_CHECK_INTERVAL))
|
||||||
@@ -77,7 +67,7 @@ async def start_background_tasks():
|
|||||||
@driver.on_startup
|
@driver.on_startup
|
||||||
async def init_relationships():
|
async def init_relationships():
|
||||||
"""在 NoneBot2 启动时初始化关系管理器"""
|
"""在 NoneBot2 启动时初始化关系管理器"""
|
||||||
print("\033[1;32m[初始化]\033[0m 正在加载用户关系数据...")
|
logger.debug("正在加载用户关系数据...")
|
||||||
await relationship_manager.load_all_relationships()
|
await relationship_manager.load_all_relationships()
|
||||||
asyncio.create_task(relationship_manager._start_relationship_manager())
|
asyncio.create_task(relationship_manager._start_relationship_manager())
|
||||||
|
|
||||||
@@ -86,45 +76,54 @@ async def init_relationships():
|
|||||||
async def _(bot: Bot):
|
async def _(bot: Bot):
|
||||||
"""Bot连接成功时的处理"""
|
"""Bot连接成功时的处理"""
|
||||||
global _message_manager_started
|
global _message_manager_started
|
||||||
print(f"\033[1;38;5;208m-----------{global_config.BOT_NICKNAME}成功连接!-----------\033[0m")
|
logger.debug(f"-----------{global_config.BOT_NICKNAME}成功连接!-----------")
|
||||||
await willing_manager.ensure_started()
|
await willing_manager.ensure_started()
|
||||||
|
|
||||||
message_sender.set_bot(bot)
|
message_sender.set_bot(bot)
|
||||||
print("\033[1;38;5;208m-----------消息发送器已启动!-----------\033[0m")
|
logger.success("-----------消息发送器已启动!-----------")
|
||||||
|
|
||||||
if not _message_manager_started:
|
if not _message_manager_started:
|
||||||
asyncio.create_task(message_manager.start_processor())
|
asyncio.create_task(message_manager.start_processor())
|
||||||
_message_manager_started = True
|
_message_manager_started = True
|
||||||
print("\033[1;38;5;208m-----------消息处理器已启动!-----------\033[0m")
|
logger.success("-----------消息处理器已启动!-----------")
|
||||||
|
|
||||||
asyncio.create_task(emoji_manager._periodic_scan(interval_MINS=global_config.EMOJI_REGISTER_INTERVAL))
|
asyncio.create_task(emoji_manager._periodic_scan(interval_MINS=global_config.EMOJI_REGISTER_INTERVAL))
|
||||||
print("\033[1;38;5;208m-----------开始偷表情包!-----------\033[0m")
|
logger.success("-----------开始偷表情包!-----------")
|
||||||
|
asyncio.create_task(chat_manager._initialize())
|
||||||
|
asyncio.create_task(chat_manager._auto_save_task())
|
||||||
|
|
||||||
|
|
||||||
@group_msg.handle()
|
@msg_in.handle()
|
||||||
async def _(bot: Bot, event: GroupMessageEvent, state: T_State):
|
async def _(bot: Bot, event: MessageEvent, state: T_State):
|
||||||
await chat_bot.handle_message(event, bot)
|
await chat_bot.handle_message(event, bot)
|
||||||
|
|
||||||
|
|
||||||
|
@notice_matcher.handle()
|
||||||
|
async def _(bot: Bot, event: NoticeEvent, state: T_State):
|
||||||
|
logger.debug(f"收到通知:{event}")
|
||||||
|
await chat_bot.handle_notice(event, bot)
|
||||||
|
|
||||||
|
|
||||||
# 添加build_memory定时任务
|
# 添加build_memory定时任务
|
||||||
@scheduler.scheduled_job("interval", seconds=global_config.build_memory_interval, id="build_memory")
|
@scheduler.scheduled_job("interval", seconds=global_config.build_memory_interval, id="build_memory")
|
||||||
async def build_memory_task():
|
async def build_memory_task():
|
||||||
"""每build_memory_interval秒执行一次记忆构建"""
|
"""每build_memory_interval秒执行一次记忆构建"""
|
||||||
print(
|
logger.debug("[记忆构建]------------------------------------开始构建记忆--------------------------------------")
|
||||||
"\033[1;32m[记忆构建]\033[0m -------------------------------------------开始构建记忆-------------------------------------------")
|
|
||||||
start_time = time.time()
|
start_time = time.time()
|
||||||
await hippocampus.operation_build_memory(chat_size=20)
|
await hippocampus.operation_build_memory(chat_size=20)
|
||||||
end_time = time.time()
|
end_time = time.time()
|
||||||
print(
|
logger.success(
|
||||||
f"\033[1;32m[记忆构建]\033[0m -------------------------------------------记忆构建完成:耗时: {end_time - start_time:.2f} 秒-------------------------------------------")
|
f"[记忆构建]--------------------------记忆构建完成:耗时: {end_time - start_time:.2f} "
|
||||||
|
"秒-------------------------------------------"
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
@scheduler.scheduled_job("interval", seconds=global_config.forget_memory_interval, id="forget_memory")
|
@scheduler.scheduled_job("interval", seconds=global_config.forget_memory_interval, id="forget_memory")
|
||||||
async def forget_memory_task():
|
async def forget_memory_task():
|
||||||
"""每30秒执行一次记忆构建"""
|
"""每30秒执行一次记忆构建"""
|
||||||
# print("\033[1;32m[记忆遗忘]\033[0m 开始遗忘记忆...")
|
print("\033[1;32m[记忆遗忘]\033[0m 开始遗忘记忆...")
|
||||||
# await hippocampus.operation_forget_topic(percentage=0.1)
|
await hippocampus.operation_forget_topic(percentage=global_config.memory_forget_percentage)
|
||||||
# print("\033[1;32m[记忆遗忘]\033[0m 记忆遗忘完成")
|
print("\033[1;32m[记忆遗忘]\033[0m 记忆遗忘完成")
|
||||||
|
|
||||||
|
|
||||||
@scheduler.scheduled_job("interval", seconds=global_config.build_memory_interval + 10, id="merge_memory")
|
@scheduler.scheduled_job("interval", seconds=global_config.build_memory_interval + 10, id="merge_memory")
|
||||||
@@ -140,3 +139,12 @@ async def print_mood_task():
|
|||||||
"""每30秒打印一次情绪状态"""
|
"""每30秒打印一次情绪状态"""
|
||||||
mood_manager = MoodManager.get_instance()
|
mood_manager = MoodManager.get_instance()
|
||||||
mood_manager.print_mood_status()
|
mood_manager.print_mood_status()
|
||||||
|
|
||||||
|
|
||||||
|
@scheduler.scheduled_job("interval", seconds=7200, id="generate_schedule")
|
||||||
|
async def generate_schedule_task():
|
||||||
|
"""每2小时尝试生成一次日程"""
|
||||||
|
logger.debug("尝试生成日程")
|
||||||
|
await bot_schedule.initialize()
|
||||||
|
if not bot_schedule.enable_output:
|
||||||
|
bot_schedule.print_schedule()
|
||||||
|
|||||||
@@ -1,26 +1,35 @@
|
|||||||
|
import re
|
||||||
import time
|
import time
|
||||||
from random import random
|
from random import random
|
||||||
|
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
from nonebot.adapters.onebot.v11 import Bot, GroupMessageEvent
|
from nonebot.adapters.onebot.v11 import (
|
||||||
|
Bot,
|
||||||
|
GroupMessageEvent,
|
||||||
|
MessageEvent,
|
||||||
|
PrivateMessageEvent,
|
||||||
|
NoticeEvent,
|
||||||
|
PokeNotifyEvent,
|
||||||
|
)
|
||||||
|
|
||||||
from ..memory_system.memory import hippocampus
|
from ..memory_system.memory import hippocampus
|
||||||
from ..moods.moods import MoodManager # 导入情绪管理器
|
from ..moods.moods import MoodManager # 导入情绪管理器
|
||||||
from .config import global_config
|
from .config import global_config
|
||||||
from .cq_code import CQCode # 导入CQCode模块
|
|
||||||
from .emoji_manager import emoji_manager # 导入表情包管理器
|
from .emoji_manager import emoji_manager # 导入表情包管理器
|
||||||
from .llm_generator import ResponseGenerator
|
from .llm_generator import ResponseGenerator
|
||||||
from .message import (
|
from .message import MessageSending, MessageRecv, MessageThinking, MessageSet
|
||||||
Message,
|
from .message_cq import (
|
||||||
Message_Sending,
|
MessageRecvCQ,
|
||||||
Message_Thinking, # 导入 Message_Thinking 类
|
|
||||||
MessageSet,
|
|
||||||
)
|
)
|
||||||
|
from .chat_stream import chat_manager
|
||||||
|
|
||||||
from .message_sender import message_manager # 导入新的消息管理器
|
from .message_sender import message_manager # 导入新的消息管理器
|
||||||
from .relationship_manager import relationship_manager
|
from .relationship_manager import relationship_manager
|
||||||
from .storage import MessageStorage
|
from .storage import MessageStorage
|
||||||
from .utils import calculate_typing_time, is_mentioned_bot_in_txt
|
from .utils import calculate_typing_time, is_mentioned_bot_in_message
|
||||||
|
from .utils_image import image_path_to_base64
|
||||||
|
from .utils_user import get_user_nickname, get_user_cardname, get_groupname
|
||||||
from .willing_manager import willing_manager # 导入意愿管理器
|
from .willing_manager import willing_manager # 导入意愿管理器
|
||||||
|
from .message_base import UserInfo, GroupInfo, Seg
|
||||||
|
|
||||||
|
|
||||||
class ChatBot:
|
class ChatBot:
|
||||||
@@ -40,187 +49,328 @@ class ChatBot:
|
|||||||
if not self._started:
|
if not self._started:
|
||||||
self._started = True
|
self._started = True
|
||||||
|
|
||||||
async def handle_message(self, event: GroupMessageEvent, bot: Bot) -> None:
|
async def handle_notice(self, event: NoticeEvent, bot: Bot) -> None:
|
||||||
"""处理收到的群消息"""
|
"""处理收到的通知"""
|
||||||
|
# 戳一戳通知
|
||||||
if event.group_id not in global_config.talk_allowed_groups:
|
if isinstance(event, PokeNotifyEvent):
|
||||||
|
# 用户屏蔽,不区分私聊/群聊
|
||||||
|
if event.user_id in global_config.ban_user_id:
|
||||||
return
|
return
|
||||||
|
reply_poke_probability = 1 # 回复戳一戳的概率
|
||||||
|
|
||||||
|
if random() < reply_poke_probability:
|
||||||
|
user_info = UserInfo(
|
||||||
|
user_id=event.user_id,
|
||||||
|
user_nickname=get_user_nickname(event.user_id) or None,
|
||||||
|
user_cardname=get_user_cardname(event.user_id) or None,
|
||||||
|
platform="qq",
|
||||||
|
)
|
||||||
|
group_info = GroupInfo(group_id=event.group_id, group_name=None, platform="qq")
|
||||||
|
message_cq = MessageRecvCQ(
|
||||||
|
message_id=None,
|
||||||
|
user_info=user_info,
|
||||||
|
raw_message=str("[戳了戳]你"),
|
||||||
|
group_info=group_info,
|
||||||
|
reply_message=None,
|
||||||
|
platform="qq",
|
||||||
|
)
|
||||||
|
message_json = message_cq.to_dict()
|
||||||
|
|
||||||
|
# 进入maimbot
|
||||||
|
message = MessageRecv(message_json)
|
||||||
|
groupinfo = message.message_info.group_info
|
||||||
|
userinfo = message.message_info.user_info
|
||||||
|
messageinfo = message.message_info
|
||||||
|
|
||||||
|
chat = await chat_manager.get_or_create_stream(
|
||||||
|
platform=messageinfo.platform, user_info=userinfo, group_info=groupinfo
|
||||||
|
)
|
||||||
|
message.update_chat_stream(chat)
|
||||||
|
await message.process()
|
||||||
|
|
||||||
|
bot_user_info = UserInfo(
|
||||||
|
user_id=global_config.BOT_QQ,
|
||||||
|
user_nickname=global_config.BOT_NICKNAME,
|
||||||
|
platform=messageinfo.platform,
|
||||||
|
)
|
||||||
|
|
||||||
|
response, raw_content = await self.gpt.generate_response(message)
|
||||||
|
|
||||||
|
if response:
|
||||||
|
for msg in response:
|
||||||
|
message_segment = Seg(type="text", data=msg)
|
||||||
|
|
||||||
|
bot_message = MessageSending(
|
||||||
|
message_id=None,
|
||||||
|
chat_stream=chat,
|
||||||
|
bot_user_info=bot_user_info,
|
||||||
|
sender_info=userinfo,
|
||||||
|
message_segment=message_segment,
|
||||||
|
reply=None,
|
||||||
|
is_head=False,
|
||||||
|
is_emoji=False,
|
||||||
|
)
|
||||||
|
message_manager.add_message(bot_message)
|
||||||
|
|
||||||
|
async def handle_message(self, event: MessageEvent, bot: Bot) -> None:
|
||||||
|
"""处理收到的消息"""
|
||||||
|
|
||||||
self.bot = bot # 更新 bot 实例
|
self.bot = bot # 更新 bot 实例
|
||||||
|
|
||||||
|
# 用户屏蔽,不区分私聊/群聊
|
||||||
if event.user_id in global_config.ban_user_id:
|
if event.user_id in global_config.ban_user_id:
|
||||||
return
|
return
|
||||||
|
|
||||||
group_info = await bot.get_group_info(group_id=event.group_id)
|
if event.reply and hasattr(event.reply, 'sender') and hasattr(event.reply.sender, 'user_id') and event.reply.sender.user_id in global_config.ban_user_id:
|
||||||
sender_info = await bot.get_group_member_info(group_id=event.group_id, user_id=event.user_id, no_cache=True)
|
logger.debug(f"跳过处理回复来自被ban用户 {event.reply.sender.user_id} 的消息")
|
||||||
|
return
|
||||||
await relationship_manager.update_relationship(user_id = event.user_id, data = sender_info)
|
# 处理私聊消息
|
||||||
await relationship_manager.update_relationship_value(user_id = event.user_id, relationship_value = 0.5)
|
if isinstance(event, PrivateMessageEvent):
|
||||||
|
if not global_config.enable_friend_chat: # 私聊过滤
|
||||||
message = Message(
|
return
|
||||||
group_id=event.group_id,
|
else:
|
||||||
|
try:
|
||||||
|
user_info = UserInfo(
|
||||||
user_id=event.user_id,
|
user_id=event.user_id,
|
||||||
message_id=event.message_id,
|
user_nickname=(await bot.get_stranger_info(user_id=event.user_id, no_cache=True))["nickname"],
|
||||||
user_cardname=sender_info['card'],
|
user_cardname=None,
|
||||||
raw_message=str(event.original_message),
|
platform="qq",
|
||||||
plain_text=event.get_plaintext(),
|
|
||||||
reply_message=event.reply,
|
|
||||||
)
|
)
|
||||||
await message.initialize()
|
except Exception as e:
|
||||||
|
logger.error(f"获取陌生人信息失败: {e}")
|
||||||
|
return
|
||||||
|
logger.debug(user_info)
|
||||||
|
|
||||||
# 过滤词
|
# group_info = GroupInfo(group_id=0, group_name="私聊", platform="qq")
|
||||||
for word in global_config.ban_words:
|
group_info = None
|
||||||
if word in message.detailed_plain_text:
|
|
||||||
logger.info(f"\033[1;32m[{message.group_name}]{message.user_nickname}:\033[0m {message.processed_plain_text}")
|
# 处理群聊消息
|
||||||
logger.info(f"\033[1;32m[过滤词识别]\033[0m 消息中含有{word},filtered")
|
else:
|
||||||
|
# 白名单设定由nontbot侧完成
|
||||||
|
if event.group_id:
|
||||||
|
if event.group_id not in global_config.talk_allowed_groups:
|
||||||
return
|
return
|
||||||
|
|
||||||
current_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(message.time))
|
user_info = UserInfo(
|
||||||
|
user_id=event.user_id,
|
||||||
|
user_nickname=event.sender.nickname,
|
||||||
|
user_cardname=event.sender.card or None,
|
||||||
|
platform="qq",
|
||||||
|
)
|
||||||
|
|
||||||
|
group_info = GroupInfo(group_id=event.group_id, group_name=None, platform="qq")
|
||||||
|
|
||||||
|
# group_info = await bot.get_group_info(group_id=event.group_id)
|
||||||
|
# sender_info = await bot.get_group_member_info(group_id=event.group_id, user_id=event.user_id, no_cache=True)
|
||||||
|
|
||||||
|
message_cq = MessageRecvCQ(
|
||||||
|
message_id=event.message_id,
|
||||||
|
user_info=user_info,
|
||||||
|
raw_message=str(event.original_message),
|
||||||
|
group_info=group_info,
|
||||||
|
reply_message=event.reply,
|
||||||
|
platform="qq",
|
||||||
|
)
|
||||||
|
message_json = message_cq.to_dict()
|
||||||
|
|
||||||
|
# 进入maimbot
|
||||||
|
message = MessageRecv(message_json)
|
||||||
|
groupinfo = message.message_info.group_info
|
||||||
|
userinfo = message.message_info.user_info
|
||||||
|
messageinfo = message.message_info
|
||||||
|
|
||||||
|
# 消息过滤,涉及到config有待更新
|
||||||
|
|
||||||
|
chat = await chat_manager.get_or_create_stream(
|
||||||
|
platform=messageinfo.platform, user_info=userinfo, group_info=groupinfo
|
||||||
|
)
|
||||||
|
message.update_chat_stream(chat)
|
||||||
|
await relationship_manager.update_relationship(
|
||||||
|
chat_stream=chat,
|
||||||
|
)
|
||||||
|
await relationship_manager.update_relationship_value(chat_stream=chat, relationship_value=0.5)
|
||||||
|
|
||||||
|
await message.process()
|
||||||
|
# 过滤词
|
||||||
|
for word in global_config.ban_words:
|
||||||
|
if word in message.processed_plain_text:
|
||||||
|
logger.info(
|
||||||
|
f"[{chat.group_info.group_name if chat.group_info else '私聊'}]{userinfo.user_nickname}:{message.processed_plain_text}"
|
||||||
|
)
|
||||||
|
logger.info(f"[过滤词识别]消息中含有{word},filtered")
|
||||||
|
return
|
||||||
|
|
||||||
|
# 正则表达式过滤
|
||||||
|
for pattern in global_config.ban_msgs_regex:
|
||||||
|
if re.search(pattern, message.raw_message):
|
||||||
|
logger.info(
|
||||||
|
f"[{chat.group_info.group_name if chat.group_info else '私聊'}]{userinfo.user_nickname}:{message.raw_message}"
|
||||||
|
)
|
||||||
|
logger.info(f"[正则表达式过滤]消息匹配到{pattern},filtered")
|
||||||
|
return
|
||||||
|
|
||||||
|
current_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(messageinfo.time))
|
||||||
|
|
||||||
# topic=await topic_identifier.identify_topic_llm(message.processed_plain_text)
|
# topic=await topic_identifier.identify_topic_llm(message.processed_plain_text)
|
||||||
topic = ''
|
|
||||||
interested_rate = 0
|
topic = ""
|
||||||
interested_rate = await hippocampus.memory_activate_value(message.processed_plain_text)/100
|
interested_rate = await hippocampus.memory_activate_value(message.processed_plain_text) / 100
|
||||||
print(f"\033[1;32m[记忆激活]\033[0m 对{message.processed_plain_text}的激活度:---------------------------------------{interested_rate}\n")
|
logger.debug(f"对{message.processed_plain_text}的激活度:{interested_rate}")
|
||||||
# logger.info(f"\033[1;32m[主题识别]\033[0m 使用{global_config.topic_extract}主题: {topic}")
|
# logger.info(f"\033[1;32m[主题识别]\033[0m 使用{global_config.topic_extract}主题: {topic}")
|
||||||
|
|
||||||
await self.storage.store_message(message, topic[0] if topic else None)
|
await self.storage.store_message(message, chat, topic[0] if topic else None)
|
||||||
|
|
||||||
is_mentioned = is_mentioned_bot_in_txt(message.processed_plain_text)
|
is_mentioned = is_mentioned_bot_in_message(message)
|
||||||
reply_probability = willing_manager.change_reply_willing_received(
|
reply_probability = await willing_manager.change_reply_willing_received(
|
||||||
event.group_id,
|
chat_stream=chat,
|
||||||
topic[0] if topic else None,
|
topic=topic[0] if topic else None,
|
||||||
is_mentioned,
|
is_mentioned_bot=is_mentioned,
|
||||||
global_config,
|
config=global_config,
|
||||||
event.user_id,
|
is_emoji=message.is_emoji,
|
||||||
message.is_emoji,
|
interested_rate=interested_rate,
|
||||||
interested_rate
|
sender_id=str(message.message_info.user_info.user_id),
|
||||||
)
|
)
|
||||||
current_willing = willing_manager.get_willing(event.group_id)
|
current_willing = willing_manager.get_willing(chat_stream=chat)
|
||||||
|
|
||||||
|
logger.info(
|
||||||
|
f"[{current_time}][{chat.group_info.group_name if chat.group_info else '私聊'}]{chat.user_info.user_nickname}:"
|
||||||
|
f"{message.processed_plain_text}[回复意愿:{current_willing:.2f}][概率:{reply_probability * 100:.1f}%]"
|
||||||
|
)
|
||||||
|
|
||||||
print(f"\033[1;32m[{current_time}][{message.group_name}]{message.user_nickname}:\033[0m {message.processed_plain_text}\033[1;36m[回复意愿:{current_willing:.2f}][概率:{reply_probability * 100:.1f}%]\033[0m")
|
response = None
|
||||||
|
|
||||||
response = ""
|
|
||||||
|
|
||||||
if random() < reply_probability:
|
if random() < reply_probability:
|
||||||
|
bot_user_info = UserInfo(
|
||||||
|
user_id=global_config.BOT_QQ,
|
||||||
tinking_time_point = round(time.time(), 2)
|
user_nickname=global_config.BOT_NICKNAME,
|
||||||
think_id = 'mt' + str(tinking_time_point)
|
platform=messageinfo.platform,
|
||||||
thinking_message = Message_Thinking(message=message,message_id=think_id)
|
)
|
||||||
|
thinking_time_point = round(time.time(), 2)
|
||||||
|
think_id = "mt" + str(thinking_time_point)
|
||||||
|
thinking_message = MessageThinking(
|
||||||
|
message_id=think_id,
|
||||||
|
chat_stream=chat,
|
||||||
|
bot_user_info=bot_user_info,
|
||||||
|
reply=message,
|
||||||
|
)
|
||||||
|
|
||||||
message_manager.add_message(thinking_message)
|
message_manager.add_message(thinking_message)
|
||||||
|
|
||||||
willing_manager.change_reply_willing_sent(thinking_message.group_id)
|
willing_manager.change_reply_willing_sent(chat)
|
||||||
|
|
||||||
response,raw_content = await self.gpt.generate_response(message)
|
response, raw_content = await self.gpt.generate_response(message)
|
||||||
|
else:
|
||||||
|
# 决定不回复时,也更新回复意愿
|
||||||
|
willing_manager.change_reply_willing_not_sent(chat)
|
||||||
|
|
||||||
|
# print(f"response: {response}")
|
||||||
if response:
|
if response:
|
||||||
container = message_manager.get_container(event.group_id)
|
# print(f"有response: {response}")
|
||||||
|
container = message_manager.get_container(chat.stream_id)
|
||||||
thinking_message = None
|
thinking_message = None
|
||||||
# 找到message,删除
|
# 找到message,删除
|
||||||
|
# print(f"开始找思考消息")
|
||||||
for msg in container.messages:
|
for msg in container.messages:
|
||||||
if isinstance(msg, Message_Thinking) and msg.message_id == think_id:
|
if isinstance(msg, MessageThinking) and msg.message_info.message_id == think_id:
|
||||||
|
# print(f"找到思考消息: {msg}")
|
||||||
thinking_message = msg
|
thinking_message = msg
|
||||||
container.messages.remove(msg)
|
container.messages.remove(msg)
|
||||||
# print(f"\033[1;32m[思考消息删除]\033[0m 已找到思考消息对象,开始删除")
|
|
||||||
break
|
break
|
||||||
|
|
||||||
# 如果找不到思考消息,直接返回
|
# 如果找不到思考消息,直接返回
|
||||||
if not thinking_message:
|
if not thinking_message:
|
||||||
print(f"\033[1;33m[警告]\033[0m 未找到对应的思考消息,可能已超时被移除")
|
logger.warning("未找到对应的思考消息,可能已超时被移除")
|
||||||
return
|
return
|
||||||
|
|
||||||
#记录开始思考的时间,避免从思考到回复的时间太久
|
# 记录开始思考的时间,避免从思考到回复的时间太久
|
||||||
thinking_start_time = thinking_message.thinking_start_time
|
thinking_start_time = thinking_message.thinking_start_time
|
||||||
message_set = MessageSet(event.group_id, global_config.BOT_QQ, think_id) # 发送消息的id和产生发送消息的message_thinking是一致的
|
message_set = MessageSet(chat, think_id)
|
||||||
#计算打字时间,1是为了模拟打字,2是避免多条回复乱序
|
# 计算打字时间,1是为了模拟打字,2是避免多条回复乱序
|
||||||
accu_typing_time = 0
|
accu_typing_time = 0
|
||||||
|
|
||||||
# print(f"\033[1;32m[开始回复]\033[0m 开始将回复1载入发送容器")
|
|
||||||
mark_head = False
|
mark_head = False
|
||||||
for msg in response:
|
for msg in response:
|
||||||
# print(f"\033[1;32m[回复内容]\033[0m {msg}")
|
# print(f"\033[1;32m[回复内容]\033[0m {msg}")
|
||||||
#通过时间改变时间戳
|
# 通过时间改变时间戳
|
||||||
typing_time = calculate_typing_time(msg)
|
typing_time = calculate_typing_time(msg)
|
||||||
|
logger.debug(f"typing_time: {typing_time}")
|
||||||
accu_typing_time += typing_time
|
accu_typing_time += typing_time
|
||||||
timepoint = tinking_time_point + accu_typing_time
|
timepoint = thinking_time_point + accu_typing_time
|
||||||
|
message_segment = Seg(type="text", data=msg)
|
||||||
bot_message = Message_Sending(
|
# logger.debug(f"message_segment: {message_segment}")
|
||||||
group_id=event.group_id,
|
bot_message = MessageSending(
|
||||||
user_id=global_config.BOT_QQ,
|
|
||||||
message_id=think_id,
|
message_id=think_id,
|
||||||
raw_message=msg,
|
chat_stream=chat,
|
||||||
plain_text=msg,
|
bot_user_info=bot_user_info,
|
||||||
processed_plain_text=msg,
|
sender_info=userinfo,
|
||||||
user_nickname=global_config.BOT_NICKNAME,
|
message_segment=message_segment,
|
||||||
group_name=message.group_name,
|
reply=message,
|
||||||
time=timepoint, #记录了回复生成的时间
|
is_head=not mark_head,
|
||||||
thinking_start_time=thinking_start_time, #记录了思考开始的时间
|
is_emoji=False,
|
||||||
reply_message_id=message.message_id
|
|
||||||
)
|
)
|
||||||
await bot_message.initialize()
|
logger.debug(f"bot_message: {bot_message}")
|
||||||
if not mark_head:
|
if not mark_head:
|
||||||
bot_message.is_head = True
|
|
||||||
mark_head = True
|
mark_head = True
|
||||||
|
logger.debug(f"添加消息到message_set: {bot_message}")
|
||||||
message_set.add_message(bot_message)
|
message_set.add_message(bot_message)
|
||||||
|
|
||||||
#message_set 可以直接加入 message_manager
|
# message_set 可以直接加入 message_manager
|
||||||
# print(f"\033[1;32m[回复]\033[0m 将回复载入发送容器")
|
# print(f"\033[1;32m[回复]\033[0m 将回复载入发送容器")
|
||||||
|
|
||||||
|
logger.debug("添加message_set到message_manager")
|
||||||
|
|
||||||
message_manager.add_message(message_set)
|
message_manager.add_message(message_set)
|
||||||
|
|
||||||
bot_response_time = tinking_time_point
|
bot_response_time = thinking_time_point
|
||||||
|
|
||||||
if random() < global_config.emoji_chance:
|
if random() < global_config.emoji_chance:
|
||||||
emoji_raw = await emoji_manager.get_emoji_for_text(response)
|
emoji_raw = await emoji_manager.get_emoji_for_text(response)
|
||||||
|
|
||||||
# 检查是否 <没有找到> emoji
|
# 检查是否 <没有找到> emoji
|
||||||
if emoji_raw != None:
|
if emoji_raw != None:
|
||||||
emoji_path,discription = emoji_raw
|
emoji_path, description = emoji_raw
|
||||||
|
|
||||||
emoji_cq = CQCode.create_emoji_cq(emoji_path)
|
emoji_cq = image_path_to_base64(emoji_path)
|
||||||
|
|
||||||
if random() < 0.5:
|
if random() < 0.5:
|
||||||
bot_response_time = tinking_time_point - 1
|
bot_response_time = thinking_time_point - 1
|
||||||
else:
|
else:
|
||||||
bot_response_time = bot_response_time + 1
|
bot_response_time = bot_response_time + 1
|
||||||
|
|
||||||
bot_message = Message_Sending(
|
message_segment = Seg(type="emoji", data=emoji_cq)
|
||||||
group_id=event.group_id,
|
bot_message = MessageSending(
|
||||||
user_id=global_config.BOT_QQ,
|
message_id=think_id,
|
||||||
message_id=0,
|
chat_stream=chat,
|
||||||
raw_message=emoji_cq,
|
bot_user_info=bot_user_info,
|
||||||
plain_text=emoji_cq,
|
sender_info=userinfo,
|
||||||
processed_plain_text=emoji_cq,
|
message_segment=message_segment,
|
||||||
detailed_plain_text=discription,
|
reply=message,
|
||||||
user_nickname=global_config.BOT_NICKNAME,
|
is_head=False,
|
||||||
group_name=message.group_name,
|
|
||||||
time=bot_response_time,
|
|
||||||
is_emoji=True,
|
is_emoji=True,
|
||||||
translate_cq=False,
|
|
||||||
thinking_start_time=thinking_start_time,
|
|
||||||
# reply_message_id=message.message_id
|
|
||||||
)
|
)
|
||||||
await bot_message.initialize()
|
|
||||||
message_manager.add_message(bot_message)
|
message_manager.add_message(bot_message)
|
||||||
|
|
||||||
emotion = await self.gpt._get_emotion_tags(raw_content)
|
emotion = await self.gpt._get_emotion_tags(raw_content)
|
||||||
print(f"为 '{response}' 获取到的情感标签为:{emotion}")
|
logger.debug(f"为 '{response}' 获取到的情感标签为:{emotion}")
|
||||||
valuedict={
|
valuedict = {
|
||||||
'happy': 0.5,
|
"happy": 0.5,
|
||||||
'angry': -1,
|
"angry": -1,
|
||||||
'sad': -0.5,
|
"sad": -0.5,
|
||||||
'surprised': 0.2,
|
"surprised": 0.2,
|
||||||
'disgusted': -1.5,
|
"disgusted": -1.5,
|
||||||
'fearful': -0.7,
|
"fearful": -0.7,
|
||||||
'neutral': 0.1
|
"neutral": 0.1,
|
||||||
}
|
}
|
||||||
await relationship_manager.update_relationship_value(message.user_id, relationship_value=valuedict[emotion[0]])
|
await relationship_manager.update_relationship_value(
|
||||||
|
chat_stream=chat, relationship_value=valuedict[emotion[0]]
|
||||||
|
)
|
||||||
# 使用情绪管理器更新情绪
|
# 使用情绪管理器更新情绪
|
||||||
self.mood_manager.update_mood_from_emotion(emotion[0], global_config.mood_intensity_factor)
|
self.mood_manager.update_mood_from_emotion(emotion[0], global_config.mood_intensity_factor)
|
||||||
|
|
||||||
# willing_manager.change_reply_willing_after_sent(event.group_id)
|
# willing_manager.change_reply_willing_after_sent(
|
||||||
|
# chat_stream=chat
|
||||||
|
# )
|
||||||
|
|
||||||
|
|
||||||
# 创建全局ChatBot实例
|
# 创建全局ChatBot实例
|
||||||
chat_bot = ChatBot()
|
chat_bot = ChatBot()
|
||||||
225
src/plugins/chat/chat_stream.py
Normal file
@@ -0,0 +1,225 @@
|
|||||||
|
import asyncio
|
||||||
|
import hashlib
|
||||||
|
import time
|
||||||
|
import copy
|
||||||
|
from typing import Dict, Optional
|
||||||
|
|
||||||
|
from loguru import logger
|
||||||
|
|
||||||
|
from ...common.database import db
|
||||||
|
from .message_base import GroupInfo, UserInfo
|
||||||
|
|
||||||
|
|
||||||
|
class ChatStream:
|
||||||
|
"""聊天流对象,存储一个完整的聊天上下文"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
stream_id: str,
|
||||||
|
platform: str,
|
||||||
|
user_info: UserInfo,
|
||||||
|
group_info: Optional[GroupInfo] = None,
|
||||||
|
data: dict = None,
|
||||||
|
):
|
||||||
|
self.stream_id = stream_id
|
||||||
|
self.platform = platform
|
||||||
|
self.user_info = user_info
|
||||||
|
self.group_info = group_info
|
||||||
|
self.create_time = (
|
||||||
|
data.get("create_time", int(time.time())) if data else int(time.time())
|
||||||
|
)
|
||||||
|
self.last_active_time = (
|
||||||
|
data.get("last_active_time", self.create_time) if data else self.create_time
|
||||||
|
)
|
||||||
|
self.saved = False
|
||||||
|
|
||||||
|
def to_dict(self) -> dict:
|
||||||
|
"""转换为字典格式"""
|
||||||
|
result = {
|
||||||
|
"stream_id": self.stream_id,
|
||||||
|
"platform": self.platform,
|
||||||
|
"user_info": self.user_info.to_dict() if self.user_info else None,
|
||||||
|
"group_info": self.group_info.to_dict() if self.group_info else None,
|
||||||
|
"create_time": self.create_time,
|
||||||
|
"last_active_time": self.last_active_time,
|
||||||
|
}
|
||||||
|
return result
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def from_dict(cls, data: dict) -> "ChatStream":
|
||||||
|
"""从字典创建实例"""
|
||||||
|
user_info = (
|
||||||
|
UserInfo(**data.get("user_info", {})) if data.get("user_info") else None
|
||||||
|
)
|
||||||
|
group_info = (
|
||||||
|
GroupInfo(**data.get("group_info", {})) if data.get("group_info") else None
|
||||||
|
)
|
||||||
|
|
||||||
|
return cls(
|
||||||
|
stream_id=data["stream_id"],
|
||||||
|
platform=data["platform"],
|
||||||
|
user_info=user_info,
|
||||||
|
group_info=group_info,
|
||||||
|
data=data,
|
||||||
|
)
|
||||||
|
|
||||||
|
def update_active_time(self):
|
||||||
|
"""更新最后活跃时间"""
|
||||||
|
self.last_active_time = int(time.time())
|
||||||
|
self.saved = False
|
||||||
|
|
||||||
|
|
||||||
|
class ChatManager:
|
||||||
|
"""聊天管理器,管理所有聊天流"""
|
||||||
|
|
||||||
|
_instance = None
|
||||||
|
_initialized = False
|
||||||
|
|
||||||
|
def __new__(cls):
|
||||||
|
if cls._instance is None:
|
||||||
|
cls._instance = super().__new__(cls)
|
||||||
|
return cls._instance
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
if not self._initialized:
|
||||||
|
self.streams: Dict[str, ChatStream] = {} # stream_id -> ChatStream
|
||||||
|
self._ensure_collection()
|
||||||
|
self._initialized = True
|
||||||
|
# 在事件循环中启动初始化
|
||||||
|
# asyncio.create_task(self._initialize())
|
||||||
|
# # 启动自动保存任务
|
||||||
|
# asyncio.create_task(self._auto_save_task())
|
||||||
|
|
||||||
|
async def _initialize(self):
|
||||||
|
"""异步初始化"""
|
||||||
|
try:
|
||||||
|
await self.load_all_streams()
|
||||||
|
logger.success(f"聊天管理器已启动,已加载 {len(self.streams)} 个聊天流")
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"聊天管理器启动失败: {str(e)}")
|
||||||
|
|
||||||
|
async def _auto_save_task(self):
|
||||||
|
"""定期自动保存所有聊天流"""
|
||||||
|
while True:
|
||||||
|
await asyncio.sleep(300) # 每5分钟保存一次
|
||||||
|
try:
|
||||||
|
await self._save_all_streams()
|
||||||
|
logger.info("聊天流自动保存完成")
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"聊天流自动保存失败: {str(e)}")
|
||||||
|
|
||||||
|
def _ensure_collection(self):
|
||||||
|
"""确保数据库集合存在并创建索引"""
|
||||||
|
if "chat_streams" not in db.list_collection_names():
|
||||||
|
db.create_collection("chat_streams")
|
||||||
|
# 创建索引
|
||||||
|
db.chat_streams.create_index([("stream_id", 1)], unique=True)
|
||||||
|
db.chat_streams.create_index(
|
||||||
|
[("platform", 1), ("user_info.user_id", 1), ("group_info.group_id", 1)]
|
||||||
|
)
|
||||||
|
|
||||||
|
def _generate_stream_id(
|
||||||
|
self, platform: str, user_info: UserInfo, group_info: Optional[GroupInfo] = None
|
||||||
|
) -> str:
|
||||||
|
"""生成聊天流唯一ID"""
|
||||||
|
if group_info:
|
||||||
|
# 组合关键信息
|
||||||
|
components = [
|
||||||
|
platform,
|
||||||
|
str(group_info.group_id)
|
||||||
|
]
|
||||||
|
else:
|
||||||
|
components = [
|
||||||
|
platform,
|
||||||
|
str(user_info.user_id),
|
||||||
|
"private"
|
||||||
|
]
|
||||||
|
|
||||||
|
# 使用MD5生成唯一ID
|
||||||
|
key = "_".join(components)
|
||||||
|
return hashlib.md5(key.encode()).hexdigest()
|
||||||
|
|
||||||
|
async def get_or_create_stream(
|
||||||
|
self, platform: str, user_info: UserInfo, group_info: Optional[GroupInfo] = None
|
||||||
|
) -> ChatStream:
|
||||||
|
"""获取或创建聊天流
|
||||||
|
|
||||||
|
Args:
|
||||||
|
platform: 平台标识
|
||||||
|
user_info: 用户信息
|
||||||
|
group_info: 群组信息(可选)
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
ChatStream: 聊天流对象
|
||||||
|
"""
|
||||||
|
# 生成stream_id
|
||||||
|
stream_id = self._generate_stream_id(platform, user_info, group_info)
|
||||||
|
|
||||||
|
# 检查内存中是否存在
|
||||||
|
if stream_id in self.streams:
|
||||||
|
stream = self.streams[stream_id]
|
||||||
|
# 更新用户信息和群组信息
|
||||||
|
stream.update_active_time()
|
||||||
|
stream=copy.deepcopy(stream)
|
||||||
|
stream.user_info = user_info
|
||||||
|
if group_info:
|
||||||
|
stream.group_info = group_info
|
||||||
|
return stream
|
||||||
|
|
||||||
|
# 检查数据库中是否存在
|
||||||
|
data = db.chat_streams.find_one({"stream_id": stream_id})
|
||||||
|
if data:
|
||||||
|
stream = ChatStream.from_dict(data)
|
||||||
|
# 更新用户信息和群组信息
|
||||||
|
stream.user_info = user_info
|
||||||
|
if group_info:
|
||||||
|
stream.group_info = group_info
|
||||||
|
stream.update_active_time()
|
||||||
|
else:
|
||||||
|
# 创建新的聊天流
|
||||||
|
stream = ChatStream(
|
||||||
|
stream_id=stream_id,
|
||||||
|
platform=platform,
|
||||||
|
user_info=user_info,
|
||||||
|
group_info=group_info,
|
||||||
|
)
|
||||||
|
|
||||||
|
# 保存到内存和数据库
|
||||||
|
self.streams[stream_id] = stream
|
||||||
|
await self._save_stream(stream)
|
||||||
|
return copy.deepcopy(stream)
|
||||||
|
|
||||||
|
def get_stream(self, stream_id: str) -> Optional[ChatStream]:
|
||||||
|
"""通过stream_id获取聊天流"""
|
||||||
|
return self.streams.get(stream_id)
|
||||||
|
|
||||||
|
def get_stream_by_info(
|
||||||
|
self, platform: str, user_info: UserInfo, group_info: Optional[GroupInfo] = None
|
||||||
|
) -> Optional[ChatStream]:
|
||||||
|
"""通过信息获取聊天流"""
|
||||||
|
stream_id = self._generate_stream_id(platform, user_info, group_info)
|
||||||
|
return self.streams.get(stream_id)
|
||||||
|
|
||||||
|
async def _save_stream(self, stream: ChatStream):
|
||||||
|
"""保存聊天流到数据库"""
|
||||||
|
if not stream.saved:
|
||||||
|
db.chat_streams.update_one(
|
||||||
|
{"stream_id": stream.stream_id}, {"$set": stream.to_dict()}, upsert=True
|
||||||
|
)
|
||||||
|
stream.saved = True
|
||||||
|
|
||||||
|
async def _save_all_streams(self):
|
||||||
|
"""保存所有聊天流"""
|
||||||
|
for stream in self.streams.values():
|
||||||
|
await self._save_stream(stream)
|
||||||
|
|
||||||
|
async def load_all_streams(self):
|
||||||
|
"""从数据库加载所有聊天流"""
|
||||||
|
all_streams = db.chat_streams.find({})
|
||||||
|
for data in all_streams:
|
||||||
|
stream = ChatStream.from_dict(data)
|
||||||
|
self.streams[stream.stream_id] = stream
|
||||||
|
|
||||||
|
|
||||||
|
# 创建全局单例
|
||||||
|
chat_manager = ChatManager()
|
||||||
@@ -1,6 +1,7 @@
|
|||||||
import os
|
import os
|
||||||
|
import sys
|
||||||
from dataclasses import dataclass, field
|
from dataclasses import dataclass, field
|
||||||
from typing import Dict, Optional
|
from typing import Dict, List, Optional
|
||||||
|
|
||||||
import tomli
|
import tomli
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
@@ -12,10 +13,12 @@ from packaging.specifiers import SpecifierSet, InvalidSpecifier
|
|||||||
@dataclass
|
@dataclass
|
||||||
class BotConfig:
|
class BotConfig:
|
||||||
"""机器人配置类"""
|
"""机器人配置类"""
|
||||||
|
|
||||||
INNER_VERSION: Version = None
|
INNER_VERSION: Version = None
|
||||||
|
|
||||||
BOT_QQ: Optional[int] = 1
|
BOT_QQ: Optional[int] = 1
|
||||||
BOT_NICKNAME: Optional[str] = None
|
BOT_NICKNAME: Optional[str] = None
|
||||||
|
BOT_ALIAS_NAMES: List[str] = field(default_factory=list) # 别名,可以通过这个叫它
|
||||||
|
|
||||||
# 消息处理相关配置
|
# 消息处理相关配置
|
||||||
MIN_TEXT_LENGTH: int = 2 # 最小处理文本长度
|
MIN_TEXT_LENGTH: int = 2 # 最小处理文本长度
|
||||||
@@ -34,8 +37,7 @@ class BotConfig:
|
|||||||
|
|
||||||
ban_user_id = set()
|
ban_user_id = set()
|
||||||
|
|
||||||
build_memory_interval: int = 30 # 记忆构建间隔(秒)
|
|
||||||
forget_memory_interval: int = 300 # 记忆遗忘间隔(秒)
|
|
||||||
EMOJI_CHECK_INTERVAL: int = 120 # 表情包检查间隔(分钟)
|
EMOJI_CHECK_INTERVAL: int = 120 # 表情包检查间隔(分钟)
|
||||||
EMOJI_REGISTER_INTERVAL: int = 10 # 表情包注册间隔(分钟)
|
EMOJI_REGISTER_INTERVAL: int = 10 # 表情包注册间隔(分钟)
|
||||||
EMOJI_SAVE: bool = True # 偷表情包
|
EMOJI_SAVE: bool = True # 偷表情包
|
||||||
@@ -43,6 +45,7 @@ class BotConfig:
|
|||||||
EMOJI_CHECK_PROMPT: str = "符合公序良俗" # 表情包过滤要求
|
EMOJI_CHECK_PROMPT: str = "符合公序良俗" # 表情包过滤要求
|
||||||
|
|
||||||
ban_words = set()
|
ban_words = set()
|
||||||
|
ban_msgs_regex = set()
|
||||||
|
|
||||||
max_response_length: int = 1024 # 最大回复长度
|
max_response_length: int = 1024 # 最大回复长度
|
||||||
|
|
||||||
@@ -64,6 +67,8 @@ class BotConfig:
|
|||||||
|
|
||||||
enable_advance_output: bool = False # 是否启用高级输出
|
enable_advance_output: bool = False # 是否启用高级输出
|
||||||
enable_kuuki_read: bool = True # 是否启用读空气功能
|
enable_kuuki_read: bool = True # 是否启用读空气功能
|
||||||
|
enable_debug_output: bool = False # 是否启用调试输出
|
||||||
|
enable_friend_chat: bool = False # 是否启用好友聊天
|
||||||
|
|
||||||
mood_update_interval: float = 1.0 # 情绪更新间隔 单位秒
|
mood_update_interval: float = 1.0 # 情绪更新间隔 单位秒
|
||||||
mood_decay_rate: float = 0.95 # 情绪衰减率
|
mood_decay_rate: float = 0.95 # 情绪衰减率
|
||||||
@@ -81,23 +86,31 @@ class BotConfig:
|
|||||||
PROMPT_PERSONALITY = [
|
PROMPT_PERSONALITY = [
|
||||||
"曾经是一个学习地质的女大学生,现在学习心理学和脑科学,你会刷贴吧",
|
"曾经是一个学习地质的女大学生,现在学习心理学和脑科学,你会刷贴吧",
|
||||||
"是一个女大学生,你有黑色头发,你会刷小红书",
|
"是一个女大学生,你有黑色头发,你会刷小红书",
|
||||||
"是一个女大学生,你会刷b站,对ACG文化感兴趣"
|
"是一个女大学生,你会刷b站,对ACG文化感兴趣",
|
||||||
]
|
]
|
||||||
|
|
||||||
PROMPT_SCHEDULE_GEN="一个曾经学习地质,现在学习心理学和脑科学的女大学生,喜欢刷qq,贴吧,知乎和小红书"
|
PROMPT_SCHEDULE_GEN = "一个曾经学习地质,现在学习心理学和脑科学的女大学生,喜欢刷qq,贴吧,知乎和小红书"
|
||||||
|
|
||||||
PERSONALITY_1: float = 0.6 # 第一种人格概率
|
PERSONALITY_1: float = 0.6 # 第一种人格概率
|
||||||
PERSONALITY_2: float = 0.3 # 第二种人格概率
|
PERSONALITY_2: float = 0.3 # 第二种人格概率
|
||||||
PERSONALITY_3: float = 0.1 # 第三种人格概率
|
PERSONALITY_3: float = 0.1 # 第三种人格概率
|
||||||
|
|
||||||
memory_ban_words: list = field(default_factory=lambda: ['表情包', '图片', '回复', '聊天记录']) # 添加新的配置项默认值
|
build_memory_interval: int = 600 # 记忆构建间隔(秒)
|
||||||
|
|
||||||
|
forget_memory_interval: int = 600 # 记忆遗忘间隔(秒)
|
||||||
|
memory_forget_time: int = 24 # 记忆遗忘时间(小时)
|
||||||
|
memory_forget_percentage: float = 0.01 # 记忆遗忘比例
|
||||||
|
memory_compress_rate: float = 0.1 # 记忆压缩率
|
||||||
|
memory_ban_words: list = field(
|
||||||
|
default_factory=lambda: ["表情包", "图片", "回复", "聊天记录"]
|
||||||
|
) # 添加新的配置项默认值
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def get_config_dir() -> str:
|
def get_config_dir() -> str:
|
||||||
"""获取配置文件目录"""
|
"""获取配置文件目录"""
|
||||||
current_dir = os.path.dirname(os.path.abspath(__file__))
|
current_dir = os.path.dirname(os.path.abspath(__file__))
|
||||||
root_dir = os.path.abspath(os.path.join(current_dir, '..', '..', '..'))
|
root_dir = os.path.abspath(os.path.join(current_dir, "..", "..", ".."))
|
||||||
config_dir = os.path.join(root_dir, 'config')
|
config_dir = os.path.join(root_dir, "config")
|
||||||
if not os.path.exists(config_dir):
|
if not os.path.exists(config_dir):
|
||||||
os.makedirs(config_dir)
|
os.makedirs(config_dir)
|
||||||
return config_dir
|
return config_dir
|
||||||
@@ -113,11 +126,8 @@ class BotConfig:
|
|||||||
|
|
||||||
try:
|
try:
|
||||||
converted = SpecifierSet(value)
|
converted = SpecifierSet(value)
|
||||||
except InvalidSpecifier as e:
|
except InvalidSpecifier:
|
||||||
logger.error(
|
logger.error(f"{value} 分类使用了错误的版本约束表达式\n", "请阅读 https://semver.org/lang/zh-CN/ 修改代码")
|
||||||
f"{value} 分类使用了错误的版本约束表达式\n",
|
|
||||||
"请阅读 https://semver.org/lang/zh-CN/ 修改代码"
|
|
||||||
)
|
|
||||||
exit(1)
|
exit(1)
|
||||||
|
|
||||||
return converted
|
return converted
|
||||||
@@ -131,12 +141,12 @@ class BotConfig:
|
|||||||
Version
|
Version
|
||||||
"""
|
"""
|
||||||
|
|
||||||
if 'inner' in toml:
|
if "inner" in toml:
|
||||||
try:
|
try:
|
||||||
config_version: str = toml["inner"]["version"]
|
config_version: str = toml["inner"]["version"]
|
||||||
except KeyError as e:
|
except KeyError as e:
|
||||||
logger.error(f"配置文件中 inner 段 不存在 {e}, 这是错误的配置文件")
|
logger.error("配置文件中 inner 段 不存在, 这是错误的配置文件")
|
||||||
raise KeyError(f"配置文件中 inner 段 不存在 {e}, 这是错误的配置文件")
|
raise KeyError(f"配置文件中 inner 段 不存在 {e}, 这是错误的配置文件") from e
|
||||||
else:
|
else:
|
||||||
toml["inner"] = {"version": "0.0.0"}
|
toml["inner"] = {"version": "0.0.0"}
|
||||||
config_version = toml["inner"]["version"]
|
config_version = toml["inner"]["version"]
|
||||||
@@ -149,7 +159,7 @@ class BotConfig:
|
|||||||
"请阅读 https://semver.org/lang/zh-CN/ 修改配置,并参考本项目指定的模板进行修改\n"
|
"请阅读 https://semver.org/lang/zh-CN/ 修改配置,并参考本项目指定的模板进行修改\n"
|
||||||
"本项目在不同的版本下有不同的模板,请注意识别"
|
"本项目在不同的版本下有不同的模板,请注意识别"
|
||||||
)
|
)
|
||||||
raise InvalidVersion("配置文件中 inner段 的 version 键是错误的版本描述\n")
|
raise InvalidVersion("配置文件中 inner段 的 version 键是错误的版本描述\n") from e
|
||||||
|
|
||||||
return ver
|
return ver
|
||||||
|
|
||||||
@@ -159,26 +169,26 @@ class BotConfig:
|
|||||||
config = cls()
|
config = cls()
|
||||||
|
|
||||||
def personality(parent: dict):
|
def personality(parent: dict):
|
||||||
personality_config = parent['personality']
|
personality_config = parent["personality"]
|
||||||
personality = personality_config.get('prompt_personality')
|
personality = personality_config.get("prompt_personality")
|
||||||
if len(personality) >= 2:
|
if len(personality) >= 2:
|
||||||
logger.info(f"载入自定义人格:{personality}")
|
logger.debug(f"载入自定义人格:{personality}")
|
||||||
config.PROMPT_PERSONALITY = personality_config.get('prompt_personality', config.PROMPT_PERSONALITY)
|
config.PROMPT_PERSONALITY = personality_config.get("prompt_personality", config.PROMPT_PERSONALITY)
|
||||||
logger.info(f"载入自定义日程prompt:{personality_config.get('prompt_schedule', config.PROMPT_SCHEDULE_GEN)}")
|
logger.info(f"载入自定义日程prompt:{personality_config.get('prompt_schedule', config.PROMPT_SCHEDULE_GEN)}")
|
||||||
config.PROMPT_SCHEDULE_GEN = personality_config.get('prompt_schedule', config.PROMPT_SCHEDULE_GEN)
|
config.PROMPT_SCHEDULE_GEN = personality_config.get("prompt_schedule", config.PROMPT_SCHEDULE_GEN)
|
||||||
|
|
||||||
if config.INNER_VERSION in SpecifierSet(">=0.0.2"):
|
if config.INNER_VERSION in SpecifierSet(">=0.0.2"):
|
||||||
config.PERSONALITY_1 = personality_config.get('personality_1_probability', config.PERSONALITY_1)
|
config.PERSONALITY_1 = personality_config.get("personality_1_probability", config.PERSONALITY_1)
|
||||||
config.PERSONALITY_2 = personality_config.get('personality_2_probability', config.PERSONALITY_2)
|
config.PERSONALITY_2 = personality_config.get("personality_2_probability", config.PERSONALITY_2)
|
||||||
config.PERSONALITY_3 = personality_config.get('personality_3_probability', config.PERSONALITY_3)
|
config.PERSONALITY_3 = personality_config.get("personality_3_probability", config.PERSONALITY_3)
|
||||||
|
|
||||||
def emoji(parent: dict):
|
def emoji(parent: dict):
|
||||||
emoji_config = parent["emoji"]
|
emoji_config = parent["emoji"]
|
||||||
config.EMOJI_CHECK_INTERVAL = emoji_config.get("check_interval", config.EMOJI_CHECK_INTERVAL)
|
config.EMOJI_CHECK_INTERVAL = emoji_config.get("check_interval", config.EMOJI_CHECK_INTERVAL)
|
||||||
config.EMOJI_REGISTER_INTERVAL = emoji_config.get("register_interval", config.EMOJI_REGISTER_INTERVAL)
|
config.EMOJI_REGISTER_INTERVAL = emoji_config.get("register_interval", config.EMOJI_REGISTER_INTERVAL)
|
||||||
config.EMOJI_CHECK_PROMPT = emoji_config.get('check_prompt', config.EMOJI_CHECK_PROMPT)
|
config.EMOJI_CHECK_PROMPT = emoji_config.get("check_prompt", config.EMOJI_CHECK_PROMPT)
|
||||||
config.EMOJI_SAVE = emoji_config.get('auto_save', config.EMOJI_SAVE)
|
config.EMOJI_SAVE = emoji_config.get("auto_save", config.EMOJI_SAVE)
|
||||||
config.EMOJI_CHECK = emoji_config.get('enable_check', config.EMOJI_CHECK)
|
config.EMOJI_CHECK = emoji_config.get("enable_check", config.EMOJI_CHECK)
|
||||||
|
|
||||||
def cq_code(parent: dict):
|
def cq_code(parent: dict):
|
||||||
cq_code_config = parent["cq_code"]
|
cq_code_config = parent["cq_code"]
|
||||||
@@ -191,12 +201,16 @@ class BotConfig:
|
|||||||
config.BOT_QQ = int(bot_qq)
|
config.BOT_QQ = int(bot_qq)
|
||||||
config.BOT_NICKNAME = bot_config.get("nickname", config.BOT_NICKNAME)
|
config.BOT_NICKNAME = bot_config.get("nickname", config.BOT_NICKNAME)
|
||||||
|
|
||||||
|
if config.INNER_VERSION in SpecifierSet(">=0.0.5"):
|
||||||
|
config.BOT_ALIAS_NAMES = bot_config.get("alias_names", config.BOT_ALIAS_NAMES)
|
||||||
|
|
||||||
def response(parent: dict):
|
def response(parent: dict):
|
||||||
response_config = parent["response"]
|
response_config = parent["response"]
|
||||||
config.MODEL_R1_PROBABILITY = response_config.get("model_r1_probability", config.MODEL_R1_PROBABILITY)
|
config.MODEL_R1_PROBABILITY = response_config.get("model_r1_probability", config.MODEL_R1_PROBABILITY)
|
||||||
config.MODEL_V3_PROBABILITY = response_config.get("model_v3_probability", config.MODEL_V3_PROBABILITY)
|
config.MODEL_V3_PROBABILITY = response_config.get("model_v3_probability", config.MODEL_V3_PROBABILITY)
|
||||||
config.MODEL_R1_DISTILL_PROBABILITY = response_config.get("model_r1_distill_probability",
|
config.MODEL_R1_DISTILL_PROBABILITY = response_config.get(
|
||||||
config.MODEL_R1_DISTILL_PROBABILITY)
|
"model_r1_distill_probability", config.MODEL_R1_DISTILL_PROBABILITY
|
||||||
|
)
|
||||||
config.max_response_length = response_config.get("max_response_length", config.max_response_length)
|
config.max_response_length = response_config.get("max_response_length", config.max_response_length)
|
||||||
|
|
||||||
def model(parent: dict):
|
def model(parent: dict):
|
||||||
@@ -213,7 +227,7 @@ class BotConfig:
|
|||||||
"llm_emotion_judge",
|
"llm_emotion_judge",
|
||||||
"vlm",
|
"vlm",
|
||||||
"embedding",
|
"embedding",
|
||||||
"moderation"
|
"moderation",
|
||||||
]
|
]
|
||||||
|
|
||||||
for item in config_list:
|
for item in config_list:
|
||||||
@@ -222,13 +236,7 @@ class BotConfig:
|
|||||||
|
|
||||||
# base_url 的例子: SILICONFLOW_BASE_URL
|
# base_url 的例子: SILICONFLOW_BASE_URL
|
||||||
# key 的例子: SILICONFLOW_KEY
|
# key 的例子: SILICONFLOW_KEY
|
||||||
cfg_target = {
|
cfg_target = {"name": "", "base_url": "", "key": "", "pri_in": 0, "pri_out": 0}
|
||||||
"name": "",
|
|
||||||
"base_url": "",
|
|
||||||
"key": "",
|
|
||||||
"pri_in": 0,
|
|
||||||
"pri_out": 0
|
|
||||||
}
|
|
||||||
|
|
||||||
if config.INNER_VERSION in SpecifierSet("<=0.0.0"):
|
if config.INNER_VERSION in SpecifierSet("<=0.0.0"):
|
||||||
cfg_target = cfg_item
|
cfg_target = cfg_item
|
||||||
@@ -246,11 +254,11 @@ class BotConfig:
|
|||||||
try:
|
try:
|
||||||
cfg_target[i] = cfg_item[i]
|
cfg_target[i] = cfg_item[i]
|
||||||
except KeyError as e:
|
except KeyError as e:
|
||||||
logger.error(f"{item} 中的必要字段 {e} 不存在,请检查")
|
logger.error(f"{item} 中的必要字段不存在,请检查")
|
||||||
raise KeyError(f"{item} 中的必要字段 {e} 不存在,请检查")
|
raise KeyError(f"{item} 中的必要字段 {e} 不存在,请检查") from e
|
||||||
|
|
||||||
provider = cfg_item.get("provider")
|
provider = cfg_item.get("provider")
|
||||||
if provider == None:
|
if provider is None:
|
||||||
logger.error(f"provider 字段在模型配置 {item} 中不存在,请检查")
|
logger.error(f"provider 字段在模型配置 {item} 中不存在,请检查")
|
||||||
raise KeyError(f"provider 字段在模型配置 {item} 中不存在,请检查")
|
raise KeyError(f"provider 字段在模型配置 {item} 中不存在,请检查")
|
||||||
|
|
||||||
@@ -272,12 +280,17 @@ class BotConfig:
|
|||||||
|
|
||||||
if config.INNER_VERSION in SpecifierSet(">=0.0.2"):
|
if config.INNER_VERSION in SpecifierSet(">=0.0.2"):
|
||||||
config.thinking_timeout = msg_config.get("thinking_timeout", config.thinking_timeout)
|
config.thinking_timeout = msg_config.get("thinking_timeout", config.thinking_timeout)
|
||||||
config.response_willing_amplifier = msg_config.get("response_willing_amplifier",
|
config.response_willing_amplifier = msg_config.get(
|
||||||
config.response_willing_amplifier)
|
"response_willing_amplifier", config.response_willing_amplifier
|
||||||
config.response_interested_rate_amplifier = msg_config.get("response_interested_rate_amplifier",
|
)
|
||||||
config.response_interested_rate_amplifier)
|
config.response_interested_rate_amplifier = msg_config.get(
|
||||||
|
"response_interested_rate_amplifier", config.response_interested_rate_amplifier
|
||||||
|
)
|
||||||
config.down_frequency_rate = msg_config.get("down_frequency_rate", config.down_frequency_rate)
|
config.down_frequency_rate = msg_config.get("down_frequency_rate", config.down_frequency_rate)
|
||||||
|
|
||||||
|
if config.INNER_VERSION in SpecifierSet(">=0.0.6"):
|
||||||
|
config.ban_msgs_regex = msg_config.get("ban_msgs_regex", config.ban_msgs_regex)
|
||||||
|
|
||||||
def memory(parent: dict):
|
def memory(parent: dict):
|
||||||
memory_config = parent["memory"]
|
memory_config = parent["memory"]
|
||||||
config.build_memory_interval = memory_config.get("build_memory_interval", config.build_memory_interval)
|
config.build_memory_interval = memory_config.get("build_memory_interval", config.build_memory_interval)
|
||||||
@@ -287,6 +300,11 @@ class BotConfig:
|
|||||||
if config.INNER_VERSION in SpecifierSet(">=0.0.4"):
|
if config.INNER_VERSION in SpecifierSet(">=0.0.4"):
|
||||||
config.memory_ban_words = set(memory_config.get("memory_ban_words", []))
|
config.memory_ban_words = set(memory_config.get("memory_ban_words", []))
|
||||||
|
|
||||||
|
if config.INNER_VERSION in SpecifierSet(">=0.0.7"):
|
||||||
|
config.memory_forget_time = memory_config.get("memory_forget_time", config.memory_forget_time)
|
||||||
|
config.memory_forget_percentage = memory_config.get("memory_forget_percentage", config.memory_forget_percentage)
|
||||||
|
config.memory_compress_rate = memory_config.get("memory_compress_rate", config.memory_compress_rate)
|
||||||
|
|
||||||
def mood(parent: dict):
|
def mood(parent: dict):
|
||||||
mood_config = parent["mood"]
|
mood_config = parent["mood"]
|
||||||
config.mood_update_interval = mood_config.get("mood_update_interval", config.mood_update_interval)
|
config.mood_update_interval = mood_config.get("mood_update_interval", config.mood_update_interval)
|
||||||
@@ -303,10 +321,12 @@ class BotConfig:
|
|||||||
config.chinese_typo_enable = chinese_typo_config.get("enable", config.chinese_typo_enable)
|
config.chinese_typo_enable = chinese_typo_config.get("enable", config.chinese_typo_enable)
|
||||||
config.chinese_typo_error_rate = chinese_typo_config.get("error_rate", config.chinese_typo_error_rate)
|
config.chinese_typo_error_rate = chinese_typo_config.get("error_rate", config.chinese_typo_error_rate)
|
||||||
config.chinese_typo_min_freq = chinese_typo_config.get("min_freq", config.chinese_typo_min_freq)
|
config.chinese_typo_min_freq = chinese_typo_config.get("min_freq", config.chinese_typo_min_freq)
|
||||||
config.chinese_typo_tone_error_rate = chinese_typo_config.get("tone_error_rate",
|
config.chinese_typo_tone_error_rate = chinese_typo_config.get(
|
||||||
config.chinese_typo_tone_error_rate)
|
"tone_error_rate", config.chinese_typo_tone_error_rate
|
||||||
config.chinese_typo_word_replace_rate = chinese_typo_config.get("word_replace_rate",
|
)
|
||||||
config.chinese_typo_word_replace_rate)
|
config.chinese_typo_word_replace_rate = chinese_typo_config.get(
|
||||||
|
"word_replace_rate", config.chinese_typo_word_replace_rate
|
||||||
|
)
|
||||||
|
|
||||||
def groups(parent: dict):
|
def groups(parent: dict):
|
||||||
groups_config = parent["groups"]
|
groups_config = parent["groups"]
|
||||||
@@ -318,6 +338,9 @@ class BotConfig:
|
|||||||
others_config = parent["others"]
|
others_config = parent["others"]
|
||||||
config.enable_advance_output = others_config.get("enable_advance_output", config.enable_advance_output)
|
config.enable_advance_output = others_config.get("enable_advance_output", config.enable_advance_output)
|
||||||
config.enable_kuuki_read = others_config.get("enable_kuuki_read", config.enable_kuuki_read)
|
config.enable_kuuki_read = others_config.get("enable_kuuki_read", config.enable_kuuki_read)
|
||||||
|
if config.INNER_VERSION in SpecifierSet(">=0.0.7"):
|
||||||
|
config.enable_debug_output = others_config.get("enable_debug_output", config.enable_debug_output)
|
||||||
|
config.enable_friend_chat = others_config.get("enable_friend_chat", config.enable_friend_chat)
|
||||||
|
|
||||||
# 版本表达式:>=1.0.0,<2.0.0
|
# 版本表达式:>=1.0.0,<2.0.0
|
||||||
# 允许字段:func: method, support: str, notice: str, necessary: bool
|
# 允许字段:func: method, support: str, notice: str, necessary: bool
|
||||||
@@ -325,61 +348,19 @@ class BotConfig:
|
|||||||
# 例如:"notice": "personality 将在 1.3.2 后被移除",那么在有效版本中的用户就会虽然可以
|
# 例如:"notice": "personality 将在 1.3.2 后被移除",那么在有效版本中的用户就会虽然可以
|
||||||
# 正常执行程序,但是会看到这条自定义提示
|
# 正常执行程序,但是会看到这条自定义提示
|
||||||
include_configs = {
|
include_configs = {
|
||||||
"personality": {
|
"personality": {"func": personality, "support": ">=0.0.0"},
|
||||||
"func": personality,
|
"emoji": {"func": emoji, "support": ">=0.0.0"},
|
||||||
"support": ">=0.0.0"
|
"cq_code": {"func": cq_code, "support": ">=0.0.0"},
|
||||||
},
|
"bot": {"func": bot, "support": ">=0.0.0"},
|
||||||
"emoji": {
|
"response": {"func": response, "support": ">=0.0.0"},
|
||||||
"func": emoji,
|
"model": {"func": model, "support": ">=0.0.0"},
|
||||||
"support": ">=0.0.0"
|
"message": {"func": message, "support": ">=0.0.0"},
|
||||||
},
|
"memory": {"func": memory, "support": ">=0.0.0", "necessary": False},
|
||||||
"cq_code": {
|
"mood": {"func": mood, "support": ">=0.0.0"},
|
||||||
"func": cq_code,
|
"keywords_reaction": {"func": keywords_reaction, "support": ">=0.0.2", "necessary": False},
|
||||||
"support": ">=0.0.0"
|
"chinese_typo": {"func": chinese_typo, "support": ">=0.0.3", "necessary": False},
|
||||||
},
|
"groups": {"func": groups, "support": ">=0.0.0"},
|
||||||
"bot": {
|
"others": {"func": others, "support": ">=0.0.0"},
|
||||||
"func": bot,
|
|
||||||
"support": ">=0.0.0"
|
|
||||||
},
|
|
||||||
"response": {
|
|
||||||
"func": response,
|
|
||||||
"support": ">=0.0.0"
|
|
||||||
},
|
|
||||||
"model": {
|
|
||||||
"func": model,
|
|
||||||
"support": ">=0.0.0"
|
|
||||||
},
|
|
||||||
"message": {
|
|
||||||
"func": message,
|
|
||||||
"support": ">=0.0.0"
|
|
||||||
},
|
|
||||||
"memory": {
|
|
||||||
"func": memory,
|
|
||||||
"support": ">=0.0.0",
|
|
||||||
"necessary": False
|
|
||||||
},
|
|
||||||
"mood": {
|
|
||||||
"func": mood,
|
|
||||||
"support": ">=0.0.0"
|
|
||||||
},
|
|
||||||
"keywords_reaction": {
|
|
||||||
"func": keywords_reaction,
|
|
||||||
"support": ">=0.0.2",
|
|
||||||
"necessary": False
|
|
||||||
},
|
|
||||||
"chinese_typo": {
|
|
||||||
"func": chinese_typo,
|
|
||||||
"support": ">=0.0.3",
|
|
||||||
"necessary": False
|
|
||||||
},
|
|
||||||
"groups": {
|
|
||||||
"func": groups,
|
|
||||||
"support": ">=0.0.0"
|
|
||||||
},
|
|
||||||
"others": {
|
|
||||||
"func": others,
|
|
||||||
"support": ">=0.0.0"
|
|
||||||
}
|
|
||||||
}
|
}
|
||||||
|
|
||||||
# 原地修改,将 字符串版本表达式 转换成 版本对象
|
# 原地修改,将 字符串版本表达式 转换成 版本对象
|
||||||
@@ -391,7 +372,7 @@ class BotConfig:
|
|||||||
with open(config_path, "rb") as f:
|
with open(config_path, "rb") as f:
|
||||||
try:
|
try:
|
||||||
toml_dict = tomli.load(f)
|
toml_dict = tomli.load(f)
|
||||||
except(tomli.TOMLDecodeError) as e:
|
except tomli.TOMLDecodeError as e:
|
||||||
logger.critical(f"配置文件bot_config.toml填写有误,请检查第{e.lineno}行第{e.colno}处:{e.msg}")
|
logger.critical(f"配置文件bot_config.toml填写有误,请检查第{e.lineno}行第{e.colno}处:{e.msg}")
|
||||||
exit(1)
|
exit(1)
|
||||||
|
|
||||||
@@ -406,7 +387,7 @@ class BotConfig:
|
|||||||
# 检查配置文件版本是否在支持范围内
|
# 检查配置文件版本是否在支持范围内
|
||||||
if config.INNER_VERSION in group_specifierset:
|
if config.INNER_VERSION in group_specifierset:
|
||||||
# 如果版本在支持范围内,检查是否存在通知
|
# 如果版本在支持范围内,检查是否存在通知
|
||||||
if 'notice' in include_configs[key]:
|
if "notice" in include_configs[key]:
|
||||||
logger.warning(include_configs[key]["notice"])
|
logger.warning(include_configs[key]["notice"])
|
||||||
|
|
||||||
include_configs[key]["func"](toml_dict)
|
include_configs[key]["func"](toml_dict)
|
||||||
@@ -420,7 +401,7 @@ class BotConfig:
|
|||||||
raise InvalidVersion(f"当前程序仅支持以下版本范围: {group_specifierset}")
|
raise InvalidVersion(f"当前程序仅支持以下版本范围: {group_specifierset}")
|
||||||
|
|
||||||
# 如果 necessary 项目存在,而且显式声明是 False,进入特殊处理
|
# 如果 necessary 项目存在,而且显式声明是 False,进入特殊处理
|
||||||
elif "necessary" in include_configs[key] and include_configs[key].get("necessary") == False:
|
elif "necessary" in include_configs[key] and include_configs[key].get("necessary") is False:
|
||||||
# 通过 pass 处理的项虽然直接忽略也是可以的,但是为了不增加理解困难,依然需要在这里显式处理
|
# 通过 pass 处理的项虽然直接忽略也是可以的,但是为了不增加理解困难,依然需要在这里显式处理
|
||||||
if key == "keywords_reaction":
|
if key == "keywords_reaction":
|
||||||
pass
|
pass
|
||||||
@@ -454,4 +435,8 @@ global_config = BotConfig.load_config(config_path=bot_config_path)
|
|||||||
|
|
||||||
if not global_config.enable_advance_output:
|
if not global_config.enable_advance_output:
|
||||||
logger.remove()
|
logger.remove()
|
||||||
pass
|
|
||||||
|
# 调试输出功能
|
||||||
|
if global_config.enable_debug_output:
|
||||||
|
logger.remove()
|
||||||
|
logger.add(sys.stdout, level="DEBUG")
|
||||||
|
|||||||
@@ -1,23 +1,26 @@
|
|||||||
import base64
|
import base64
|
||||||
import html
|
import html
|
||||||
import os
|
|
||||||
import time
|
import time
|
||||||
from dataclasses import dataclass
|
from dataclasses import dataclass
|
||||||
from typing import Dict, Optional
|
from typing import Dict, List, Optional, Union
|
||||||
|
|
||||||
|
import os
|
||||||
|
|
||||||
import requests
|
import requests
|
||||||
|
|
||||||
# 解析各种CQ码
|
# 解析各种CQ码
|
||||||
# 包含CQ码类
|
# 包含CQ码类
|
||||||
import urllib3
|
import urllib3
|
||||||
|
from loguru import logger
|
||||||
from nonebot import get_driver
|
from nonebot import get_driver
|
||||||
from urllib3.util import create_urllib3_context
|
from urllib3.util import create_urllib3_context
|
||||||
|
|
||||||
from ..models.utils_model import LLM_request
|
from ..models.utils_model import LLM_request
|
||||||
from .config import global_config
|
from .config import global_config
|
||||||
from .mapper import emojimapper
|
from .mapper import emojimapper
|
||||||
from .utils_image import storage_emoji, storage_image
|
from .message_base import Seg
|
||||||
from .utils_user import get_user_nickname
|
from .utils_user import get_user_nickname,get_groupname
|
||||||
|
from .message_base import GroupInfo, UserInfo
|
||||||
|
|
||||||
driver = get_driver()
|
driver = get_driver()
|
||||||
config = driver.config
|
config = driver.config
|
||||||
@@ -35,8 +38,11 @@ class TencentSSLAdapter(requests.adapters.HTTPAdapter):
|
|||||||
|
|
||||||
def init_poolmanager(self, connections, maxsize, block=False):
|
def init_poolmanager(self, connections, maxsize, block=False):
|
||||||
self.poolmanager = urllib3.poolmanager.PoolManager(
|
self.poolmanager = urllib3.poolmanager.PoolManager(
|
||||||
num_pools=connections, maxsize=maxsize,
|
num_pools=connections,
|
||||||
block=block, ssl_context=self.ssl_context)
|
maxsize=maxsize,
|
||||||
|
block=block,
|
||||||
|
ssl_context=self.ssl_context,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
@dataclass
|
@dataclass
|
||||||
@@ -48,52 +54,67 @@ class CQCode:
|
|||||||
type: CQ码类型(如'image', 'at', 'face'等)
|
type: CQ码类型(如'image', 'at', 'face'等)
|
||||||
params: CQ码的参数字典
|
params: CQ码的参数字典
|
||||||
raw_code: 原始CQ码字符串
|
raw_code: 原始CQ码字符串
|
||||||
translated_plain_text: 经过处理(如AI翻译)后的文本表示
|
translated_segments: 经过处理后的Seg对象列表
|
||||||
"""
|
"""
|
||||||
|
|
||||||
type: str
|
type: str
|
||||||
params: Dict[str, str]
|
params: Dict[str, str]
|
||||||
# raw_code: str
|
group_info: Optional[GroupInfo] = None
|
||||||
group_id: int
|
user_info: Optional[UserInfo] = None
|
||||||
user_id: int
|
translated_segments: Optional[Union[Seg, List[Seg]]] = None
|
||||||
group_name: str = ""
|
|
||||||
user_nickname: str = ""
|
|
||||||
translated_plain_text: Optional[str] = None
|
|
||||||
reply_message: Dict = None # 存储回复消息
|
reply_message: Dict = None # 存储回复消息
|
||||||
image_base64: Optional[str] = None
|
image_base64: Optional[str] = None
|
||||||
_llm: Optional[LLM_request] = None
|
_llm: Optional[LLM_request] = None
|
||||||
|
|
||||||
def __post_init__(self):
|
def __post_init__(self):
|
||||||
"""初始化LLM实例"""
|
"""初始化LLM实例"""
|
||||||
self._llm = LLM_request(model=global_config.vlm, temperature=0.4, max_tokens=300)
|
pass
|
||||||
|
|
||||||
async def translate(self):
|
def translate(self):
|
||||||
"""根据CQ码类型进行相应的翻译处理"""
|
"""根据CQ码类型进行相应的翻译处理,转换为Seg对象"""
|
||||||
if self.type == 'text':
|
if self.type == "text":
|
||||||
self.translated_plain_text = self.params.get('text', '')
|
self.translated_segments = Seg(
|
||||||
elif self.type == 'image':
|
type="text", data=self.params.get("text", "")
|
||||||
if self.params.get('sub_type') == '0':
|
)
|
||||||
self.translated_plain_text = await self.translate_image()
|
elif self.type == "image":
|
||||||
|
base64_data = self.translate_image()
|
||||||
|
if base64_data:
|
||||||
|
if self.params.get("sub_type") == "0":
|
||||||
|
self.translated_segments = Seg(type="image", data=base64_data)
|
||||||
else:
|
else:
|
||||||
self.translated_plain_text = await self.translate_emoji()
|
self.translated_segments = Seg(type="emoji", data=base64_data)
|
||||||
elif self.type == 'at':
|
|
||||||
user_nickname = get_user_nickname(self.params.get('qq', ''))
|
|
||||||
if user_nickname:
|
|
||||||
self.translated_plain_text = f"[@{user_nickname}]"
|
|
||||||
else:
|
else:
|
||||||
self.translated_plain_text = "@某人"
|
self.translated_segments = Seg(type="text", data="[图片]")
|
||||||
elif self.type == 'reply':
|
elif self.type == "at":
|
||||||
self.translated_plain_text = await self.translate_reply()
|
if self.params.get("qq") == "all":
|
||||||
elif self.type == 'face':
|
self.translated_segments = Seg(type="text", data="@[全体成员]")
|
||||||
face_id = self.params.get('id', '')
|
|
||||||
# self.translated_plain_text = f"[表情{face_id}]"
|
|
||||||
self.translated_plain_text = f"[{emojimapper.get(int(face_id), '表情')}]"
|
|
||||||
elif self.type == 'forward':
|
|
||||||
self.translated_plain_text = await self.translate_forward()
|
|
||||||
else:
|
else:
|
||||||
self.translated_plain_text = f"[{self.type}]"
|
user_nickname = get_user_nickname(self.params.get("qq", ""))
|
||||||
|
self.translated_segments = Seg(
|
||||||
|
type="text", data=f"[@{user_nickname or '某人'}]"
|
||||||
|
)
|
||||||
|
elif self.type == "reply":
|
||||||
|
reply_segments = self.translate_reply()
|
||||||
|
if reply_segments:
|
||||||
|
self.translated_segments = Seg(type="seglist", data=reply_segments)
|
||||||
|
else:
|
||||||
|
self.translated_segments = Seg(type="text", data="[回复某人消息]")
|
||||||
|
elif self.type == "face":
|
||||||
|
face_id = self.params.get("id", "")
|
||||||
|
self.translated_segments = Seg(
|
||||||
|
type="text", data=f"[{emojimapper.get(int(face_id), '表情')}]"
|
||||||
|
)
|
||||||
|
elif self.type == "forward":
|
||||||
|
forward_segments = self.translate_forward()
|
||||||
|
if forward_segments:
|
||||||
|
self.translated_segments = Seg(type="seglist", data=forward_segments)
|
||||||
|
else:
|
||||||
|
self.translated_segments = Seg(type="text", data="[转发消息]")
|
||||||
|
else:
|
||||||
|
self.translated_segments = Seg(type="text", data=f"[{self.type}]")
|
||||||
|
|
||||||
def get_img(self):
|
def get_img(self):
|
||||||
'''
|
"""
|
||||||
headers = {
|
headers = {
|
||||||
'User-Agent': 'QQ/8.9.68.11565 CFNetwork/1220.1 Darwin/20.3.0',
|
'User-Agent': 'QQ/8.9.68.11565 CFNetwork/1220.1 Darwin/20.3.0',
|
||||||
'Accept': 'image/*;q=0.8',
|
'Accept': 'image/*;q=0.8',
|
||||||
@@ -102,18 +123,18 @@ class CQCode:
|
|||||||
'Cache-Control': 'no-cache',
|
'Cache-Control': 'no-cache',
|
||||||
'Pragma': 'no-cache'
|
'Pragma': 'no-cache'
|
||||||
}
|
}
|
||||||
'''
|
"""
|
||||||
# 腾讯专用请求头配置
|
# 腾讯专用请求头配置
|
||||||
headers = {
|
headers = {
|
||||||
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.87 Safari/537.36',
|
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.87 Safari/537.36",
|
||||||
'Accept': 'text/html, application/xhtml xml, */*',
|
"Accept": "text/html, application/xhtml xml, */*",
|
||||||
'Accept-Encoding': 'gbk, GB2312',
|
"Accept-Encoding": "gbk, GB2312",
|
||||||
'Accept-Language': 'zh-cn',
|
"Accept-Language": "zh-cn",
|
||||||
'Content-Type': 'application/x-www-form-urlencoded',
|
"Content-Type": "application/x-www-form-urlencoded",
|
||||||
'Cache-Control': 'no-cache'
|
"Cache-Control": "no-cache",
|
||||||
}
|
}
|
||||||
url = html.unescape(self.params['url'])
|
url = html.unescape(self.params["url"])
|
||||||
if not url.startswith(('http://', 'https://')):
|
if not url.startswith(("http://", "https://")):
|
||||||
return None
|
return None
|
||||||
|
|
||||||
# 创建专用会话
|
# 创建专用会话
|
||||||
@@ -129,223 +150,190 @@ class CQCode:
|
|||||||
headers=headers,
|
headers=headers,
|
||||||
timeout=15,
|
timeout=15,
|
||||||
allow_redirects=True,
|
allow_redirects=True,
|
||||||
stream=True # 流式传输避免大内存问题
|
stream=True, # 流式传输避免大内存问题
|
||||||
)
|
)
|
||||||
|
|
||||||
# 腾讯服务器特殊状态码处理
|
# 腾讯服务器特殊状态码处理
|
||||||
if response.status_code == 400 and 'multimedia.nt.qq.com.cn' in url:
|
if response.status_code == 400 and "multimedia.nt.qq.com.cn" in url:
|
||||||
return None
|
return None
|
||||||
|
|
||||||
if response.status_code != 200:
|
if response.status_code != 200:
|
||||||
raise requests.exceptions.HTTPError(f"HTTP {response.status_code}")
|
raise requests.exceptions.HTTPError(f"HTTP {response.status_code}")
|
||||||
|
|
||||||
# 验证内容类型
|
# 验证内容类型
|
||||||
content_type = response.headers.get('Content-Type', '')
|
content_type = response.headers.get("Content-Type", "")
|
||||||
if not content_type.startswith('image/'):
|
if not content_type.startswith("image/"):
|
||||||
raise ValueError(f"非图片内容类型: {content_type}")
|
raise ValueError(f"非图片内容类型: {content_type}")
|
||||||
|
|
||||||
# 转换为Base64
|
# 转换为Base64
|
||||||
image_base64 = base64.b64encode(response.content).decode('utf-8')
|
image_base64 = base64.b64encode(response.content).decode("utf-8")
|
||||||
self.image_base64 = image_base64
|
self.image_base64 = image_base64
|
||||||
return image_base64
|
return image_base64
|
||||||
|
|
||||||
except (requests.exceptions.SSLError, requests.exceptions.HTTPError) as e:
|
except (requests.exceptions.SSLError, requests.exceptions.HTTPError) as e:
|
||||||
if retry == max_retries - 1:
|
if retry == max_retries - 1:
|
||||||
print(f"\033[1;31m[致命错误]\033[0m 最终请求失败: {str(e)}")
|
logger.error(f"最终请求失败: {str(e)}")
|
||||||
time.sleep(1.5 ** retry) # 指数退避
|
time.sleep(1.5**retry) # 指数退避
|
||||||
|
|
||||||
except Exception as e:
|
except Exception:
|
||||||
print(f"\033[1;33m[未知错误]\033[0m {str(e)}")
|
logger.exception("[未知错误]")
|
||||||
return None
|
return None
|
||||||
|
|
||||||
return None
|
return None
|
||||||
|
|
||||||
async def translate_emoji(self) -> str:
|
def translate_image(self) -> Optional[str]:
|
||||||
"""处理表情包类型的CQ码"""
|
"""处理图片类型的CQ码,返回base64字符串"""
|
||||||
if 'url' not in self.params:
|
if "url" not in self.params:
|
||||||
return '[表情包]'
|
return None
|
||||||
base64_str = self.get_img()
|
return self.get_img()
|
||||||
if base64_str:
|
|
||||||
# 将 base64 字符串转换为字节类型
|
|
||||||
image_bytes = base64.b64decode(base64_str)
|
|
||||||
storage_emoji(image_bytes)
|
|
||||||
return await self.get_emoji_description(base64_str)
|
|
||||||
else:
|
|
||||||
return '[表情包]'
|
|
||||||
|
|
||||||
async def translate_image(self) -> str:
|
def translate_forward(self) -> Optional[List[Seg]]:
|
||||||
"""处理图片类型的CQ码,区分普通图片和表情包"""
|
"""处理转发消息,返回Seg列表"""
|
||||||
# 没有url,直接返回默认文本
|
|
||||||
if 'url' not in self.params:
|
|
||||||
return '[图片]'
|
|
||||||
base64_str = self.get_img()
|
|
||||||
if base64_str:
|
|
||||||
image_bytes = base64.b64decode(base64_str)
|
|
||||||
storage_image(image_bytes)
|
|
||||||
return await self.get_image_description(base64_str)
|
|
||||||
else:
|
|
||||||
return '[图片]'
|
|
||||||
|
|
||||||
async def get_emoji_description(self, image_base64: str) -> str:
|
|
||||||
"""调用AI接口获取表情包描述"""
|
|
||||||
try:
|
try:
|
||||||
prompt = "这是一个表情包,请用简短的中文描述这个表情包传达的情感和含义。最多20个字。"
|
if "content" not in self.params:
|
||||||
# description, _ = self._llm.generate_response_for_image_sync(prompt, image_base64)
|
return None
|
||||||
description, _ = await self._llm.generate_response_for_image(prompt, image_base64)
|
|
||||||
return f"[表情包:{description}]"
|
|
||||||
except Exception as e:
|
|
||||||
print(f"\033[1;31m[错误]\033[0m AI接口调用失败: {str(e)}")
|
|
||||||
return "[表情包]"
|
|
||||||
|
|
||||||
async def get_image_description(self, image_base64: str) -> str:
|
content = self.unescape(self.params["content"])
|
||||||
"""调用AI接口获取普通图片描述"""
|
|
||||||
try:
|
|
||||||
prompt = "请用中文描述这张图片的内容。如果有文字,请把文字都描述出来。并尝试猜测这个图片的含义。最多200个字。"
|
|
||||||
# description, _ = self._llm.generate_response_for_image_sync(prompt, image_base64)
|
|
||||||
description, _ = await self._llm.generate_response_for_image(prompt, image_base64)
|
|
||||||
return f"[图片:{description}]"
|
|
||||||
except Exception as e:
|
|
||||||
print(f"\033[1;31m[错误]\033[0m AI接口调用失败: {str(e)}")
|
|
||||||
return "[图片]"
|
|
||||||
|
|
||||||
async def translate_forward(self) -> str:
|
|
||||||
"""处理转发消息"""
|
|
||||||
try:
|
|
||||||
if 'content' not in self.params:
|
|
||||||
return '[转发消息]'
|
|
||||||
|
|
||||||
# 解析content内容(需要先反转义)
|
|
||||||
content = self.unescape(self.params['content'])
|
|
||||||
# print(f"\033[1;34m[调试信息]\033[0m 转发消息内容: {content}")
|
|
||||||
# 将字符串形式的列表转换为Python对象
|
|
||||||
import ast
|
import ast
|
||||||
|
|
||||||
try:
|
try:
|
||||||
messages = ast.literal_eval(content)
|
messages = ast.literal_eval(content)
|
||||||
except ValueError as e:
|
except ValueError as e:
|
||||||
print(f"\033[1;31m[错误]\033[0m 解析转发消息内容失败: {str(e)}")
|
logger.error(f"解析转发消息内容失败: {str(e)}")
|
||||||
return '[转发消息]'
|
return None
|
||||||
|
|
||||||
# 处理每条消息
|
formatted_segments = []
|
||||||
formatted_messages = []
|
|
||||||
for msg in messages:
|
for msg in messages:
|
||||||
sender = msg.get('sender', {})
|
sender = msg.get("sender", {})
|
||||||
nickname = sender.get('card') or sender.get('nickname', '未知用户')
|
nickname = sender.get("card") or sender.get("nickname", "未知用户")
|
||||||
|
raw_message = msg.get("raw_message", "")
|
||||||
# 获取消息内容并使用Message类处理
|
message_array = msg.get("message", [])
|
||||||
raw_message = msg.get('raw_message', '')
|
|
||||||
message_array = msg.get('message', [])
|
|
||||||
|
|
||||||
if message_array and isinstance(message_array, list):
|
if message_array and isinstance(message_array, list):
|
||||||
# 检查是否包含嵌套的转发消息
|
|
||||||
for message_part in message_array:
|
for message_part in message_array:
|
||||||
if message_part.get('type') == 'forward':
|
if message_part.get("type") == "forward":
|
||||||
content = '[转发消息]'
|
content_seg = Seg(type="text", data="[转发消息]")
|
||||||
break
|
break
|
||||||
else:
|
else:
|
||||||
# 处理普通消息
|
|
||||||
if raw_message:
|
if raw_message:
|
||||||
from .message import Message
|
from .message_cq import MessageRecvCQ
|
||||||
message_obj = Message(
|
user_info=UserInfo(
|
||||||
user_id=msg.get('user_id', 0),
|
platform='qq',
|
||||||
message_id=msg.get('message_id', 0),
|
user_id=msg.get("user_id", 0),
|
||||||
|
user_nickname=nickname,
|
||||||
|
)
|
||||||
|
group_info=GroupInfo(
|
||||||
|
platform='qq',
|
||||||
|
group_id=msg.get("group_id", 0),
|
||||||
|
group_name=get_groupname(msg.get("group_id", 0))
|
||||||
|
)
|
||||||
|
|
||||||
|
message_obj = MessageRecvCQ(
|
||||||
|
message_id=msg.get("message_id", 0),
|
||||||
|
user_info=user_info,
|
||||||
raw_message=raw_message,
|
raw_message=raw_message,
|
||||||
plain_text=raw_message,
|
plain_text=raw_message,
|
||||||
group_id=msg.get('group_id', 0)
|
group_info=group_info,
|
||||||
|
)
|
||||||
|
content_seg = Seg(
|
||||||
|
type="seglist", data=[message_obj.message_segment]
|
||||||
)
|
)
|
||||||
await message_obj.initialize()
|
|
||||||
content = message_obj.processed_plain_text
|
|
||||||
else:
|
else:
|
||||||
content = '[空消息]'
|
content_seg = Seg(type="text", data="[空消息]")
|
||||||
else:
|
else:
|
||||||
# 处理普通消息
|
|
||||||
if raw_message:
|
if raw_message:
|
||||||
from .message import Message
|
from .message_cq import MessageRecvCQ
|
||||||
message_obj = Message(
|
|
||||||
user_id=msg.get('user_id', 0),
|
user_info=UserInfo(
|
||||||
message_id=msg.get('message_id', 0),
|
platform='qq',
|
||||||
|
user_id=msg.get("user_id", 0),
|
||||||
|
user_nickname=nickname,
|
||||||
|
)
|
||||||
|
group_info=GroupInfo(
|
||||||
|
platform='qq',
|
||||||
|
group_id=msg.get("group_id", 0),
|
||||||
|
group_name=get_groupname(msg.get("group_id", 0))
|
||||||
|
)
|
||||||
|
message_obj = MessageRecvCQ(
|
||||||
|
message_id=msg.get("message_id", 0),
|
||||||
|
user_info=user_info,
|
||||||
raw_message=raw_message,
|
raw_message=raw_message,
|
||||||
plain_text=raw_message,
|
plain_text=raw_message,
|
||||||
group_id=msg.get('group_id', 0)
|
group_info=group_info,
|
||||||
|
)
|
||||||
|
content_seg = Seg(
|
||||||
|
type="seglist", data=[message_obj.message_segment]
|
||||||
)
|
)
|
||||||
await message_obj.initialize()
|
|
||||||
content = message_obj.processed_plain_text
|
|
||||||
else:
|
else:
|
||||||
content = '[空消息]'
|
content_seg = Seg(type="text", data="[空消息]")
|
||||||
|
|
||||||
formatted_msg = f"{nickname}: {content}"
|
formatted_segments.append(Seg(type="text", data=f"{nickname}: "))
|
||||||
formatted_messages.append(formatted_msg)
|
formatted_segments.append(content_seg)
|
||||||
|
formatted_segments.append(Seg(type="text", data="\n"))
|
||||||
|
|
||||||
# 合并所有消息
|
return formatted_segments
|
||||||
combined_messages = '\n'.join(formatted_messages)
|
|
||||||
print(f"\033[1;34m[调试信息]\033[0m 合并后的转发消息: {combined_messages}")
|
|
||||||
return f"[转发消息:\n{combined_messages}]"
|
|
||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"\033[1;31m[错误]\033[0m 处理转发消息失败: {str(e)}")
|
logger.error(f"处理转发消息失败: {str(e)}")
|
||||||
return '[转发消息]'
|
return None
|
||||||
|
|
||||||
async def translate_reply(self) -> str:
|
def translate_reply(self) -> Optional[List[Seg]]:
|
||||||
"""处理回复类型的CQ码"""
|
"""处理回复类型的CQ码,返回Seg列表"""
|
||||||
|
from .message_cq import MessageRecvCQ
|
||||||
|
|
||||||
# 创建Message对象
|
if self.reply_message is None:
|
||||||
from .message import Message
|
return None
|
||||||
if self.reply_message == None:
|
|
||||||
# print(f"\033[1;31m[错误]\033[0m 回复消息为空")
|
|
||||||
return '[回复某人消息]'
|
|
||||||
|
|
||||||
if self.reply_message.sender.user_id:
|
if self.reply_message.sender.user_id:
|
||||||
message_obj = Message(
|
|
||||||
user_id=self.reply_message.sender.user_id,
|
message_obj = MessageRecvCQ(
|
||||||
|
user_info=UserInfo(user_id=self.reply_message.sender.user_id,user_nickname=self.reply_message.sender.nickname),
|
||||||
message_id=self.reply_message.message_id,
|
message_id=self.reply_message.message_id,
|
||||||
raw_message=str(self.reply_message.message),
|
raw_message=str(self.reply_message.message),
|
||||||
group_id=self.group_id
|
group_info=GroupInfo(group_id=self.reply_message.group_id),
|
||||||
)
|
)
|
||||||
await message_obj.initialize()
|
|
||||||
if message_obj.user_id == global_config.BOT_QQ:
|
|
||||||
return f"[回复 {global_config.BOT_NICKNAME} 的消息: {message_obj.processed_plain_text}]"
|
|
||||||
else:
|
|
||||||
return f"[回复 {self.reply_message.sender.nickname} 的消息: {message_obj.processed_plain_text}]"
|
|
||||||
|
|
||||||
|
|
||||||
|
segments = []
|
||||||
|
if message_obj.message_info.user_info.user_id == global_config.BOT_QQ:
|
||||||
|
segments.append(
|
||||||
|
Seg(
|
||||||
|
type="text", data=f"[回复 {global_config.BOT_NICKNAME} 的消息: "
|
||||||
|
)
|
||||||
|
)
|
||||||
else:
|
else:
|
||||||
print("\033[1;31m[错误]\033[0m 回复消息的sender.user_id为空")
|
segments.append(
|
||||||
return '[回复某人消息]'
|
Seg(
|
||||||
|
type="text",
|
||||||
|
data=f"[回复 {self.reply_message.sender.nickname} 的消息: ",
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
segments.append(Seg(type="seglist", data=[message_obj.message_segment]))
|
||||||
|
segments.append(Seg(type="text", data="]"))
|
||||||
|
return segments
|
||||||
|
else:
|
||||||
|
return None
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def unescape(text: str) -> str:
|
def unescape(text: str) -> str:
|
||||||
"""反转义CQ码中的特殊字符"""
|
"""反转义CQ码中的特殊字符"""
|
||||||
return text.replace(',', ',') \
|
return (
|
||||||
.replace('[', '[') \
|
text.replace(",", ",")
|
||||||
.replace(']', ']') \
|
.replace("[", "[")
|
||||||
.replace('&', '&')
|
.replace("]", "]")
|
||||||
|
.replace("&", "&")
|
||||||
@staticmethod
|
)
|
||||||
def create_emoji_cq(file_path: str) -> str:
|
|
||||||
"""
|
|
||||||
创建表情包CQ码
|
|
||||||
Args:
|
|
||||||
file_path: 本地表情包文件路径
|
|
||||||
Returns:
|
|
||||||
表情包CQ码字符串
|
|
||||||
"""
|
|
||||||
# 确保使用绝对路径
|
|
||||||
abs_path = os.path.abspath(file_path)
|
|
||||||
# 转义特殊字符
|
|
||||||
escaped_path = abs_path.replace('&', '&') \
|
|
||||||
.replace('[', '[') \
|
|
||||||
.replace(']', ']') \
|
|
||||||
.replace(',', ',')
|
|
||||||
# 生成CQ码,设置sub_type=1表示这是表情包
|
|
||||||
return f"[CQ:image,file=file:///{escaped_path},sub_type=1]"
|
|
||||||
|
|
||||||
|
|
||||||
class CQCode_tool:
|
class CQCode_tool:
|
||||||
@staticmethod
|
@staticmethod
|
||||||
async def cq_from_dict_to_class(cq_code: Dict, reply: Optional[Dict] = None) -> CQCode:
|
def cq_from_dict_to_class(cq_code: Dict,msg ,reply: Optional[Dict] = None) -> CQCode:
|
||||||
"""
|
"""
|
||||||
将CQ码字典转换为CQCode对象
|
将CQ码字典转换为CQCode对象
|
||||||
|
|
||||||
Args:
|
Args:
|
||||||
cq_code: CQ码字典
|
cq_code: CQ码字典
|
||||||
|
msg: MessageCQ对象
|
||||||
reply: 回复消息的字典(可选)
|
reply: 回复消息的字典(可选)
|
||||||
|
|
||||||
Returns:
|
Returns:
|
||||||
@@ -353,23 +341,23 @@ class CQCode_tool:
|
|||||||
"""
|
"""
|
||||||
# 处理字典形式的CQ码
|
# 处理字典形式的CQ码
|
||||||
# 从cq_code字典中获取type字段的值,如果不存在则默认为'text'
|
# 从cq_code字典中获取type字段的值,如果不存在则默认为'text'
|
||||||
cq_type = cq_code.get('type', 'text')
|
cq_type = cq_code.get("type", "text")
|
||||||
params = {}
|
params = {}
|
||||||
if cq_type == 'text':
|
if cq_type == "text":
|
||||||
params['text'] = cq_code.get('data', {}).get('text', '')
|
params["text"] = cq_code.get("data", {}).get("text", "")
|
||||||
else:
|
else:
|
||||||
params = cq_code.get('data', {})
|
params = cq_code.get("data", {})
|
||||||
|
|
||||||
instance = CQCode(
|
instance = CQCode(
|
||||||
type=cq_type,
|
type=cq_type,
|
||||||
params=params,
|
params=params,
|
||||||
group_id=0,
|
group_info=msg.message_info.group_info,
|
||||||
user_id=0,
|
user_info=msg.message_info.user_info,
|
||||||
reply_message=reply
|
reply_message=reply
|
||||||
)
|
)
|
||||||
|
|
||||||
# 进行翻译处理
|
# 进行翻译处理
|
||||||
await instance.translate()
|
instance.translate()
|
||||||
return instance
|
return instance
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
@@ -383,5 +371,64 @@ class CQCode_tool:
|
|||||||
"""
|
"""
|
||||||
return f"[CQ:reply,id={message_id}]"
|
return f"[CQ:reply,id={message_id}]"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def create_emoji_cq(file_path: str) -> str:
|
||||||
|
"""
|
||||||
|
创建表情包CQ码
|
||||||
|
Args:
|
||||||
|
file_path: 本地表情包文件路径
|
||||||
|
Returns:
|
||||||
|
表情包CQ码字符串
|
||||||
|
"""
|
||||||
|
# 确保使用绝对路径
|
||||||
|
abs_path = os.path.abspath(file_path)
|
||||||
|
# 转义特殊字符
|
||||||
|
escaped_path = (
|
||||||
|
abs_path.replace("&", "&")
|
||||||
|
.replace("[", "[")
|
||||||
|
.replace("]", "]")
|
||||||
|
.replace(",", ",")
|
||||||
|
)
|
||||||
|
# 生成CQ码,设置sub_type=1表示这是表情包
|
||||||
|
return f"[CQ:image,file=file:///{escaped_path},sub_type=1]"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def create_emoji_cq_base64(base64_data: str) -> str:
|
||||||
|
"""
|
||||||
|
创建表情包CQ码
|
||||||
|
Args:
|
||||||
|
base64_data: base64编码的表情包数据
|
||||||
|
Returns:
|
||||||
|
表情包CQ码字符串
|
||||||
|
"""
|
||||||
|
# 转义base64数据
|
||||||
|
escaped_base64 = (
|
||||||
|
base64_data.replace("&", "&")
|
||||||
|
.replace("[", "[")
|
||||||
|
.replace("]", "]")
|
||||||
|
.replace(",", ",")
|
||||||
|
)
|
||||||
|
# 生成CQ码,设置sub_type=1表示这是表情包
|
||||||
|
return f"[CQ:image,file=base64://{escaped_base64},sub_type=1]"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def create_image_cq_base64(base64_data: str) -> str:
|
||||||
|
"""
|
||||||
|
创建表情包CQ码
|
||||||
|
Args:
|
||||||
|
base64_data: base64编码的表情包数据
|
||||||
|
Returns:
|
||||||
|
表情包CQ码字符串
|
||||||
|
"""
|
||||||
|
# 转义base64数据
|
||||||
|
escaped_base64 = (
|
||||||
|
base64_data.replace("&", "&")
|
||||||
|
.replace("[", "[")
|
||||||
|
.replace("]", "]")
|
||||||
|
.replace(",", ",")
|
||||||
|
)
|
||||||
|
# 生成CQ码,设置sub_type=1表示这是表情包
|
||||||
|
return f"[CQ:image,file=base64://{escaped_base64},sub_type=0]"
|
||||||
|
|
||||||
|
|
||||||
cq_code_tool = CQCode_tool()
|
cq_code_tool = CQCode_tool()
|
||||||
|
|||||||
@@ -1,39 +1,44 @@
|
|||||||
import asyncio
|
import asyncio
|
||||||
|
import base64
|
||||||
|
import hashlib
|
||||||
import os
|
import os
|
||||||
import random
|
import random
|
||||||
import time
|
import time
|
||||||
import traceback
|
import traceback
|
||||||
from typing import Optional
|
from typing import Optional, Tuple
|
||||||
|
from PIL import Image
|
||||||
|
import io
|
||||||
|
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
from nonebot import get_driver
|
from nonebot import get_driver
|
||||||
|
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
from ..chat.config import global_config
|
from ..chat.config import global_config
|
||||||
from ..chat.utils import get_embedding
|
from ..chat.utils import get_embedding
|
||||||
from ..chat.utils_image import image_path_to_base64
|
from ..chat.utils_image import ImageManager, image_path_to_base64
|
||||||
from ..models.utils_model import LLM_request
|
from ..models.utils_model import LLM_request
|
||||||
|
|
||||||
driver = get_driver()
|
driver = get_driver()
|
||||||
config = driver.config
|
config = driver.config
|
||||||
|
image_manager = ImageManager()
|
||||||
|
|
||||||
|
|
||||||
class EmojiManager:
|
class EmojiManager:
|
||||||
_instance = None
|
_instance = None
|
||||||
EMOJI_DIR = "data/emoji" # 表情包存储目录
|
EMOJI_DIR = os.path.join("data", "emoji") # 表情包存储目录
|
||||||
|
|
||||||
def __new__(cls):
|
def __new__(cls):
|
||||||
if cls._instance is None:
|
if cls._instance is None:
|
||||||
cls._instance = super().__new__(cls)
|
cls._instance = super().__new__(cls)
|
||||||
cls._instance.db = None
|
|
||||||
cls._instance._initialized = False
|
cls._instance._initialized = False
|
||||||
return cls._instance
|
return cls._instance
|
||||||
|
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.db = Database.get_instance()
|
|
||||||
self._scan_task = None
|
self._scan_task = None
|
||||||
self.vlm = LLM_request(model=global_config.vlm, temperature=0.3, max_tokens=1000)
|
self.vlm = LLM_request(model=global_config.vlm, temperature=0.3, max_tokens=1000)
|
||||||
self.llm_emotion_judge = LLM_request(model=global_config.llm_emotion_judge, max_tokens=60,temperature=0.8) #更高的温度,更少的token(后续可以根据情绪来调整温度)
|
self.llm_emotion_judge = LLM_request(
|
||||||
|
model=global_config.llm_emotion_judge, max_tokens=60, temperature=0.8
|
||||||
|
) # 更高的温度,更少的token(后续可以根据情绪来调整温度)
|
||||||
|
|
||||||
def _ensure_emoji_dir(self):
|
def _ensure_emoji_dir(self):
|
||||||
"""确保表情存储目录存在"""
|
"""确保表情存储目录存在"""
|
||||||
@@ -43,14 +48,13 @@ class EmojiManager:
|
|||||||
"""初始化数据库连接和表情目录"""
|
"""初始化数据库连接和表情目录"""
|
||||||
if not self._initialized:
|
if not self._initialized:
|
||||||
try:
|
try:
|
||||||
self.db = Database.get_instance()
|
|
||||||
self._ensure_emoji_collection()
|
self._ensure_emoji_collection()
|
||||||
self._ensure_emoji_dir()
|
self._ensure_emoji_dir()
|
||||||
self._initialized = True
|
self._initialized = True
|
||||||
# 启动时执行一次完整性检查
|
# 启动时执行一次完整性检查
|
||||||
self.check_emoji_file_integrity()
|
self.check_emoji_file_integrity()
|
||||||
except Exception as e:
|
except Exception:
|
||||||
logger.error(f"初始化表情管理器失败: {str(e)}")
|
logger.exception("初始化表情管理器失败")
|
||||||
|
|
||||||
def _ensure_db(self):
|
def _ensure_db(self):
|
||||||
"""确保数据库已初始化"""
|
"""确保数据库已初始化"""
|
||||||
@@ -71,24 +75,20 @@ class EmojiManager:
|
|||||||
|
|
||||||
没有索引的话,数据库每次查询都需要扫描全部数据,建立索引后可以大大提高查询效率。
|
没有索引的话,数据库每次查询都需要扫描全部数据,建立索引后可以大大提高查询效率。
|
||||||
"""
|
"""
|
||||||
if 'emoji' not in self.db.db.list_collection_names():
|
if "emoji" not in db.list_collection_names():
|
||||||
self.db.db.create_collection('emoji')
|
db.create_collection("emoji")
|
||||||
self.db.db.emoji.create_index([('embedding', '2dsphere')])
|
db.emoji.create_index([("embedding", "2dsphere")])
|
||||||
self.db.db.emoji.create_index([('tags', 1)])
|
db.emoji.create_index([("filename", 1)], unique=True)
|
||||||
self.db.db.emoji.create_index([('filename', 1)], unique=True)
|
|
||||||
|
|
||||||
def record_usage(self, emoji_id: str):
|
def record_usage(self, emoji_id: str):
|
||||||
"""记录表情使用次数"""
|
"""记录表情使用次数"""
|
||||||
try:
|
try:
|
||||||
self._ensure_db()
|
self._ensure_db()
|
||||||
self.db.db.emoji.update_one(
|
db.emoji.update_one({"_id": emoji_id}, {"$inc": {"usage_count": 1}})
|
||||||
{'_id': emoji_id},
|
|
||||||
{'$inc': {'usage_count': 1}}
|
|
||||||
)
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logger.error(f"记录表情使用失败: {str(e)}")
|
logger.error(f"记录表情使用失败: {str(e)}")
|
||||||
|
|
||||||
async def get_emoji_for_text(self, text: str) -> Optional[str]:
|
async def get_emoji_for_text(self, text: str) -> Optional[Tuple[str, str]]:
|
||||||
"""根据文本内容获取相关表情包
|
"""根据文本内容获取相关表情包
|
||||||
Args:
|
Args:
|
||||||
text: 输入文本
|
text: 输入文本
|
||||||
@@ -104,7 +104,7 @@ class EmojiManager:
|
|||||||
self._ensure_db()
|
self._ensure_db()
|
||||||
|
|
||||||
# 获取文本的embedding
|
# 获取文本的embedding
|
||||||
text_for_search= await self._get_kimoji_for_text(text)
|
text_for_search = await self._get_kimoji_for_text(text)
|
||||||
if not text_for_search:
|
if not text_for_search:
|
||||||
logger.error("无法获取文本的情绪")
|
logger.error("无法获取文本的情绪")
|
||||||
return None
|
return None
|
||||||
@@ -115,7 +115,7 @@ class EmojiManager:
|
|||||||
|
|
||||||
try:
|
try:
|
||||||
# 获取所有表情包
|
# 获取所有表情包
|
||||||
all_emojis = list(self.db.db.emoji.find({}, {'_id': 1, 'path': 1, 'embedding': 1, 'discription': 1}))
|
all_emojis = list(db.emoji.find({}, {"_id": 1, "path": 1, "embedding": 1, "description": 1}))
|
||||||
|
|
||||||
if not all_emojis:
|
if not all_emojis:
|
||||||
logger.warning("数据库中没有任何表情包")
|
logger.warning("数据库中没有任何表情包")
|
||||||
@@ -134,32 +134,31 @@ class EmojiManager:
|
|||||||
|
|
||||||
# 计算所有表情包与输入文本的相似度
|
# 计算所有表情包与输入文本的相似度
|
||||||
emoji_similarities = [
|
emoji_similarities = [
|
||||||
(emoji, cosine_similarity(text_embedding, emoji.get('embedding', [])))
|
(emoji, cosine_similarity(text_embedding, emoji.get("embedding", []))) for emoji in all_emojis
|
||||||
for emoji in all_emojis
|
|
||||||
]
|
]
|
||||||
|
|
||||||
# 按相似度降序排序
|
# 按相似度降序排序
|
||||||
emoji_similarities.sort(key=lambda x: x[1], reverse=True)
|
emoji_similarities.sort(key=lambda x: x[1], reverse=True)
|
||||||
|
|
||||||
# 获取前3个最相似的表情包
|
# 获取前3个最相似的表情包
|
||||||
top_3_emojis = emoji_similarities[:3]
|
top_10_emojis = emoji_similarities[: 10 if len(emoji_similarities) > 10 else len(emoji_similarities)]
|
||||||
|
|
||||||
if not top_3_emojis:
|
if not top_10_emojis:
|
||||||
logger.warning("未找到匹配的表情包")
|
logger.warning("未找到匹配的表情包")
|
||||||
return None
|
return None
|
||||||
|
|
||||||
# 从前3个中随机选择一个
|
# 从前3个中随机选择一个
|
||||||
selected_emoji, similarity = random.choice(top_3_emojis)
|
selected_emoji, similarity = random.choice(top_10_emojis)
|
||||||
|
|
||||||
if selected_emoji and 'path' in selected_emoji:
|
if selected_emoji and "path" in selected_emoji:
|
||||||
# 更新使用次数
|
# 更新使用次数
|
||||||
self.db.db.emoji.update_one(
|
db.emoji.update_one({"_id": selected_emoji["_id"]}, {"$inc": {"usage_count": 1}})
|
||||||
{'_id': selected_emoji['_id']},
|
|
||||||
{'$inc': {'usage_count': 1}}
|
logger.success(
|
||||||
|
f"找到匹配的表情包: {selected_emoji.get('description', '无描述')} (相似度: {similarity:.4f})"
|
||||||
)
|
)
|
||||||
logger.success(f"找到匹配的表情包: {selected_emoji.get('discription', '无描述')} (相似度: {similarity:.4f})")
|
|
||||||
# 稍微改一下文本描述,不然容易产生幻觉,描述已经包含 表情包 了
|
# 稍微改一下文本描述,不然容易产生幻觉,描述已经包含 表情包 了
|
||||||
return selected_emoji['path'],"[ %s ]" % selected_emoji.get('discription', '无描述')
|
return selected_emoji["path"], "[ %s ]" % selected_emoji.get("description", "无描述")
|
||||||
|
|
||||||
except Exception as search_error:
|
except Exception as search_error:
|
||||||
logger.error(f"搜索表情包失败: {str(search_error)}")
|
logger.error(f"搜索表情包失败: {str(search_error)}")
|
||||||
@@ -172,11 +171,24 @@ class EmojiManager:
|
|||||||
return None
|
return None
|
||||||
|
|
||||||
async def _get_emoji_discription(self, image_base64: str) -> str:
|
async def _get_emoji_discription(self, image_base64: str) -> str:
|
||||||
"""获取表情包的标签"""
|
"""获取表情包的标签,使用image_manager的描述生成功能"""
|
||||||
try:
|
|
||||||
prompt = '这是一个表情包,使用中文简洁的描述一下表情包的内容和表情包所表达的情感'
|
|
||||||
|
|
||||||
content, _ = await self.vlm.generate_response_for_image(prompt, image_base64)
|
try:
|
||||||
|
# 使用image_manager获取描述,去掉前后的方括号和"表情包:"前缀
|
||||||
|
description = await image_manager.get_emoji_description(image_base64)
|
||||||
|
# 去掉[表情包:xxx]的格式,只保留描述内容
|
||||||
|
description = description.strip("[]").replace("表情包:", "")
|
||||||
|
return description
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"获取标签失败: {str(e)}")
|
||||||
|
return None
|
||||||
|
|
||||||
|
async def _check_emoji(self, image_base64: str, image_format: str) -> str:
|
||||||
|
try:
|
||||||
|
prompt = f'这是一个表情包,请回答这个表情包是否满足"{global_config.EMOJI_CHECK_PROMPT}"的要求,是则回答是,否则回答否,不要出现任何其他内容'
|
||||||
|
|
||||||
|
content, _ = await self.vlm.generate_response_for_image(prompt, image_base64, image_format)
|
||||||
logger.debug(f"输出描述: {content}")
|
logger.debug(f"输出描述: {content}")
|
||||||
return content
|
return content
|
||||||
|
|
||||||
@@ -184,23 +196,11 @@ class EmojiManager:
|
|||||||
logger.error(f"获取标签失败: {str(e)}")
|
logger.error(f"获取标签失败: {str(e)}")
|
||||||
return None
|
return None
|
||||||
|
|
||||||
async def _check_emoji(self, image_base64: str) -> str:
|
async def _get_kimoji_for_text(self, text: str):
|
||||||
try:
|
try:
|
||||||
prompt = f'这是一个表情包,请回答这个表情包是否满足\"{global_config.EMOJI_CHECK_PROMPT}\"的要求,是则回答是,否则回答否,不要出现任何其他内容'
|
prompt = f'这是{global_config.BOT_NICKNAME}将要发送的消息内容:\n{text}\n若要为其配上表情包,请你输出这个表情包应该表达怎样的情感,应该给人什么样的感觉,不要太简洁也不要太长,注意不要输出任何对消息内容的分析内容,只输出"一种什么样的感觉"中间的形容词部分。'
|
||||||
|
|
||||||
content, _ = await self.vlm.generate_response_for_image(prompt, image_base64)
|
content, _ = await self.llm_emotion_judge.generate_response_async(prompt, temperature=1.5)
|
||||||
logger.debug(f"输出描述: {content}")
|
|
||||||
return content
|
|
||||||
|
|
||||||
except Exception as e:
|
|
||||||
logger.error(f"获取标签失败: {str(e)}")
|
|
||||||
return None
|
|
||||||
|
|
||||||
async def _get_kimoji_for_text(self, text:str):
|
|
||||||
try:
|
|
||||||
prompt = f'这是{global_config.BOT_NICKNAME}将要发送的消息内容:\n{text}\n若要为其配上表情包,请你输出这个表情包应该表达怎样的情感,应该给人什么样的感觉,不要太简洁也不要太长,注意不要输出任何对消息内容的分析内容,只输出\"一种什么样的感觉\"中间的形容词部分。'
|
|
||||||
|
|
||||||
content, _ = await self.llm_emotion_judge.generate_response_async(prompt)
|
|
||||||
logger.info(f"输出描述: {content}")
|
logger.info(f"输出描述: {content}")
|
||||||
return content
|
return content
|
||||||
|
|
||||||
@@ -211,67 +211,116 @@ class EmojiManager:
|
|||||||
async def scan_new_emojis(self):
|
async def scan_new_emojis(self):
|
||||||
"""扫描新的表情包"""
|
"""扫描新的表情包"""
|
||||||
try:
|
try:
|
||||||
emoji_dir = "data/emoji"
|
emoji_dir = self.EMOJI_DIR
|
||||||
os.makedirs(emoji_dir, exist_ok=True)
|
os.makedirs(emoji_dir, exist_ok=True)
|
||||||
|
|
||||||
# 获取所有支持的图片文件
|
# 获取所有支持的图片文件
|
||||||
files_to_process = [f for f in os.listdir(emoji_dir) if f.lower().endswith(('.jpg', '.jpeg', '.png', '.gif'))]
|
files_to_process = [
|
||||||
|
f for f in os.listdir(emoji_dir) if f.lower().endswith((".jpg", ".jpeg", ".png", ".gif"))
|
||||||
|
]
|
||||||
|
|
||||||
for filename in files_to_process:
|
for filename in files_to_process:
|
||||||
image_path = os.path.join(emoji_dir, filename)
|
image_path = os.path.join(emoji_dir, filename)
|
||||||
|
|
||||||
# 检查是否已经注册过
|
# 获取图片的base64编码和哈希值
|
||||||
existing_emoji = self.db.db['emoji'].find_one({'filename': filename})
|
|
||||||
if existing_emoji:
|
|
||||||
continue
|
|
||||||
|
|
||||||
# 压缩图片并获取base64编码
|
|
||||||
image_base64 = image_path_to_base64(image_path)
|
image_base64 = image_path_to_base64(image_path)
|
||||||
if image_base64 is None:
|
if image_base64 is None:
|
||||||
os.remove(image_path)
|
os.remove(image_path)
|
||||||
continue
|
continue
|
||||||
|
|
||||||
|
image_bytes = base64.b64decode(image_base64)
|
||||||
|
image_hash = hashlib.md5(image_bytes).hexdigest()
|
||||||
|
image_format = Image.open(io.BytesIO(image_bytes)).format.lower()
|
||||||
|
# 检查是否已经注册过
|
||||||
|
existing_emoji = db["emoji"].find_one({"hash": image_hash})
|
||||||
|
description = None
|
||||||
|
|
||||||
|
if existing_emoji:
|
||||||
|
# 即使表情包已存在,也检查是否需要同步到images集合
|
||||||
|
description = existing_emoji.get("discription")
|
||||||
|
# 检查是否在images集合中存在
|
||||||
|
existing_image = db.images.find_one({"hash": image_hash})
|
||||||
|
if not existing_image:
|
||||||
|
# 同步到images集合
|
||||||
|
image_doc = {
|
||||||
|
"hash": image_hash,
|
||||||
|
"path": image_path,
|
||||||
|
"type": "emoji",
|
||||||
|
"description": description,
|
||||||
|
"timestamp": int(time.time()),
|
||||||
|
}
|
||||||
|
db.images.update_one({"hash": image_hash}, {"$set": image_doc}, upsert=True)
|
||||||
|
# 保存描述到image_descriptions集合
|
||||||
|
image_manager._save_description_to_db(image_hash, description, "emoji")
|
||||||
|
logger.success(f"同步已存在的表情包到images集合: {filename}")
|
||||||
|
continue
|
||||||
|
|
||||||
|
# 检查是否在images集合中已有描述
|
||||||
|
existing_description = image_manager._get_description_from_db(image_hash, "emoji")
|
||||||
|
|
||||||
|
if existing_description:
|
||||||
|
description = existing_description
|
||||||
|
else:
|
||||||
# 获取表情包的描述
|
# 获取表情包的描述
|
||||||
discription = await self._get_emoji_discription(image_base64)
|
description = await self._get_emoji_discription(image_base64)
|
||||||
|
|
||||||
if global_config.EMOJI_CHECK:
|
if global_config.EMOJI_CHECK:
|
||||||
check = await self._check_emoji(image_base64)
|
check = await self._check_emoji(image_base64, image_format)
|
||||||
if '是' not in check:
|
if "是" not in check:
|
||||||
os.remove(image_path)
|
os.remove(image_path)
|
||||||
logger.info(f"描述: {discription}")
|
logger.info(f"描述: {description}")
|
||||||
|
|
||||||
|
logger.info(f"描述: {description}")
|
||||||
logger.info(f"其不满足过滤规则,被剔除 {check}")
|
logger.info(f"其不满足过滤规则,被剔除 {check}")
|
||||||
continue
|
continue
|
||||||
logger.info(f"check通过 {check}")
|
logger.info(f"check通过 {check}")
|
||||||
|
|
||||||
if discription is not None:
|
if description is not None:
|
||||||
embedding = await get_embedding(discription)
|
embedding = await get_embedding(description)
|
||||||
|
|
||||||
|
if description is not None:
|
||||||
|
embedding = await get_embedding(description)
|
||||||
|
|
||||||
# 准备数据库记录
|
# 准备数据库记录
|
||||||
emoji_record = {
|
emoji_record = {
|
||||||
'filename': filename,
|
"filename": filename,
|
||||||
'path': image_path,
|
"path": image_path,
|
||||||
'embedding':embedding,
|
"embedding": embedding,
|
||||||
'discription': discription,
|
"discription": description,
|
||||||
'timestamp': int(time.time())
|
"hash": image_hash,
|
||||||
|
"timestamp": int(time.time()),
|
||||||
}
|
}
|
||||||
|
|
||||||
# 保存到数据库
|
# 保存到emoji数据库
|
||||||
self.db.db['emoji'].insert_one(emoji_record)
|
db["emoji"].insert_one(emoji_record)
|
||||||
logger.success(f"注册新表情包: {filename}")
|
logger.success(f"注册新表情包: {filename}")
|
||||||
logger.info(f"描述: {discription}")
|
logger.info(f"描述: {description}")
|
||||||
|
|
||||||
|
# 保存到images数据库
|
||||||
|
image_doc = {
|
||||||
|
"hash": image_hash,
|
||||||
|
"path": image_path,
|
||||||
|
"type": "emoji",
|
||||||
|
"description": description,
|
||||||
|
"timestamp": int(time.time()),
|
||||||
|
}
|
||||||
|
db.images.update_one({"hash": image_hash}, {"$set": image_doc}, upsert=True)
|
||||||
|
# 保存描述到image_descriptions集合
|
||||||
|
image_manager._save_description_to_db(image_hash, description, "emoji")
|
||||||
|
logger.success(f"同步保存到images集合: {filename}")
|
||||||
else:
|
else:
|
||||||
logger.warning(f"跳过表情包: {filename}")
|
logger.warning(f"跳过表情包: {filename}")
|
||||||
|
|
||||||
except Exception as e:
|
except Exception:
|
||||||
logger.error(f"扫描表情包失败: {str(e)}")
|
logger.exception("扫描表情包失败")
|
||||||
logger.error(traceback.format_exc())
|
|
||||||
|
|
||||||
async def _periodic_scan(self, interval_MINS: int = 10):
|
async def _periodic_scan(self, interval_MINS: int = 10):
|
||||||
"""定期扫描新表情包"""
|
"""定期扫描新表情包"""
|
||||||
while True:
|
while True:
|
||||||
print("\033[1;36m[表情包]\033[0m 开始扫描新表情包...")
|
logger.info("开始扫描新表情包...")
|
||||||
await self.scan_new_emojis()
|
await self.scan_new_emojis()
|
||||||
await asyncio.sleep(interval_MINS * 60) # 每600秒扫描一次
|
await asyncio.sleep(interval_MINS * 60) # 每600秒扫描一次
|
||||||
|
|
||||||
|
|
||||||
def check_emoji_file_integrity(self):
|
def check_emoji_file_integrity(self):
|
||||||
"""检查表情包文件完整性
|
"""检查表情包文件完整性
|
||||||
如果文件已被删除,则从数据库中移除对应记录
|
如果文件已被删除,则从数据库中移除对应记录
|
||||||
@@ -279,40 +328,47 @@ class EmojiManager:
|
|||||||
try:
|
try:
|
||||||
self._ensure_db()
|
self._ensure_db()
|
||||||
# 获取所有表情包记录
|
# 获取所有表情包记录
|
||||||
all_emojis = list(self.db.db.emoji.find())
|
all_emojis = list(db.emoji.find())
|
||||||
removed_count = 0
|
removed_count = 0
|
||||||
total_count = len(all_emojis)
|
total_count = len(all_emojis)
|
||||||
|
|
||||||
for emoji in all_emojis:
|
for emoji in all_emojis:
|
||||||
try:
|
try:
|
||||||
if 'path' not in emoji:
|
if "path" not in emoji:
|
||||||
logger.warning(f"发现无效记录(缺少path字段),ID: {emoji.get('_id', 'unknown')}")
|
logger.warning(f"发现无效记录(缺少path字段),ID: {emoji.get('_id', 'unknown')}")
|
||||||
self.db.db.emoji.delete_one({'_id': emoji['_id']})
|
db.emoji.delete_one({"_id": emoji["_id"]})
|
||||||
removed_count += 1
|
removed_count += 1
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if 'embedding' not in emoji:
|
if "embedding" not in emoji:
|
||||||
logger.warning(f"发现过时记录(缺少embedding字段),ID: {emoji.get('_id', 'unknown')}")
|
logger.warning(f"发现过时记录(缺少embedding字段),ID: {emoji.get('_id', 'unknown')}")
|
||||||
self.db.db.emoji.delete_one({'_id': emoji['_id']})
|
db.emoji.delete_one({"_id": emoji["_id"]})
|
||||||
removed_count += 1
|
removed_count += 1
|
||||||
continue
|
continue
|
||||||
|
|
||||||
# 检查文件是否存在
|
# 检查文件是否存在
|
||||||
if not os.path.exists(emoji['path']):
|
if not os.path.exists(emoji["path"]):
|
||||||
logger.warning(f"表情包文件已被删除: {emoji['path']}")
|
logger.warning(f"表情包文件已被删除: {emoji['path']}")
|
||||||
# 从数据库中删除记录
|
# 从数据库中删除记录
|
||||||
result = self.db.db.emoji.delete_one({'_id': emoji['_id']})
|
result = db.emoji.delete_one({"_id": emoji["_id"]})
|
||||||
if result.deleted_count > 0:
|
if result.deleted_count > 0:
|
||||||
logger.success(f"成功删除数据库记录: {emoji['_id']}")
|
logger.debug(f"成功删除数据库记录: {emoji['_id']}")
|
||||||
removed_count += 1
|
removed_count += 1
|
||||||
else:
|
else:
|
||||||
logger.error(f"删除数据库记录失败: {emoji['_id']}")
|
logger.error(f"删除数据库记录失败: {emoji['_id']}")
|
||||||
|
continue
|
||||||
|
|
||||||
|
if "hash" not in emoji:
|
||||||
|
logger.warning(f"发现缺失记录(缺少hash字段),ID: {emoji.get('_id', 'unknown')}")
|
||||||
|
hash = hashlib.md5(open(emoji["path"], "rb").read()).hexdigest()
|
||||||
|
db.emoji.update_one({"_id": emoji["_id"]}, {"$set": {"hash": hash}})
|
||||||
|
|
||||||
except Exception as item_error:
|
except Exception as item_error:
|
||||||
logger.error(f"处理表情包记录时出错: {str(item_error)}")
|
logger.error(f"处理表情包记录时出错: {str(item_error)}")
|
||||||
continue
|
continue
|
||||||
|
|
||||||
# 验证清理结果
|
# 验证清理结果
|
||||||
remaining_count = self.db.db.emoji.count_documents({})
|
remaining_count = db.emoji.count_documents({})
|
||||||
if removed_count > 0:
|
if removed_count > 0:
|
||||||
logger.success(f"已清理 {removed_count} 个失效的表情包记录")
|
logger.success(f"已清理 {removed_count} 个失效的表情包记录")
|
||||||
logger.info(f"清理前总数: {total_count} | 清理后总数: {remaining_count}")
|
logger.info(f"清理前总数: {total_count} | 清理后总数: {remaining_count}")
|
||||||
@@ -329,6 +385,6 @@ class EmojiManager:
|
|||||||
await asyncio.sleep(interval_MINS * 60)
|
await asyncio.sleep(interval_MINS * 60)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
# 创建全局单例
|
# 创建全局单例
|
||||||
|
|
||||||
emoji_manager = EmojiManager()
|
emoji_manager = EmojiManager()
|
||||||
|
|||||||
@@ -3,11 +3,12 @@ import time
|
|||||||
from typing import List, Optional, Tuple, Union
|
from typing import List, Optional, Tuple, Union
|
||||||
|
|
||||||
from nonebot import get_driver
|
from nonebot import get_driver
|
||||||
|
from loguru import logger
|
||||||
|
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
from ..models.utils_model import LLM_request
|
from ..models.utils_model import LLM_request
|
||||||
from .config import global_config
|
from .config import global_config
|
||||||
from .message import Message
|
from .message import MessageRecv, MessageThinking, Message
|
||||||
from .prompt_builder import prompt_builder
|
from .prompt_builder import prompt_builder
|
||||||
from .relationship_manager import relationship_manager
|
from .relationship_manager import relationship_manager
|
||||||
from .utils import process_llm_response
|
from .utils import process_llm_response
|
||||||
@@ -18,48 +19,78 @@ config = driver.config
|
|||||||
|
|
||||||
class ResponseGenerator:
|
class ResponseGenerator:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.model_r1 = LLM_request(model=global_config.llm_reasoning, temperature=0.7,max_tokens=1000,stream=True)
|
self.model_r1 = LLM_request(
|
||||||
self.model_v3 = LLM_request(model=global_config.llm_normal, temperature=0.7,max_tokens=1000)
|
model=global_config.llm_reasoning,
|
||||||
self.model_r1_distill = LLM_request(model=global_config.llm_reasoning_minor, temperature=0.7,max_tokens=1000)
|
temperature=0.7,
|
||||||
self.model_v25 = LLM_request(model=global_config.llm_normal_minor, temperature=0.7,max_tokens=1000)
|
max_tokens=1000,
|
||||||
self.db = Database.get_instance()
|
stream=True,
|
||||||
self.current_model_type = 'r1' # 默认使用 R1
|
)
|
||||||
|
self.model_v3 = LLM_request(
|
||||||
|
model=global_config.llm_normal, temperature=0.7, max_tokens=1000
|
||||||
|
)
|
||||||
|
self.model_r1_distill = LLM_request(
|
||||||
|
model=global_config.llm_reasoning_minor, temperature=0.7, max_tokens=1000
|
||||||
|
)
|
||||||
|
self.model_v25 = LLM_request(
|
||||||
|
model=global_config.llm_normal_minor, temperature=0.7, max_tokens=1000
|
||||||
|
)
|
||||||
|
self.current_model_type = "r1" # 默认使用 R1
|
||||||
|
|
||||||
async def generate_response(self, message: Message) -> Optional[Union[str, List[str]]]:
|
async def generate_response(
|
||||||
|
self, message: MessageThinking
|
||||||
|
) -> Optional[Union[str, List[str]]]:
|
||||||
"""根据当前模型类型选择对应的生成函数"""
|
"""根据当前模型类型选择对应的生成函数"""
|
||||||
# 从global_config中获取模型概率值并选择模型
|
# 从global_config中获取模型概率值并选择模型
|
||||||
rand = random.random()
|
rand = random.random()
|
||||||
if rand < global_config.MODEL_R1_PROBABILITY:
|
if rand < global_config.MODEL_R1_PROBABILITY:
|
||||||
self.current_model_type = 'r1'
|
self.current_model_type = "r1"
|
||||||
current_model = self.model_r1
|
current_model = self.model_r1
|
||||||
elif rand < global_config.MODEL_R1_PROBABILITY + global_config.MODEL_V3_PROBABILITY:
|
elif (
|
||||||
self.current_model_type = 'v3'
|
rand
|
||||||
|
< global_config.MODEL_R1_PROBABILITY + global_config.MODEL_V3_PROBABILITY
|
||||||
|
):
|
||||||
|
self.current_model_type = "v3"
|
||||||
current_model = self.model_v3
|
current_model = self.model_v3
|
||||||
else:
|
else:
|
||||||
self.current_model_type = 'r1_distill'
|
self.current_model_type = "r1_distill"
|
||||||
current_model = self.model_r1_distill
|
current_model = self.model_r1_distill
|
||||||
|
|
||||||
print(f"+++++++++++++++++{global_config.BOT_NICKNAME}{self.current_model_type}思考中+++++++++++++++++")
|
logger.info(f"{global_config.BOT_NICKNAME}{self.current_model_type}思考中")
|
||||||
|
|
||||||
model_response = await self._generate_response_with_model(message, current_model)
|
model_response = await self._generate_response_with_model(
|
||||||
raw_content=model_response
|
message, current_model
|
||||||
|
)
|
||||||
|
raw_content = model_response
|
||||||
|
|
||||||
|
# print(f"raw_content: {raw_content}")
|
||||||
|
# print(f"model_response: {model_response}")
|
||||||
|
|
||||||
if model_response:
|
if model_response:
|
||||||
print(f'{global_config.BOT_NICKNAME}的回复是:{model_response}')
|
logger.info(f'{global_config.BOT_NICKNAME}的回复是:{model_response}')
|
||||||
model_response = await self._process_response(model_response)
|
model_response = await self._process_response(model_response)
|
||||||
if model_response:
|
if model_response:
|
||||||
|
return model_response, raw_content
|
||||||
|
return None, raw_content
|
||||||
|
|
||||||
return model_response ,raw_content
|
async def _generate_response_with_model(
|
||||||
return None,raw_content
|
self, message: MessageThinking, model: LLM_request
|
||||||
|
) -> Optional[str]:
|
||||||
async def _generate_response_with_model(self, message: Message, model: LLM_request) -> Optional[str]:
|
|
||||||
"""使用指定的模型生成回复"""
|
"""使用指定的模型生成回复"""
|
||||||
sender_name = message.user_nickname or f"用户{message.user_id}"
|
sender_name = (
|
||||||
if message.user_cardname:
|
message.chat_stream.user_info.user_nickname
|
||||||
sender_name=f"[({message.user_id}){message.user_nickname}]{message.user_cardname}"
|
or f"用户{message.chat_stream.user_info.user_id}"
|
||||||
|
)
|
||||||
|
if message.chat_stream.user_info.user_cardname:
|
||||||
|
sender_name = f"[({message.chat_stream.user_info.user_id}){message.chat_stream.user_info.user_nickname}]{message.chat_stream.user_info.user_cardname}"
|
||||||
|
|
||||||
# 获取关系值
|
# 获取关系值
|
||||||
relationship_value = relationship_manager.get_relationship(message.user_id).relationship_value if relationship_manager.get_relationship(message.user_id) else 0.0
|
relationship_value = (
|
||||||
|
relationship_manager.get_relationship(
|
||||||
|
message.chat_stream
|
||||||
|
).relationship_value
|
||||||
|
if relationship_manager.get_relationship(message.chat_stream)
|
||||||
|
else 0.0
|
||||||
|
)
|
||||||
if relationship_value != 0.0:
|
if relationship_value != 0.0:
|
||||||
# print(f"\033[1;32m[关系管理]\033[0m 回复中_当前关系值: {relationship_value}")
|
# print(f"\033[1;32m[关系管理]\033[0m 回复中_当前关系值: {relationship_value}")
|
||||||
pass
|
pass
|
||||||
@@ -69,7 +100,7 @@ class ResponseGenerator:
|
|||||||
message_txt=message.processed_plain_text,
|
message_txt=message.processed_plain_text,
|
||||||
sender_name=sender_name,
|
sender_name=sender_name,
|
||||||
relationship_value=relationship_value,
|
relationship_value=relationship_value,
|
||||||
group_id=message.group_id
|
stream_id=message.chat_stream.stream_id,
|
||||||
)
|
)
|
||||||
|
|
||||||
# 读空气模块 简化逻辑,先停用
|
# 读空气模块 简化逻辑,先停用
|
||||||
@@ -92,8 +123,8 @@ class ResponseGenerator:
|
|||||||
# 生成回复
|
# 生成回复
|
||||||
try:
|
try:
|
||||||
content, reasoning_content = await model.generate_response(prompt)
|
content, reasoning_content = await model.generate_response(prompt)
|
||||||
except Exception as e:
|
except Exception:
|
||||||
print(f"生成回复时出错: {e}")
|
logger.exception("生成回复时出错")
|
||||||
return None
|
return None
|
||||||
|
|
||||||
# 保存到数据库
|
# 保存到数据库
|
||||||
@@ -112,34 +143,51 @@ class ResponseGenerator:
|
|||||||
|
|
||||||
# def _save_to_db(self, message: Message, sender_name: str, prompt: str, prompt_check: str,
|
# def _save_to_db(self, message: Message, sender_name: str, prompt: str, prompt_check: str,
|
||||||
# content: str, content_check: str, reasoning_content: str, reasoning_content_check: str):
|
# content: str, content_check: str, reasoning_content: str, reasoning_content_check: str):
|
||||||
def _save_to_db(self, message: Message, sender_name: str, prompt: str, prompt_check: str,
|
def _save_to_db(
|
||||||
content: str, reasoning_content: str,):
|
self,
|
||||||
|
message: MessageRecv,
|
||||||
|
sender_name: str,
|
||||||
|
prompt: str,
|
||||||
|
prompt_check: str,
|
||||||
|
content: str,
|
||||||
|
reasoning_content: str,
|
||||||
|
):
|
||||||
"""保存对话记录到数据库"""
|
"""保存对话记录到数据库"""
|
||||||
self.db.db.reasoning_logs.insert_one({
|
db.reasoning_logs.insert_one(
|
||||||
'time': time.time(),
|
{
|
||||||
'group_id': message.group_id,
|
"time": time.time(),
|
||||||
'user': sender_name,
|
"chat_id": message.chat_stream.stream_id,
|
||||||
'message': message.processed_plain_text,
|
"user": sender_name,
|
||||||
'model': self.current_model_type,
|
"message": message.processed_plain_text,
|
||||||
|
"model": self.current_model_type,
|
||||||
# 'reasoning_check': reasoning_content_check,
|
# 'reasoning_check': reasoning_content_check,
|
||||||
# 'response_check': content_check,
|
# 'response_check': content_check,
|
||||||
'reasoning': reasoning_content,
|
"reasoning": reasoning_content,
|
||||||
'response': content,
|
"response": content,
|
||||||
'prompt': prompt,
|
"prompt": prompt,
|
||||||
'prompt_check': prompt_check
|
"prompt_check": prompt_check,
|
||||||
})
|
}
|
||||||
|
)
|
||||||
|
|
||||||
async def _get_emotion_tags(self, content: str) -> List[str]:
|
async def _get_emotion_tags(self, content: str) -> List[str]:
|
||||||
"""提取情感标签"""
|
"""提取情感标签"""
|
||||||
try:
|
try:
|
||||||
prompt = f'''请从以下内容中,从"happy,angry,sad,surprised,disgusted,fearful,neutral"中选出最匹配的1个情感标签并输出
|
prompt = f"""请从以下内容中,从"happy,angry,sad,surprised,disgusted,fearful,neutral"中选出最匹配的1个情感标签并输出
|
||||||
只输出标签就好,不要输出其他内容:
|
只输出标签就好,不要输出其他内容:
|
||||||
内容:{content}
|
内容:{content}
|
||||||
输出:
|
输出:
|
||||||
'''
|
"""
|
||||||
content, _ = await self.model_v25.generate_response(prompt)
|
content, _ = await self.model_v25.generate_response(prompt)
|
||||||
content=content.strip()
|
content = content.strip()
|
||||||
if content in ['happy','angry','sad','surprised','disgusted','fearful','neutral']:
|
if content in [
|
||||||
|
"happy",
|
||||||
|
"angry",
|
||||||
|
"sad",
|
||||||
|
"surprised",
|
||||||
|
"disgusted",
|
||||||
|
"fearful",
|
||||||
|
"neutral",
|
||||||
|
]:
|
||||||
return [content]
|
return [content]
|
||||||
else:
|
else:
|
||||||
return ["neutral"]
|
return ["neutral"]
|
||||||
@@ -155,12 +203,13 @@ class ResponseGenerator:
|
|||||||
|
|
||||||
processed_response = process_llm_response(content)
|
processed_response = process_llm_response(content)
|
||||||
|
|
||||||
|
# print(f"得到了处理后的llm返回{processed_response}")
|
||||||
|
|
||||||
return processed_response
|
return processed_response
|
||||||
|
|
||||||
|
|
||||||
class InitiativeMessageGenerate:
|
class InitiativeMessageGenerate:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.db = Database.get_instance()
|
|
||||||
self.model_r1 = LLM_request(model=global_config.llm_reasoning, temperature=0.7)
|
self.model_r1 = LLM_request(model=global_config.llm_reasoning, temperature=0.7)
|
||||||
self.model_v3 = LLM_request(model=global_config.llm_normal, temperature=0.7)
|
self.model_v3 = LLM_request(model=global_config.llm_normal, temperature=0.7)
|
||||||
self.model_r1_distill = LLM_request(
|
self.model_r1_distill = LLM_request(
|
||||||
@@ -172,7 +221,7 @@ class InitiativeMessageGenerate:
|
|||||||
prompt_builder._build_initiative_prompt_select(message.group_id)
|
prompt_builder._build_initiative_prompt_select(message.group_id)
|
||||||
)
|
)
|
||||||
content_select, reasoning = self.model_v3.generate_response(topic_select_prompt)
|
content_select, reasoning = self.model_v3.generate_response(topic_select_prompt)
|
||||||
print(f"[DEBUG] {content_select} {reasoning}")
|
logger.debug(f"{content_select} {reasoning}")
|
||||||
topics_list = [dot[0] for dot in dots_for_select]
|
topics_list = [dot[0] for dot in dots_for_select]
|
||||||
if content_select:
|
if content_select:
|
||||||
if content_select in topics_list:
|
if content_select in topics_list:
|
||||||
@@ -185,12 +234,12 @@ class InitiativeMessageGenerate:
|
|||||||
select_dot[1], prompt_template
|
select_dot[1], prompt_template
|
||||||
)
|
)
|
||||||
content_check, reasoning_check = self.model_v3.generate_response(prompt_check)
|
content_check, reasoning_check = self.model_v3.generate_response(prompt_check)
|
||||||
print(f"[DEBUG] {content_check} {reasoning_check}")
|
logger.info(f"{content_check} {reasoning_check}")
|
||||||
if "yes" not in content_check.lower():
|
if "yes" not in content_check.lower():
|
||||||
return None
|
return None
|
||||||
prompt = prompt_builder._build_initiative_prompt(
|
prompt = prompt_builder._build_initiative_prompt(
|
||||||
select_dot, prompt_template, memory
|
select_dot, prompt_template, memory
|
||||||
)
|
)
|
||||||
content, reasoning = self.model_r1.generate_response_async(prompt)
|
content, reasoning = self.model_r1.generate_response_async(prompt)
|
||||||
print(f"[DEBUG] {content} {reasoning}")
|
logger.debug(f"[DEBUG] {content} {reasoning}")
|
||||||
return content
|
return content
|
||||||
|
|||||||
@@ -1,231 +1,412 @@
|
|||||||
import time
|
import time
|
||||||
|
import html
|
||||||
|
import re
|
||||||
|
import json
|
||||||
from dataclasses import dataclass
|
from dataclasses import dataclass
|
||||||
from typing import Dict, ForwardRef, List, Optional
|
from typing import Dict, List, Optional
|
||||||
|
|
||||||
import urllib3
|
import urllib3
|
||||||
|
from loguru import logger
|
||||||
|
|
||||||
from .cq_code import CQCode, cq_code_tool
|
from .utils_image import image_manager
|
||||||
from .utils_cq import parse_cq_code
|
|
||||||
from .utils_user import get_groupname, get_user_cardname, get_user_nickname
|
from .message_base import Seg, GroupInfo, UserInfo, BaseMessageInfo, MessageBase
|
||||||
|
from .chat_stream import ChatStream, chat_manager
|
||||||
|
|
||||||
Message = ForwardRef('Message') # 添加这行
|
|
||||||
# 禁用SSL警告
|
# 禁用SSL警告
|
||||||
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
|
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
|
||||||
|
|
||||||
#这个类是消息数据类,用于存储和管理消息数据。
|
# 这个类是消息数据类,用于存储和管理消息数据。
|
||||||
#它定义了消息的属性,包括群组ID、用户ID、消息ID、原始消息内容、纯文本内容和时间戳。
|
# 它定义了消息的属性,包括群组ID、用户ID、消息ID、原始消息内容、纯文本内容和时间戳。
|
||||||
#它还定义了两个辅助属性:keywords用于提取消息的关键词,is_plain_text用于判断消息是否为纯文本。
|
# 它还定义了两个辅助属性:keywords用于提取消息的关键词,is_plain_text用于判断消息是否为纯文本。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@dataclass
|
@dataclass
|
||||||
class Message:
|
class Message(MessageBase):
|
||||||
"""消息数据类"""
|
chat_stream: ChatStream = None
|
||||||
message_id: int = None
|
reply: Optional["Message"] = None
|
||||||
time: float = None
|
detailed_plain_text: str = ""
|
||||||
|
processed_plain_text: str = ""
|
||||||
|
|
||||||
group_id: int = None
|
def __init__(
|
||||||
group_name: str = None # 群名称
|
self,
|
||||||
|
message_id: str,
|
||||||
user_id: int = None
|
time: int,
|
||||||
user_nickname: str = None # 用户昵称
|
chat_stream: ChatStream,
|
||||||
user_cardname: str = None # 用户群昵称
|
user_info: UserInfo,
|
||||||
|
message_segment: Optional[Seg] = None,
|
||||||
raw_message: str = None # 原始消息,包含未解析的cq码
|
reply: Optional["MessageRecv"] = None,
|
||||||
plain_text: str = None # 纯文本
|
detailed_plain_text: str = "",
|
||||||
|
processed_plain_text: str = "",
|
||||||
reply_message: Dict = None # 存储 回复的 源消息
|
):
|
||||||
|
# 构造基础消息信息
|
||||||
# 延迟初始化字段
|
message_info = BaseMessageInfo(
|
||||||
_initialized: bool = False
|
platform=chat_stream.platform,
|
||||||
message_segments: List[Dict] = None # 存储解析后的消息片段
|
message_id=message_id,
|
||||||
processed_plain_text: str = None # 用于存储处理后的plain_text
|
time=time,
|
||||||
detailed_plain_text: str = None # 用于存储详细可读文本
|
group_info=chat_stream.group_info,
|
||||||
|
user_info=user_info,
|
||||||
# 状态标志
|
|
||||||
is_emoji: bool = False
|
|
||||||
has_emoji: bool = False
|
|
||||||
translate_cq: bool = True
|
|
||||||
|
|
||||||
async def initialize(self):
|
|
||||||
"""显式异步初始化方法(必须调用)"""
|
|
||||||
if self._initialized:
|
|
||||||
return
|
|
||||||
|
|
||||||
# 异步获取补充信息
|
|
||||||
self.group_name = self.group_name or get_groupname(self.group_id)
|
|
||||||
self.user_nickname = self.user_nickname or get_user_nickname(self.user_id)
|
|
||||||
self.user_cardname = self.user_cardname or get_user_cardname(self.user_id)
|
|
||||||
|
|
||||||
# 消息解析
|
|
||||||
if self.raw_message:
|
|
||||||
if not isinstance(self,Message_Sending):
|
|
||||||
self.message_segments = await self.parse_message_segments(self.raw_message)
|
|
||||||
self.processed_plain_text = ' '.join(
|
|
||||||
seg.translated_plain_text
|
|
||||||
for seg in self.message_segments
|
|
||||||
)
|
)
|
||||||
|
|
||||||
# 构建详细文本
|
# 调用父类初始化
|
||||||
if self.time is None:
|
super().__init__(message_info=message_info, message_segment=message_segment, raw_message=None)
|
||||||
self.time = int(time.time())
|
|
||||||
time_str = time.strftime("%m-%d %H:%M:%S", time.localtime(self.time))
|
self.chat_stream = chat_stream
|
||||||
name = (
|
# 文本处理相关属性
|
||||||
f"{self.user_nickname}(ta的昵称:{self.user_cardname},ta的id:{self.user_id})"
|
self.processed_plain_text = processed_plain_text
|
||||||
if self.user_cardname
|
self.detailed_plain_text = detailed_plain_text
|
||||||
else f"{self.user_nickname or f'用户{self.user_id}'}"
|
|
||||||
)
|
# 回复消息
|
||||||
if isinstance(self,Message_Sending) and self.is_emoji:
|
self.reply = reply
|
||||||
self.detailed_plain_text = f"[{time_str}] {name}: {self.detailed_plain_text}\n"
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class MessageRecv(Message):
|
||||||
|
"""接收消息类,用于处理从MessageCQ序列化的消息"""
|
||||||
|
|
||||||
|
def __init__(self, message_dict: Dict):
|
||||||
|
"""从MessageCQ的字典初始化
|
||||||
|
|
||||||
|
Args:
|
||||||
|
message_dict: MessageCQ序列化后的字典
|
||||||
|
"""
|
||||||
|
self.message_info = BaseMessageInfo.from_dict(message_dict.get("message_info", {}))
|
||||||
|
|
||||||
|
message_segment = message_dict.get("message_segment", {})
|
||||||
|
|
||||||
|
if message_segment.get("data", "") == "[json]":
|
||||||
|
# 提取json消息中的展示信息
|
||||||
|
pattern = r"\[CQ:json,data=(?P<json_data>.+?)\]"
|
||||||
|
match = re.search(pattern, message_dict.get("raw_message", ""))
|
||||||
|
raw_json = html.unescape(match.group("json_data"))
|
||||||
|
try:
|
||||||
|
json_message = json.loads(raw_json)
|
||||||
|
except json.JSONDecodeError:
|
||||||
|
json_message = {}
|
||||||
|
message_segment["data"] = json_message.get("prompt", "")
|
||||||
|
|
||||||
|
self.message_segment = Seg.from_dict(message_dict.get("message_segment", {}))
|
||||||
|
self.raw_message = message_dict.get("raw_message")
|
||||||
|
|
||||||
|
# 处理消息内容
|
||||||
|
self.processed_plain_text = "" # 初始化为空字符串
|
||||||
|
self.detailed_plain_text = "" # 初始化为空字符串
|
||||||
|
self.is_emoji = False
|
||||||
|
|
||||||
|
def update_chat_stream(self, chat_stream: ChatStream):
|
||||||
|
self.chat_stream = chat_stream
|
||||||
|
|
||||||
|
async def process(self) -> None:
|
||||||
|
"""处理消息内容,生成纯文本和详细文本
|
||||||
|
|
||||||
|
这个方法必须在创建实例后显式调用,因为它包含异步操作。
|
||||||
|
"""
|
||||||
|
self.processed_plain_text = await self._process_message_segments(self.message_segment)
|
||||||
|
self.detailed_plain_text = self._generate_detailed_text()
|
||||||
|
|
||||||
|
async def _process_message_segments(self, segment: Seg) -> str:
|
||||||
|
"""递归处理消息段,转换为文字描述
|
||||||
|
|
||||||
|
Args:
|
||||||
|
segment: 要处理的消息段
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
str: 处理后的文本
|
||||||
|
"""
|
||||||
|
if segment.type == "seglist":
|
||||||
|
# 处理消息段列表
|
||||||
|
segments_text = []
|
||||||
|
for seg in segment.data:
|
||||||
|
processed = await self._process_message_segments(seg)
|
||||||
|
if processed:
|
||||||
|
segments_text.append(processed)
|
||||||
|
return " ".join(segments_text)
|
||||||
else:
|
else:
|
||||||
self.detailed_plain_text = f"[{time_str}] {name}: {self.processed_plain_text}\n"
|
# 处理单个消息段
|
||||||
|
return await self._process_single_segment(segment)
|
||||||
|
|
||||||
self._initialized = True
|
async def _process_single_segment(self, seg: Seg) -> str:
|
||||||
|
"""处理单个消息段
|
||||||
|
|
||||||
async def parse_message_segments(self, message: str) -> List[CQCode]:
|
Args:
|
||||||
|
seg: 要处理的消息段
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
str: 处理后的文本
|
||||||
"""
|
"""
|
||||||
将消息解析为片段列表,包括纯文本和CQ码
|
try:
|
||||||
返回的列表中每个元素都是字典,包含:
|
if seg.type == "text":
|
||||||
- cq_code_list:分割出的聊天对象,包括文本和CQ码
|
return seg.data
|
||||||
- trans_list:翻译后的对象列表
|
elif seg.type == "image":
|
||||||
"""
|
# 如果是base64图片数据
|
||||||
# print(f"\033[1;34m[调试信息]\033[0m 正在处理消息: {message}")
|
if isinstance(seg.data, str):
|
||||||
cq_code_dict_list = []
|
return await image_manager.get_image_description(seg.data)
|
||||||
trans_list = []
|
return "[图片]"
|
||||||
|
elif seg.type == "emoji":
|
||||||
start = 0
|
|
||||||
while True:
|
|
||||||
# 查找下一个CQ码的开始位置
|
|
||||||
cq_start = message.find('[CQ:', start)
|
|
||||||
#如果没有cq码,直接返回文本内容
|
|
||||||
if cq_start == -1:
|
|
||||||
# 如果没有找到更多CQ码,添加剩余文本
|
|
||||||
if start < len(message):
|
|
||||||
text = message[start:].strip()
|
|
||||||
if text: # 只添加非空文本
|
|
||||||
cq_code_dict_list.append(parse_cq_code(text))
|
|
||||||
break
|
|
||||||
# 添加CQ码前的文本
|
|
||||||
if cq_start > start:
|
|
||||||
text = message[start:cq_start].strip()
|
|
||||||
if text: # 只添加非空文本
|
|
||||||
cq_code_dict_list.append(parse_cq_code(text))
|
|
||||||
# 查找CQ码的结束位置
|
|
||||||
cq_end = message.find(']', cq_start)
|
|
||||||
if cq_end == -1:
|
|
||||||
# CQ码未闭合,作为普通文本处理
|
|
||||||
text = message[cq_start:].strip()
|
|
||||||
if text:
|
|
||||||
cq_code_dict_list.append(parse_cq_code(text))
|
|
||||||
break
|
|
||||||
cq_code = message[cq_start:cq_end + 1]
|
|
||||||
|
|
||||||
#将cq_code解析成字典
|
|
||||||
cq_code_dict_list.append(parse_cq_code(cq_code))
|
|
||||||
# 更新start位置到当前CQ码之后
|
|
||||||
start = cq_end + 1
|
|
||||||
|
|
||||||
# print(f"\033[1;34m[调试信息]\033[0m 提取的消息对象:列表: {cq_code_dict_list}")
|
|
||||||
|
|
||||||
#判定是否是表情包消息,以及是否含有表情包
|
|
||||||
if len(cq_code_dict_list) == 1 and cq_code_dict_list[0]['type'] == 'image':
|
|
||||||
self.is_emoji = True
|
self.is_emoji = True
|
||||||
self.has_emoji_emoji = True
|
if isinstance(seg.data, str):
|
||||||
|
return await image_manager.get_emoji_description(seg.data)
|
||||||
|
return "[表情]"
|
||||||
else:
|
else:
|
||||||
for segment in cq_code_dict_list:
|
return f"[{seg.type}:{str(seg.data)}]"
|
||||||
if segment['type'] == 'image' and segment['data'].get('sub_type') == '1':
|
except Exception as e:
|
||||||
self.has_emoji_emoji = True
|
logger.error(f"处理消息段失败: {str(e)}, 类型: {seg.type}, 数据: {seg.data}")
|
||||||
break
|
return f"[处理失败的{seg.type}消息]"
|
||||||
|
|
||||||
|
def _generate_detailed_text(self) -> str:
|
||||||
|
"""生成详细文本,包含时间和用户信息"""
|
||||||
|
time_str = time.strftime("%m-%d %H:%M:%S", time.localtime(self.message_info.time))
|
||||||
|
user_info = self.message_info.user_info
|
||||||
|
name = (
|
||||||
|
f"{user_info.user_nickname}(ta的昵称:{user_info.user_cardname},ta的id:{user_info.user_id})"
|
||||||
|
if user_info.user_cardname != ""
|
||||||
|
else f"{user_info.user_nickname}(ta的id:{user_info.user_id})"
|
||||||
|
)
|
||||||
|
return f"[{time_str}] {name}: {self.processed_plain_text}\n"
|
||||||
|
|
||||||
|
|
||||||
#翻译作为字典的CQ码
|
@dataclass
|
||||||
for _code_item in cq_code_dict_list:
|
class MessageProcessBase(Message):
|
||||||
message_obj = await cq_code_tool.cq_from_dict_to_class(_code_item,reply = self.reply_message)
|
"""消息处理基类,用于处理中和发送中的消息"""
|
||||||
trans_list.append(message_obj)
|
|
||||||
return trans_list
|
|
||||||
|
|
||||||
class Message_Thinking:
|
def __init__(
|
||||||
"""消息思考类"""
|
self,
|
||||||
def __init__(self, message: Message,message_id: str):
|
message_id: str,
|
||||||
# 复制原始消息的基本属性
|
chat_stream: ChatStream,
|
||||||
self.group_id = message.group_id
|
bot_user_info: UserInfo,
|
||||||
self.user_id = message.user_id
|
message_segment: Optional[Seg] = None,
|
||||||
self.user_nickname = message.user_nickname
|
reply: Optional["MessageRecv"] = None,
|
||||||
self.user_cardname = message.user_cardname
|
):
|
||||||
self.group_name = message.group_name
|
# 调用父类初始化
|
||||||
|
super().__init__(
|
||||||
|
message_id=message_id,
|
||||||
|
time=int(time.time()),
|
||||||
|
chat_stream=chat_stream,
|
||||||
|
user_info=bot_user_info,
|
||||||
|
message_segment=message_segment,
|
||||||
|
reply=reply,
|
||||||
|
)
|
||||||
|
|
||||||
self.message_id = message_id
|
# 处理状态相关属性
|
||||||
|
|
||||||
# 思考状态相关属性
|
|
||||||
self.thinking_start_time = int(time.time())
|
self.thinking_start_time = int(time.time())
|
||||||
self.thinking_time = 0
|
self.thinking_time = 0
|
||||||
self.interupt=False
|
|
||||||
|
|
||||||
def update_thinking_time(self):
|
def update_thinking_time(self) -> float:
|
||||||
self.thinking_time = round(time.time(), 2) - self.thinking_start_time
|
"""更新思考时间"""
|
||||||
|
self.thinking_time = round(time.time() - self.thinking_start_time, 2)
|
||||||
|
return self.thinking_time
|
||||||
|
|
||||||
|
async def _process_message_segments(self, segment: Seg) -> str:
|
||||||
|
"""递归处理消息段,转换为文字描述
|
||||||
|
|
||||||
|
Args:
|
||||||
|
segment: 要处理的消息段
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
str: 处理后的文本
|
||||||
|
"""
|
||||||
|
if segment.type == "seglist":
|
||||||
|
# 处理消息段列表
|
||||||
|
segments_text = []
|
||||||
|
for seg in segment.data:
|
||||||
|
processed = await self._process_message_segments(seg)
|
||||||
|
if processed:
|
||||||
|
segments_text.append(processed)
|
||||||
|
return " ".join(segments_text)
|
||||||
|
else:
|
||||||
|
# 处理单个消息段
|
||||||
|
return await self._process_single_segment(segment)
|
||||||
|
|
||||||
|
async def _process_single_segment(self, seg: Seg) -> str:
|
||||||
|
"""处理单个消息段
|
||||||
|
|
||||||
|
Args:
|
||||||
|
seg: 要处理的消息段
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
str: 处理后的文本
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
if seg.type == "text":
|
||||||
|
return seg.data
|
||||||
|
elif seg.type == "image":
|
||||||
|
# 如果是base64图片数据
|
||||||
|
if isinstance(seg.data, str):
|
||||||
|
return await image_manager.get_image_description(seg.data)
|
||||||
|
return "[图片]"
|
||||||
|
elif seg.type == "emoji":
|
||||||
|
if isinstance(seg.data, str):
|
||||||
|
return await image_manager.get_emoji_description(seg.data)
|
||||||
|
return "[表情]"
|
||||||
|
elif seg.type == "at":
|
||||||
|
return f"[@{seg.data}]"
|
||||||
|
elif seg.type == "reply":
|
||||||
|
if self.reply and hasattr(self.reply, "processed_plain_text"):
|
||||||
|
return f"[回复:{self.reply.processed_plain_text}]"
|
||||||
|
else:
|
||||||
|
return f"[{seg.type}:{str(seg.data)}]"
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"处理消息段失败: {str(e)}, 类型: {seg.type}, 数据: {seg.data}")
|
||||||
|
return f"[处理失败的{seg.type}消息]"
|
||||||
|
|
||||||
|
def _generate_detailed_text(self) -> str:
|
||||||
|
"""生成详细文本,包含时间和用户信息"""
|
||||||
|
time_str = time.strftime("%m-%d %H:%M:%S", time.localtime(self.message_info.time))
|
||||||
|
user_info = self.message_info.user_info
|
||||||
|
name = (
|
||||||
|
f"{user_info.user_nickname}(ta的昵称:{user_info.user_cardname},ta的id:{user_info.user_id})"
|
||||||
|
if user_info.user_cardname != ""
|
||||||
|
else f"{user_info.user_nickname}(ta的id:{user_info.user_id})"
|
||||||
|
)
|
||||||
|
return f"[{time_str}] {name}: {self.processed_plain_text}\n"
|
||||||
|
|
||||||
|
|
||||||
@dataclass
|
@dataclass
|
||||||
class Message_Sending(Message):
|
class MessageThinking(MessageProcessBase):
|
||||||
"""发送中的消息类"""
|
"""思考状态的消息类"""
|
||||||
thinking_start_time: float = None # 思考开始时间
|
|
||||||
thinking_time: float = None # 思考时间
|
|
||||||
|
|
||||||
reply_message_id: int = None # 存储 回复的 源消息ID
|
def __init__(
|
||||||
|
self,
|
||||||
|
message_id: str,
|
||||||
|
chat_stream: ChatStream,
|
||||||
|
bot_user_info: UserInfo,
|
||||||
|
reply: Optional["MessageRecv"] = None,
|
||||||
|
):
|
||||||
|
# 调用父类初始化
|
||||||
|
super().__init__(
|
||||||
|
message_id=message_id,
|
||||||
|
chat_stream=chat_stream,
|
||||||
|
bot_user_info=bot_user_info,
|
||||||
|
message_segment=None, # 思考状态不需要消息段
|
||||||
|
reply=reply,
|
||||||
|
)
|
||||||
|
|
||||||
is_head: bool = False # 是否是头部消息
|
# 思考状态特有属性
|
||||||
|
self.interrupt = False
|
||||||
def update_thinking_time(self):
|
|
||||||
self.thinking_time = round(time.time(), 2) - self.thinking_start_time
|
|
||||||
return self.thinking_time
|
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class MessageSending(MessageProcessBase):
|
||||||
|
"""发送状态的消息类"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
message_id: str,
|
||||||
|
chat_stream: ChatStream,
|
||||||
|
bot_user_info: UserInfo,
|
||||||
|
sender_info: UserInfo, # 用来记录发送者信息,用于私聊回复
|
||||||
|
message_segment: Seg,
|
||||||
|
reply: Optional["MessageRecv"] = None,
|
||||||
|
is_head: bool = False,
|
||||||
|
is_emoji: bool = False,
|
||||||
|
):
|
||||||
|
# 调用父类初始化
|
||||||
|
super().__init__(
|
||||||
|
message_id=message_id,
|
||||||
|
chat_stream=chat_stream,
|
||||||
|
bot_user_info=bot_user_info,
|
||||||
|
message_segment=message_segment,
|
||||||
|
reply=reply,
|
||||||
|
)
|
||||||
|
|
||||||
|
# 发送状态特有属性
|
||||||
|
self.sender_info = sender_info
|
||||||
|
self.reply_to_message_id = reply.message_info.message_id if reply else None
|
||||||
|
self.is_head = is_head
|
||||||
|
self.is_emoji = is_emoji
|
||||||
|
|
||||||
|
def set_reply(self, reply: Optional["MessageRecv"] = None) -> None:
|
||||||
|
"""设置回复消息"""
|
||||||
|
if reply:
|
||||||
|
self.reply = reply
|
||||||
|
if self.reply:
|
||||||
|
self.reply_to_message_id = self.reply.message_info.message_id
|
||||||
|
self.message_segment = Seg(
|
||||||
|
type="seglist",
|
||||||
|
data=[
|
||||||
|
Seg(type="reply", data=reply.message_info.message_id),
|
||||||
|
self.message_segment,
|
||||||
|
],
|
||||||
|
)
|
||||||
|
|
||||||
|
async def process(self) -> None:
|
||||||
|
"""处理消息内容,生成纯文本和详细文本"""
|
||||||
|
if self.message_segment:
|
||||||
|
self.processed_plain_text = await self._process_message_segments(self.message_segment)
|
||||||
|
self.detailed_plain_text = self._generate_detailed_text()
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def from_thinking(
|
||||||
|
cls,
|
||||||
|
thinking: MessageThinking,
|
||||||
|
message_segment: Seg,
|
||||||
|
is_head: bool = False,
|
||||||
|
is_emoji: bool = False,
|
||||||
|
) -> "MessageSending":
|
||||||
|
"""从思考状态消息创建发送状态消息"""
|
||||||
|
return cls(
|
||||||
|
message_id=thinking.message_info.message_id,
|
||||||
|
chat_stream=thinking.chat_stream,
|
||||||
|
message_segment=message_segment,
|
||||||
|
bot_user_info=thinking.message_info.user_info,
|
||||||
|
reply=thinking.reply,
|
||||||
|
is_head=is_head,
|
||||||
|
is_emoji=is_emoji,
|
||||||
|
)
|
||||||
|
|
||||||
|
def to_dict(self):
|
||||||
|
ret = super().to_dict()
|
||||||
|
ret["message_info"]["user_info"] = self.chat_stream.user_info.to_dict()
|
||||||
|
return ret
|
||||||
|
|
||||||
|
def is_private_message(self) -> bool:
|
||||||
|
"""判断是否为私聊消息"""
|
||||||
|
return self.message_info.group_info is None or self.message_info.group_info.group_id is None
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
class MessageSet:
|
class MessageSet:
|
||||||
"""消息集合类,可以存储多个发送消息"""
|
"""消息集合类,可以存储多个发送消息"""
|
||||||
def __init__(self, group_id: int, user_id: int, message_id: str):
|
|
||||||
self.group_id = group_id
|
def __init__(self, chat_stream: ChatStream, message_id: str):
|
||||||
self.user_id = user_id
|
self.chat_stream = chat_stream
|
||||||
self.message_id = message_id
|
self.message_id = message_id
|
||||||
self.messages: List[Message_Sending] = [] # 修改类型标注
|
self.messages: List[MessageSending] = []
|
||||||
self.time = round(time.time(), 2)
|
self.time = round(time.time(), 2)
|
||||||
|
|
||||||
def add_message(self, message: Message_Sending) -> None:
|
def add_message(self, message: MessageSending) -> None:
|
||||||
"""添加消息到集合,只接受Message_Sending类型"""
|
"""添加消息到集合"""
|
||||||
if not isinstance(message, Message_Sending):
|
if not isinstance(message, MessageSending):
|
||||||
raise TypeError("MessageSet只能添加Message_Sending类型的消息")
|
raise TypeError("MessageSet只能添加MessageSending类型的消息")
|
||||||
self.messages.append(message)
|
self.messages.append(message)
|
||||||
# 按时间排序
|
self.messages.sort(key=lambda x: x.message_info.time)
|
||||||
self.messages.sort(key=lambda x: x.time)
|
|
||||||
|
|
||||||
def get_message_by_index(self, index: int) -> Optional[Message_Sending]:
|
def get_message_by_index(self, index: int) -> Optional[MessageSending]:
|
||||||
"""通过索引获取消息"""
|
"""通过索引获取消息"""
|
||||||
if 0 <= index < len(self.messages):
|
if 0 <= index < len(self.messages):
|
||||||
return self.messages[index]
|
return self.messages[index]
|
||||||
return None
|
return None
|
||||||
|
|
||||||
def get_message_by_time(self, target_time: float) -> Optional[Message_Sending]:
|
def get_message_by_time(self, target_time: float) -> Optional[MessageSending]:
|
||||||
"""获取最接近指定时间的消息"""
|
"""获取最接近指定时间的消息"""
|
||||||
if not self.messages:
|
if not self.messages:
|
||||||
return None
|
return None
|
||||||
|
|
||||||
# 使用二分查找找到最接近的消息
|
|
||||||
left, right = 0, len(self.messages) - 1
|
left, right = 0, len(self.messages) - 1
|
||||||
while left < right:
|
while left < right:
|
||||||
mid = (left + right) // 2
|
mid = (left + right) // 2
|
||||||
if self.messages[mid].time < target_time:
|
if self.messages[mid].message_info.time < target_time:
|
||||||
left = mid + 1
|
left = mid + 1
|
||||||
else:
|
else:
|
||||||
right = mid
|
right = mid
|
||||||
|
|
||||||
return self.messages[left]
|
return self.messages[left]
|
||||||
|
|
||||||
|
|
||||||
def clear_messages(self) -> None:
|
def clear_messages(self) -> None:
|
||||||
"""清空所有消息"""
|
"""清空所有消息"""
|
||||||
self.messages.clear()
|
self.messages.clear()
|
||||||
|
|
||||||
def remove_message(self, message: Message_Sending) -> bool:
|
def remove_message(self, message: MessageSending) -> bool:
|
||||||
"""移除指定消息"""
|
"""移除指定消息"""
|
||||||
if message in self.messages:
|
if message in self.messages:
|
||||||
self.messages.remove(message)
|
self.messages.remove(message)
|
||||||
@@ -237,6 +418,3 @@ class MessageSet:
|
|||||||
|
|
||||||
def __len__(self) -> int:
|
def __len__(self) -> int:
|
||||||
return len(self.messages)
|
return len(self.messages)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
188
src/plugins/chat/message_base.py
Normal file
@@ -0,0 +1,188 @@
|
|||||||
|
from dataclasses import dataclass, asdict
|
||||||
|
from typing import List, Optional, Union, Dict
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class Seg:
|
||||||
|
"""消息片段类,用于表示消息的不同部分
|
||||||
|
|
||||||
|
Attributes:
|
||||||
|
type: 片段类型,可以是 'text'、'image'、'seglist' 等
|
||||||
|
data: 片段的具体内容
|
||||||
|
- 对于 text 类型,data 是字符串
|
||||||
|
- 对于 image 类型,data 是 base64 字符串
|
||||||
|
- 对于 seglist 类型,data 是 Seg 列表
|
||||||
|
translated_data: 经过翻译处理的数据(可选)
|
||||||
|
"""
|
||||||
|
type: str
|
||||||
|
data: Union[str, List['Seg']]
|
||||||
|
|
||||||
|
|
||||||
|
# def __init__(self, type: str, data: Union[str, List['Seg']],):
|
||||||
|
# """初始化实例,确保字典和属性同步"""
|
||||||
|
# # 先初始化字典
|
||||||
|
# self.type = type
|
||||||
|
# self.data = data
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def from_dict(cls, data: Dict) -> 'Seg':
|
||||||
|
"""从字典创建Seg实例"""
|
||||||
|
type=data.get('type')
|
||||||
|
data=data.get('data')
|
||||||
|
if type == 'seglist':
|
||||||
|
data = [Seg.from_dict(seg) for seg in data]
|
||||||
|
return cls(
|
||||||
|
type=type,
|
||||||
|
data=data
|
||||||
|
)
|
||||||
|
|
||||||
|
def to_dict(self) -> Dict:
|
||||||
|
"""转换为字典格式"""
|
||||||
|
result = {'type': self.type}
|
||||||
|
if self.type == 'seglist':
|
||||||
|
result['data'] = [seg.to_dict() for seg in self.data]
|
||||||
|
else:
|
||||||
|
result['data'] = self.data
|
||||||
|
return result
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class GroupInfo:
|
||||||
|
"""群组信息类"""
|
||||||
|
platform: Optional[str] = None
|
||||||
|
group_id: Optional[int] = None
|
||||||
|
group_name: Optional[str] = None # 群名称
|
||||||
|
|
||||||
|
def to_dict(self) -> Dict:
|
||||||
|
"""转换为字典格式"""
|
||||||
|
return {k: v for k, v in asdict(self).items() if v is not None}
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def from_dict(cls, data: Dict) -> 'GroupInfo':
|
||||||
|
"""从字典创建GroupInfo实例
|
||||||
|
|
||||||
|
Args:
|
||||||
|
data: 包含必要字段的字典
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
GroupInfo: 新的实例
|
||||||
|
"""
|
||||||
|
if data.get('group_id') is None:
|
||||||
|
return None
|
||||||
|
return cls(
|
||||||
|
platform=data.get('platform'),
|
||||||
|
group_id=data.get('group_id'),
|
||||||
|
group_name=data.get('group_name',None)
|
||||||
|
)
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class UserInfo:
|
||||||
|
"""用户信息类"""
|
||||||
|
platform: Optional[str] = None
|
||||||
|
user_id: Optional[int] = None
|
||||||
|
user_nickname: Optional[str] = None # 用户昵称
|
||||||
|
user_cardname: Optional[str] = None # 用户群昵称
|
||||||
|
|
||||||
|
def to_dict(self) -> Dict:
|
||||||
|
"""转换为字典格式"""
|
||||||
|
return {k: v for k, v in asdict(self).items() if v is not None}
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def from_dict(cls, data: Dict) -> 'UserInfo':
|
||||||
|
"""从字典创建UserInfo实例
|
||||||
|
|
||||||
|
Args:
|
||||||
|
data: 包含必要字段的字典
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
UserInfo: 新的实例
|
||||||
|
"""
|
||||||
|
return cls(
|
||||||
|
platform=data.get('platform'),
|
||||||
|
user_id=data.get('user_id'),
|
||||||
|
user_nickname=data.get('user_nickname',None),
|
||||||
|
user_cardname=data.get('user_cardname',None)
|
||||||
|
)
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class BaseMessageInfo:
|
||||||
|
"""消息信息类"""
|
||||||
|
platform: Optional[str] = None
|
||||||
|
message_id: Union[str,int,None] = None
|
||||||
|
time: Optional[int] = None
|
||||||
|
group_info: Optional[GroupInfo] = None
|
||||||
|
user_info: Optional[UserInfo] = None
|
||||||
|
|
||||||
|
def to_dict(self) -> Dict:
|
||||||
|
"""转换为字典格式"""
|
||||||
|
result = {}
|
||||||
|
for field, value in asdict(self).items():
|
||||||
|
if value is not None:
|
||||||
|
if isinstance(value, (GroupInfo, UserInfo)):
|
||||||
|
result[field] = value.to_dict()
|
||||||
|
else:
|
||||||
|
result[field] = value
|
||||||
|
return result
|
||||||
|
@classmethod
|
||||||
|
def from_dict(cls, data: Dict) -> 'BaseMessageInfo':
|
||||||
|
"""从字典创建BaseMessageInfo实例
|
||||||
|
|
||||||
|
Args:
|
||||||
|
data: 包含必要字段的字典
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
BaseMessageInfo: 新的实例
|
||||||
|
"""
|
||||||
|
group_info = GroupInfo.from_dict(data.get('group_info', {}))
|
||||||
|
user_info = UserInfo.from_dict(data.get('user_info', {}))
|
||||||
|
return cls(
|
||||||
|
platform=data.get('platform'),
|
||||||
|
message_id=data.get('message_id'),
|
||||||
|
time=data.get('time'),
|
||||||
|
group_info=group_info,
|
||||||
|
user_info=user_info
|
||||||
|
)
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class MessageBase:
|
||||||
|
"""消息类"""
|
||||||
|
message_info: BaseMessageInfo
|
||||||
|
message_segment: Seg
|
||||||
|
raw_message: Optional[str] = None # 原始消息,包含未解析的cq码
|
||||||
|
|
||||||
|
def to_dict(self) -> Dict:
|
||||||
|
"""转换为字典格式
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Dict: 包含所有非None字段的字典,其中:
|
||||||
|
- message_info: 转换为字典格式
|
||||||
|
- message_segment: 转换为字典格式
|
||||||
|
- raw_message: 如果存在则包含
|
||||||
|
"""
|
||||||
|
result = {
|
||||||
|
'message_info': self.message_info.to_dict(),
|
||||||
|
'message_segment': self.message_segment.to_dict()
|
||||||
|
}
|
||||||
|
if self.raw_message is not None:
|
||||||
|
result['raw_message'] = self.raw_message
|
||||||
|
return result
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def from_dict(cls, data: Dict) -> 'MessageBase':
|
||||||
|
"""从字典创建MessageBase实例
|
||||||
|
|
||||||
|
Args:
|
||||||
|
data: 包含必要字段的字典
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
MessageBase: 新的实例
|
||||||
|
"""
|
||||||
|
message_info = BaseMessageInfo.from_dict(data.get('message_info', {}))
|
||||||
|
message_segment = Seg(**data.get('message_segment', {}))
|
||||||
|
raw_message = data.get('raw_message',None)
|
||||||
|
return cls(
|
||||||
|
message_info=message_info,
|
||||||
|
message_segment=message_segment,
|
||||||
|
raw_message=raw_message
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
164
src/plugins/chat/message_cq.py
Normal file
@@ -0,0 +1,164 @@
|
|||||||
|
import time
|
||||||
|
from dataclasses import dataclass
|
||||||
|
from typing import Dict, Optional
|
||||||
|
|
||||||
|
import urllib3
|
||||||
|
|
||||||
|
from .cq_code import cq_code_tool
|
||||||
|
from .utils_cq import parse_cq_code
|
||||||
|
from .utils_user import get_groupname
|
||||||
|
from .message_base import Seg, GroupInfo, UserInfo, BaseMessageInfo, MessageBase
|
||||||
|
|
||||||
|
# 禁用SSL警告
|
||||||
|
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
|
||||||
|
|
||||||
|
# 这个类是消息数据类,用于存储和管理消息数据。
|
||||||
|
# 它定义了消息的属性,包括群组ID、用户ID、消息ID、原始消息内容、纯文本内容和时间戳。
|
||||||
|
# 它还定义了两个辅助属性:keywords用于提取消息的关键词,is_plain_text用于判断消息是否为纯文本。
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class MessageCQ(MessageBase):
|
||||||
|
"""QQ消息基类,继承自MessageBase
|
||||||
|
|
||||||
|
最小必要参数:
|
||||||
|
- message_id: 消息ID
|
||||||
|
- user_id: 发送者/接收者ID
|
||||||
|
- platform: 平台标识(默认为"qq")
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, message_id: int, user_info: UserInfo, group_info: Optional[GroupInfo] = None, platform: str = "qq"
|
||||||
|
):
|
||||||
|
# 构造基础消息信息
|
||||||
|
message_info = BaseMessageInfo(
|
||||||
|
platform=platform, message_id=message_id, time=int(time.time()), group_info=group_info, user_info=user_info
|
||||||
|
)
|
||||||
|
# 调用父类初始化,message_segment 由子类设置
|
||||||
|
super().__init__(message_info=message_info, message_segment=None, raw_message=None)
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class MessageRecvCQ(MessageCQ):
|
||||||
|
"""QQ接收消息类,用于解析raw_message到Seg对象"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
message_id: int,
|
||||||
|
user_info: UserInfo,
|
||||||
|
raw_message: str,
|
||||||
|
group_info: Optional[GroupInfo] = None,
|
||||||
|
platform: str = "qq",
|
||||||
|
reply_message: Optional[Dict] = None,
|
||||||
|
):
|
||||||
|
# 调用父类初始化
|
||||||
|
super().__init__(message_id, user_info, group_info, platform)
|
||||||
|
|
||||||
|
# 私聊消息不携带group_info
|
||||||
|
if group_info is None:
|
||||||
|
pass
|
||||||
|
|
||||||
|
elif group_info.group_name is None:
|
||||||
|
group_info.group_name = get_groupname(group_info.group_id)
|
||||||
|
|
||||||
|
# 解析消息段
|
||||||
|
self.message_segment = self._parse_message(raw_message, reply_message)
|
||||||
|
self.raw_message = raw_message
|
||||||
|
|
||||||
|
def _parse_message(self, message: str, reply_message: Optional[Dict] = None) -> Seg:
|
||||||
|
"""解析消息内容为Seg对象"""
|
||||||
|
cq_code_dict_list = []
|
||||||
|
segments = []
|
||||||
|
|
||||||
|
start = 0
|
||||||
|
while True:
|
||||||
|
cq_start = message.find("[CQ:", start)
|
||||||
|
if cq_start == -1:
|
||||||
|
if start < len(message):
|
||||||
|
text = message[start:].strip()
|
||||||
|
if text:
|
||||||
|
cq_code_dict_list.append(parse_cq_code(text))
|
||||||
|
break
|
||||||
|
|
||||||
|
if cq_start > start:
|
||||||
|
text = message[start:cq_start].strip()
|
||||||
|
if text:
|
||||||
|
cq_code_dict_list.append(parse_cq_code(text))
|
||||||
|
|
||||||
|
cq_end = message.find("]", cq_start)
|
||||||
|
if cq_end == -1:
|
||||||
|
text = message[cq_start:].strip()
|
||||||
|
if text:
|
||||||
|
cq_code_dict_list.append(parse_cq_code(text))
|
||||||
|
break
|
||||||
|
|
||||||
|
cq_code = message[cq_start : cq_end + 1]
|
||||||
|
cq_code_dict_list.append(parse_cq_code(cq_code))
|
||||||
|
start = cq_end + 1
|
||||||
|
|
||||||
|
# 转换CQ码为Seg对象
|
||||||
|
for code_item in cq_code_dict_list:
|
||||||
|
message_obj = cq_code_tool.cq_from_dict_to_class(code_item, msg=self, reply=reply_message)
|
||||||
|
if message_obj.translated_segments:
|
||||||
|
segments.append(message_obj.translated_segments)
|
||||||
|
|
||||||
|
# 如果只有一个segment,直接返回
|
||||||
|
if len(segments) == 1:
|
||||||
|
return segments[0]
|
||||||
|
|
||||||
|
# 否则返回seglist类型的Seg
|
||||||
|
return Seg(type="seglist", data=segments)
|
||||||
|
|
||||||
|
def to_dict(self) -> Dict:
|
||||||
|
"""转换为字典格式,包含所有必要信息"""
|
||||||
|
base_dict = super().to_dict()
|
||||||
|
return base_dict
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class MessageSendCQ(MessageCQ):
|
||||||
|
"""QQ发送消息类,用于将Seg对象转换为raw_message"""
|
||||||
|
|
||||||
|
def __init__(self, data: Dict):
|
||||||
|
# 调用父类初始化
|
||||||
|
message_info = BaseMessageInfo.from_dict(data.get("message_info", {}))
|
||||||
|
message_segment = Seg.from_dict(data.get("message_segment", {}))
|
||||||
|
super().__init__(
|
||||||
|
message_info.message_id,
|
||||||
|
message_info.user_info,
|
||||||
|
message_info.group_info if message_info.group_info else None,
|
||||||
|
message_info.platform,
|
||||||
|
)
|
||||||
|
|
||||||
|
self.message_segment = message_segment
|
||||||
|
self.raw_message = self._generate_raw_message()
|
||||||
|
|
||||||
|
def _generate_raw_message(
|
||||||
|
self,
|
||||||
|
) -> str:
|
||||||
|
"""将Seg对象转换为raw_message"""
|
||||||
|
segments = []
|
||||||
|
|
||||||
|
# 处理消息段
|
||||||
|
if self.message_segment.type == "seglist":
|
||||||
|
for seg in self.message_segment.data:
|
||||||
|
segments.append(self._seg_to_cq_code(seg))
|
||||||
|
else:
|
||||||
|
segments.append(self._seg_to_cq_code(self.message_segment))
|
||||||
|
|
||||||
|
return "".join(segments)
|
||||||
|
|
||||||
|
def _seg_to_cq_code(self, seg: Seg) -> str:
|
||||||
|
"""将单个Seg对象转换为CQ码字符串"""
|
||||||
|
if seg.type == "text":
|
||||||
|
return str(seg.data)
|
||||||
|
elif seg.type == "image":
|
||||||
|
return cq_code_tool.create_image_cq_base64(seg.data)
|
||||||
|
elif seg.type == "emoji":
|
||||||
|
return cq_code_tool.create_emoji_cq_base64(seg.data)
|
||||||
|
elif seg.type == "at":
|
||||||
|
return f"[CQ:at,qq={seg.data}]"
|
||||||
|
elif seg.type == "reply":
|
||||||
|
return cq_code_tool.create_reply_cq(int(seg.data))
|
||||||
|
else:
|
||||||
|
return f"[{seg.data}]"
|
||||||
@@ -2,17 +2,20 @@ import asyncio
|
|||||||
import time
|
import time
|
||||||
from typing import Dict, List, Optional, Union
|
from typing import Dict, List, Optional, Union
|
||||||
|
|
||||||
|
from loguru import logger
|
||||||
from nonebot.adapters.onebot.v11 import Bot
|
from nonebot.adapters.onebot.v11 import Bot
|
||||||
|
|
||||||
from .cq_code import cq_code_tool
|
from .message_cq import MessageSendCQ
|
||||||
from .message import Message, Message_Sending, Message_Thinking, MessageSet
|
from .message import MessageSending, MessageThinking, MessageRecv, MessageSet
|
||||||
|
|
||||||
from .storage import MessageStorage
|
from .storage import MessageStorage
|
||||||
from .utils import calculate_typing_time
|
|
||||||
from .config import global_config
|
from .config import global_config
|
||||||
|
from .utils import truncate_message
|
||||||
|
|
||||||
|
|
||||||
class Message_Sender:
|
class Message_Sender:
|
||||||
"""发送器"""
|
"""发送器"""
|
||||||
|
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.message_interval = (0.5, 1) # 消息间隔时间范围(秒)
|
self.message_interval = (0.5, 1) # 消息间隔时间范围(秒)
|
||||||
self.last_send_time = 0
|
self.last_send_time = 0
|
||||||
@@ -22,65 +25,62 @@ class Message_Sender:
|
|||||||
"""设置当前bot实例"""
|
"""设置当前bot实例"""
|
||||||
self._current_bot = bot
|
self._current_bot = bot
|
||||||
|
|
||||||
async def send_group_message(
|
async def send_message(
|
||||||
self,
|
self,
|
||||||
group_id: int,
|
message: MessageSending,
|
||||||
send_text: str,
|
|
||||||
auto_escape: bool = False,
|
|
||||||
reply_message_id: int = None,
|
|
||||||
at_user_id: int = None
|
|
||||||
) -> None:
|
) -> None:
|
||||||
|
"""发送消息"""
|
||||||
|
|
||||||
if not self._current_bot:
|
if isinstance(message, MessageSending):
|
||||||
raise RuntimeError("Bot未设置,请先调用set_bot方法设置bot实例")
|
message_json = message.to_dict()
|
||||||
|
message_send = MessageSendCQ(data=message_json)
|
||||||
message = send_text
|
# logger.debug(message_send.message_info,message_send.raw_message)
|
||||||
|
message_preview = truncate_message(message.processed_plain_text)
|
||||||
# 如果需要回复
|
if (
|
||||||
if reply_message_id:
|
message_send.message_info.group_info
|
||||||
reply_cq = cq_code_tool.create_reply_cq(reply_message_id)
|
and message_send.message_info.group_info.group_id
|
||||||
message = reply_cq + message
|
):
|
||||||
|
|
||||||
# 如果需要at
|
|
||||||
# if at_user_id:
|
|
||||||
# at_cq = cq_code_tool.create_at_cq(at_user_id)
|
|
||||||
# message = at_cq + " " + message
|
|
||||||
|
|
||||||
|
|
||||||
typing_time = calculate_typing_time(message)
|
|
||||||
if typing_time > 10:
|
|
||||||
typing_time = 10
|
|
||||||
await asyncio.sleep(typing_time)
|
|
||||||
|
|
||||||
# 发送消息
|
|
||||||
try:
|
try:
|
||||||
await self._current_bot.send_group_msg(
|
await self._current_bot.send_group_msg(
|
||||||
group_id=group_id,
|
group_id=message.message_info.group_info.group_id,
|
||||||
message=message,
|
message=message_send.raw_message,
|
||||||
auto_escape=auto_escape
|
auto_escape=False,
|
||||||
)
|
)
|
||||||
print(f"\033[1;34m[调试]\033[0m 发送消息{message}成功")
|
logger.success(f"[调试] 发送消息“{message_preview}”成功")
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(f"发生错误 {e}")
|
logger.error(f"[调试] 发生错误 {e}")
|
||||||
print(f"\033[1;34m[调试]\033[0m 发送消息{message}失败")
|
logger.error(f"[调试] 发送消息“{message_preview}”失败")
|
||||||
|
else:
|
||||||
|
try:
|
||||||
|
logger.debug(message.message_info.user_info)
|
||||||
|
await self._current_bot.send_private_msg(
|
||||||
|
user_id=message.sender_info.user_id,
|
||||||
|
message=message_send.raw_message,
|
||||||
|
auto_escape=False,
|
||||||
|
)
|
||||||
|
logger.success(f"[调试] 发送消息“{message_preview}”成功")
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"[调试] 发生错误 {e}")
|
||||||
|
logger.error(f"[调试] 发送消息“{message_preview}”失败")
|
||||||
|
|
||||||
|
|
||||||
class MessageContainer:
|
class MessageContainer:
|
||||||
"""单个群的发送/思考消息容器"""
|
"""单个聊天流的发送/思考消息容器"""
|
||||||
def __init__(self, group_id: int, max_size: int = 100):
|
|
||||||
self.group_id = group_id
|
def __init__(self, chat_id: str, max_size: int = 100):
|
||||||
|
self.chat_id = chat_id
|
||||||
self.max_size = max_size
|
self.max_size = max_size
|
||||||
self.messages = []
|
self.messages = []
|
||||||
self.last_send_time = 0
|
self.last_send_time = 0
|
||||||
self.thinking_timeout = 20 # 思考超时时间(秒)
|
self.thinking_timeout = 20 # 思考超时时间(秒)
|
||||||
|
|
||||||
def get_timeout_messages(self) -> List[Message_Sending]:
|
def get_timeout_messages(self) -> List[MessageSending]:
|
||||||
"""获取所有超时的Message_Sending对象(思考时间超过30秒),按thinking_start_time排序"""
|
"""获取所有超时的Message_Sending对象(思考时间超过30秒),按thinking_start_time排序"""
|
||||||
current_time = time.time()
|
current_time = time.time()
|
||||||
timeout_messages = []
|
timeout_messages = []
|
||||||
|
|
||||||
for msg in self.messages:
|
for msg in self.messages:
|
||||||
if isinstance(msg, Message_Sending):
|
if isinstance(msg, MessageSending):
|
||||||
if current_time - msg.thinking_start_time > self.thinking_timeout:
|
if current_time - msg.thinking_start_time > self.thinking_timeout:
|
||||||
timeout_messages.append(msg)
|
timeout_messages.append(msg)
|
||||||
|
|
||||||
@@ -89,11 +89,11 @@ class MessageContainer:
|
|||||||
|
|
||||||
return timeout_messages
|
return timeout_messages
|
||||||
|
|
||||||
def get_earliest_message(self) -> Optional[Union[Message_Thinking, Message_Sending]]:
|
def get_earliest_message(self) -> Optional[Union[MessageThinking, MessageSending]]:
|
||||||
"""获取thinking_start_time最早的消息对象"""
|
"""获取thinking_start_time最早的消息对象"""
|
||||||
if not self.messages:
|
if not self.messages:
|
||||||
return None
|
return None
|
||||||
earliest_time = float('inf')
|
earliest_time = float("inf")
|
||||||
earliest_message = None
|
earliest_message = None
|
||||||
for msg in self.messages:
|
for msg in self.messages:
|
||||||
msg_time = msg.thinking_start_time
|
msg_time = msg.thinking_start_time
|
||||||
@@ -102,112 +102,125 @@ class MessageContainer:
|
|||||||
earliest_message = msg
|
earliest_message = msg
|
||||||
return earliest_message
|
return earliest_message
|
||||||
|
|
||||||
def add_message(self, message: Union[Message_Thinking, Message_Sending]) -> None:
|
def add_message(self, message: Union[MessageThinking, MessageSending]) -> None:
|
||||||
"""添加消息到队列"""
|
"""添加消息到队列"""
|
||||||
# print(f"\033[1;32m[添加消息]\033[0m 添加消息到对应群")
|
|
||||||
if isinstance(message, MessageSet):
|
if isinstance(message, MessageSet):
|
||||||
for single_message in message.messages:
|
for single_message in message.messages:
|
||||||
self.messages.append(single_message)
|
self.messages.append(single_message)
|
||||||
else:
|
else:
|
||||||
self.messages.append(message)
|
self.messages.append(message)
|
||||||
|
|
||||||
def remove_message(self, message: Union[Message_Thinking, Message_Sending]) -> bool:
|
def remove_message(self, message: Union[MessageThinking, MessageSending]) -> bool:
|
||||||
"""移除消息,如果消息存在则返回True,否则返回False"""
|
"""移除消息,如果消息存在则返回True,否则返回False"""
|
||||||
try:
|
try:
|
||||||
if message in self.messages:
|
if message in self.messages:
|
||||||
self.messages.remove(message)
|
self.messages.remove(message)
|
||||||
return True
|
return True
|
||||||
return False
|
return False
|
||||||
except Exception as e:
|
except Exception:
|
||||||
print(f"\033[1;31m[错误]\033[0m 移除消息时发生错误: {e}")
|
logger.exception("移除消息时发生错误")
|
||||||
return False
|
return False
|
||||||
|
|
||||||
def has_messages(self) -> bool:
|
def has_messages(self) -> bool:
|
||||||
"""检查是否有待发送的消息"""
|
"""检查是否有待发送的消息"""
|
||||||
return bool(self.messages)
|
return bool(self.messages)
|
||||||
|
|
||||||
def get_all_messages(self) -> List[Union[Message, Message_Thinking]]:
|
def get_all_messages(self) -> List[Union[MessageSending, MessageThinking]]:
|
||||||
"""获取所有消息"""
|
"""获取所有消息"""
|
||||||
return list(self.messages)
|
return list(self.messages)
|
||||||
|
|
||||||
|
|
||||||
class MessageManager:
|
class MessageManager:
|
||||||
"""管理所有群的消息容器"""
|
"""管理所有聊天流的消息容器"""
|
||||||
|
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.containers: Dict[int, MessageContainer] = {}
|
self.containers: Dict[str, MessageContainer] = {} # chat_id -> MessageContainer
|
||||||
self.storage = MessageStorage()
|
self.storage = MessageStorage()
|
||||||
self._running = True
|
self._running = True
|
||||||
|
|
||||||
def get_container(self, group_id: int) -> MessageContainer:
|
def get_container(self, chat_id: str) -> MessageContainer:
|
||||||
"""获取或创建群的消息容器"""
|
"""获取或创建聊天流的消息容器"""
|
||||||
if group_id not in self.containers:
|
if chat_id not in self.containers:
|
||||||
self.containers[group_id] = MessageContainer(group_id)
|
self.containers[chat_id] = MessageContainer(chat_id)
|
||||||
return self.containers[group_id]
|
return self.containers[chat_id]
|
||||||
|
|
||||||
def add_message(self, message: Union[Message_Thinking, Message_Sending, MessageSet]) -> None:
|
def add_message(
|
||||||
container = self.get_container(message.group_id)
|
self, message: Union[MessageThinking, MessageSending, MessageSet]
|
||||||
|
) -> None:
|
||||||
|
chat_stream = message.chat_stream
|
||||||
|
if not chat_stream:
|
||||||
|
raise ValueError("无法找到对应的聊天流")
|
||||||
|
container = self.get_container(chat_stream.stream_id)
|
||||||
container.add_message(message)
|
container.add_message(message)
|
||||||
|
|
||||||
async def process_group_messages(self, group_id: int):
|
async def process_chat_messages(self, chat_id: str):
|
||||||
"""处理群消息"""
|
"""处理聊天流消息"""
|
||||||
# if int(time.time() / 3) == time.time() / 3:
|
container = self.get_container(chat_id)
|
||||||
# print(f"\033[1;34m[调试]\033[0m 开始处理群{group_id}的消息")
|
|
||||||
container = self.get_container(group_id)
|
|
||||||
if container.has_messages():
|
if container.has_messages():
|
||||||
#最早的对象,可能是思考消息,也可能是发送消息
|
# print(f"处理有message的容器chat_id: {chat_id}")
|
||||||
message_earliest = container.get_earliest_message() #一个message_thinking or message_sending
|
message_earliest = container.get_earliest_message()
|
||||||
|
|
||||||
#如果是思考消息
|
if isinstance(message_earliest, MessageThinking):
|
||||||
if isinstance(message_earliest, Message_Thinking):
|
|
||||||
#优先等待这条消息
|
|
||||||
message_earliest.update_thinking_time()
|
message_earliest.update_thinking_time()
|
||||||
thinking_time = message_earliest.thinking_time
|
thinking_time = message_earliest.thinking_time
|
||||||
print(f"\033[1;34m[调试]\033[0m 消息正在思考中,已思考{int(thinking_time)}秒\033[K\r", end='', flush=True)
|
print(
|
||||||
|
f"消息正在思考中,已思考{int(thinking_time)}秒\r",
|
||||||
|
end="",
|
||||||
|
flush=True,
|
||||||
|
)
|
||||||
|
|
||||||
# 检查是否超时
|
# 检查是否超时
|
||||||
if thinking_time > global_config.thinking_timeout:
|
if thinking_time > global_config.thinking_timeout:
|
||||||
print(f"\033[1;33m[警告]\033[0m 消息思考超时({thinking_time}秒),移除该消息")
|
logger.warning(f"消息思考超时({thinking_time}秒),移除该消息")
|
||||||
container.remove_message(message_earliest)
|
container.remove_message(message_earliest)
|
||||||
else:# 如果不是message_thinking就只能是message_sending
|
|
||||||
print(f"\033[1;34m[调试]\033[0m 消息'{message_earliest.processed_plain_text}'正在发送中")
|
|
||||||
#直接发,等什么呢
|
|
||||||
if message_earliest.is_head and message_earliest.update_thinking_time() >30:
|
|
||||||
await message_sender.send_group_message(group_id, message_earliest.processed_plain_text, auto_escape=False, reply_message_id=message_earliest.reply_message_id)
|
|
||||||
else:
|
else:
|
||||||
await message_sender.send_group_message(group_id, message_earliest.processed_plain_text, auto_escape=False)
|
|
||||||
#移除消息
|
if (
|
||||||
if message_earliest.is_emoji:
|
message_earliest.is_head
|
||||||
message_earliest.processed_plain_text = "[表情包]"
|
and message_earliest.update_thinking_time() > 30
|
||||||
await self.storage.store_message(message_earliest, None)
|
and not message_earliest.is_private_message() # 避免在私聊时插入reply
|
||||||
|
):
|
||||||
|
await message_sender.send_message(message_earliest.set_reply())
|
||||||
|
else:
|
||||||
|
await message_sender.send_message(message_earliest)
|
||||||
|
await message_earliest.process()
|
||||||
|
|
||||||
|
print(
|
||||||
|
f"\033[1;34m[调试]\033[0m 消息“{truncate_message(message_earliest.processed_plain_text)}”正在发送中"
|
||||||
|
)
|
||||||
|
|
||||||
|
await self.storage.store_message(
|
||||||
|
message_earliest, message_earliest.chat_stream, None
|
||||||
|
)
|
||||||
|
|
||||||
container.remove_message(message_earliest)
|
container.remove_message(message_earliest)
|
||||||
|
|
||||||
#获取并处理超时消息
|
message_timeout = container.get_timeout_messages()
|
||||||
message_timeout = container.get_timeout_messages() #也许是一堆message_sending
|
|
||||||
if message_timeout:
|
if message_timeout:
|
||||||
print(f"\033[1;34m[调试]\033[0m 发现{len(message_timeout)}条超时消息")
|
logger.warning(f"发现{len(message_timeout)}条超时消息")
|
||||||
for msg in message_timeout:
|
for msg in message_timeout:
|
||||||
if msg == message_earliest:
|
if msg == message_earliest:
|
||||||
continue # 跳过已经处理过的消息
|
continue
|
||||||
|
|
||||||
try:
|
try:
|
||||||
#发送
|
if (
|
||||||
if msg.is_head and msg.update_thinking_time() >30:
|
msg.is_head
|
||||||
await message_sender.send_group_message(group_id, msg.processed_plain_text, auto_escape=False, reply_message_id=msg.reply_message_id)
|
and msg.update_thinking_time() > 30
|
||||||
|
and not message_earliest.is_private_message() # 避免在私聊时插入reply
|
||||||
|
):
|
||||||
|
await message_sender.send_message(msg.set_reply())
|
||||||
else:
|
else:
|
||||||
await message_sender.send_group_message(group_id, msg.processed_plain_text, auto_escape=False)
|
await message_sender.send_message(msg)
|
||||||
|
|
||||||
|
# if msg.is_emoji:
|
||||||
|
# msg.processed_plain_text = "[表情包]"
|
||||||
|
await msg.process()
|
||||||
|
await self.storage.store_message(msg, msg.chat_stream, None)
|
||||||
|
|
||||||
#如果是表情包,则替换为"[表情包]"
|
|
||||||
if msg.is_emoji:
|
|
||||||
msg.processed_plain_text = "[表情包]"
|
|
||||||
await self.storage.store_message(msg, None)
|
|
||||||
|
|
||||||
# 安全地移除消息
|
|
||||||
if not container.remove_message(msg):
|
if not container.remove_message(msg):
|
||||||
print("\033[1;33m[警告]\033[0m 尝试删除不存在的消息")
|
logger.warning("尝试删除不存在的消息")
|
||||||
except Exception as e:
|
except Exception:
|
||||||
print(f"\033[1;31m[错误]\033[0m 处理超时消息时发生错误: {e}")
|
logger.exception("处理超时消息时发生错误")
|
||||||
continue
|
continue
|
||||||
|
|
||||||
async def start_processor(self):
|
async def start_processor(self):
|
||||||
@@ -215,11 +228,12 @@ class MessageManager:
|
|||||||
while self._running:
|
while self._running:
|
||||||
await asyncio.sleep(1)
|
await asyncio.sleep(1)
|
||||||
tasks = []
|
tasks = []
|
||||||
for group_id in self.containers.keys():
|
for chat_id in self.containers.keys():
|
||||||
tasks.append(self.process_group_messages(group_id))
|
tasks.append(self.process_chat_messages(chat_id))
|
||||||
|
|
||||||
await asyncio.gather(*tasks)
|
await asyncio.gather(*tasks)
|
||||||
|
|
||||||
|
|
||||||
# 创建全局消息管理器实例
|
# 创建全局消息管理器实例
|
||||||
message_manager = MessageManager()
|
message_manager = MessageManager()
|
||||||
# 创建全局发送器实例
|
# 创建全局发送器实例
|
||||||
|
|||||||
@@ -1,20 +1,21 @@
|
|||||||
import random
|
import random
|
||||||
import time
|
import time
|
||||||
from typing import Optional
|
from typing import Optional
|
||||||
|
from loguru import logger
|
||||||
|
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
from ..memory_system.memory import hippocampus, memory_graph
|
from ..memory_system.memory import hippocampus, memory_graph
|
||||||
from ..moods.moods import MoodManager
|
from ..moods.moods import MoodManager
|
||||||
from ..schedule.schedule_generator import bot_schedule
|
from ..schedule.schedule_generator import bot_schedule
|
||||||
from .config import global_config
|
from .config import global_config
|
||||||
from .utils import get_embedding, get_recent_group_detailed_plain_text
|
from .utils import get_embedding, get_recent_group_detailed_plain_text
|
||||||
|
from .chat_stream import chat_manager
|
||||||
|
|
||||||
|
|
||||||
class PromptBuilder:
|
class PromptBuilder:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.prompt_built = ''
|
self.prompt_built = ''
|
||||||
self.activate_messages = ''
|
self.activate_messages = ''
|
||||||
self.db = Database.get_instance()
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@@ -22,7 +23,7 @@ class PromptBuilder:
|
|||||||
message_txt: str,
|
message_txt: str,
|
||||||
sender_name: str = "某人",
|
sender_name: str = "某人",
|
||||||
relationship_value: float = 0.0,
|
relationship_value: float = 0.0,
|
||||||
group_id: Optional[int] = None) -> tuple[str, str]:
|
stream_id: Optional[int] = None) -> tuple[str, str]:
|
||||||
"""构建prompt
|
"""构建prompt
|
||||||
|
|
||||||
Args:
|
Args:
|
||||||
@@ -34,49 +35,54 @@ class PromptBuilder:
|
|||||||
Returns:
|
Returns:
|
||||||
str: 构建好的prompt
|
str: 构建好的prompt
|
||||||
"""
|
"""
|
||||||
#先禁用关系
|
# 先禁用关系
|
||||||
if 0 > 30:
|
if 0 > 30:
|
||||||
relation_prompt = "关系特别特别好,你很喜欢喜欢他"
|
relation_prompt = "关系特别特别好,你很喜欢喜欢他"
|
||||||
relation_prompt_2 = "热情发言或者回复"
|
relation_prompt_2 = "热情发言或者回复"
|
||||||
elif 0 <-20:
|
elif 0 < -20:
|
||||||
relation_prompt = "关系很差,你很讨厌他"
|
relation_prompt = "关系很差,你很讨厌他"
|
||||||
relation_prompt_2 = "骂他"
|
relation_prompt_2 = "骂他"
|
||||||
else:
|
else:
|
||||||
relation_prompt = "关系一般"
|
relation_prompt = "关系一般"
|
||||||
relation_prompt_2 = "发言或者回复"
|
relation_prompt_2 = "发言或者回复"
|
||||||
|
|
||||||
#开始构建prompt
|
# 开始构建prompt
|
||||||
|
|
||||||
|
# 心情
|
||||||
#心情
|
|
||||||
mood_manager = MoodManager.get_instance()
|
mood_manager = MoodManager.get_instance()
|
||||||
mood_prompt = mood_manager.get_prompt()
|
mood_prompt = mood_manager.get_prompt()
|
||||||
|
|
||||||
|
# 日程构建
|
||||||
#日程构建
|
|
||||||
current_date = time.strftime("%Y-%m-%d", time.localtime())
|
current_date = time.strftime("%Y-%m-%d", time.localtime())
|
||||||
current_time = time.strftime("%H:%M:%S", time.localtime())
|
current_time = time.strftime("%H:%M:%S", time.localtime())
|
||||||
bot_schedule_now_time,bot_schedule_now_activity = bot_schedule.get_current_task()
|
bot_schedule_now_time, bot_schedule_now_activity = bot_schedule.get_current_task()
|
||||||
prompt_date = f'''今天是{current_date},现在是{current_time},你今天的日程是:\n{bot_schedule.today_schedule}\n你现在正在{bot_schedule_now_activity}\n'''
|
prompt_date = f'''今天是{current_date},现在是{current_time},你今天的日程是:\n{bot_schedule.today_schedule}\n你现在正在{bot_schedule_now_activity}\n'''
|
||||||
|
|
||||||
#知识构建
|
# 知识构建
|
||||||
start_time = time.time()
|
start_time = time.time()
|
||||||
|
|
||||||
prompt_info = ''
|
prompt_info = ''
|
||||||
promt_info_prompt = ''
|
promt_info_prompt = ''
|
||||||
prompt_info = await self.get_prompt_info(message_txt,threshold=0.5)
|
prompt_info = await self.get_prompt_info(message_txt, threshold=0.5)
|
||||||
if prompt_info:
|
if prompt_info:
|
||||||
prompt_info = f'''\n----------------------------------------------------\n你有以下这些[知识]:\n{prompt_info}\n请你记住上面的[知识],之后可能会用到\n----------------------------------------------------\n'''
|
prompt_info = f'''你有以下这些[知识]:{prompt_info}请你记住上面的[
|
||||||
|
知识],之后可能会用到-'''
|
||||||
|
|
||||||
end_time = time.time()
|
end_time = time.time()
|
||||||
print(f"\033[1;32m[知识检索]\033[0m 耗时: {(end_time - start_time):.3f}秒")
|
logger.debug(f"知识检索耗时: {(end_time - start_time):.3f}秒")
|
||||||
|
|
||||||
# 获取聊天上下文
|
# 获取聊天上下文
|
||||||
|
chat_in_group=True
|
||||||
chat_talking_prompt = ''
|
chat_talking_prompt = ''
|
||||||
if group_id:
|
if stream_id:
|
||||||
chat_talking_prompt = get_recent_group_detailed_plain_text(self.db, group_id, limit=global_config.MAX_CONTEXT_SIZE,combine = True)
|
chat_talking_prompt = get_recent_group_detailed_plain_text(stream_id, limit=global_config.MAX_CONTEXT_SIZE,combine = True)
|
||||||
|
chat_stream=chat_manager.get_stream(stream_id)
|
||||||
|
if chat_stream.group_info:
|
||||||
chat_talking_prompt = f"以下是群里正在聊天的内容:\n{chat_talking_prompt}"
|
chat_talking_prompt = f"以下是群里正在聊天的内容:\n{chat_talking_prompt}"
|
||||||
|
else:
|
||||||
|
chat_in_group=False
|
||||||
|
chat_talking_prompt = f"以下是你正在和{sender_name}私聊的内容:\n{chat_talking_prompt}"
|
||||||
|
# print(f"\033[1;34m[调试]\033[0m 已从数据库获取群 {group_id} 的消息记录:{chat_talking_prompt}")
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@@ -101,57 +107,54 @@ class PromptBuilder:
|
|||||||
memory_prompt = "看到这些聊天,你想起来:\n" + "\n".join(memory_items) + "\n"
|
memory_prompt = "看到这些聊天,你想起来:\n" + "\n".join(memory_items) + "\n"
|
||||||
|
|
||||||
# 打印调试信息
|
# 打印调试信息
|
||||||
print("\n\033[1;32m[记忆检索]\033[0m 找到以下相关记忆:")
|
logger.debug("[记忆检索]找到以下相关记忆:")
|
||||||
for memory in relevant_memories:
|
for memory in relevant_memories:
|
||||||
print(f"- 主题「{memory['topic']}」[相似度: {memory['similarity']:.2f}]: {memory['content']}")
|
logger.debug(f"- 主题「{memory['topic']}」[相似度: {memory['similarity']:.2f}]: {memory['content']}")
|
||||||
|
|
||||||
end_time = time.time()
|
end_time = time.time()
|
||||||
print(f"\033[1;32m[回忆耗时]\033[0m 耗时: {(end_time - start_time):.3f}秒")
|
logger.info(f"回忆耗时: {(end_time - start_time):.3f}秒")
|
||||||
|
|
||||||
|
# 激活prompt构建
|
||||||
|
|
||||||
#激活prompt构建
|
|
||||||
activate_prompt = ''
|
activate_prompt = ''
|
||||||
activate_prompt = f"以上是群里正在进行的聊天,{memory_prompt} 现在昵称为 '{sender_name}' 的用户说的:{message_txt}。引起了你的注意,你和他{relation_prompt},{mood_prompt},你想要{relation_prompt_2}。"
|
if chat_in_group:
|
||||||
|
activate_prompt = f"以上是群里正在进行的聊天,{memory_prompt} 现在昵称为 '{sender_name}' 的用户说的:{message_txt}。引起了你的注意,你和ta{relation_prompt},{mood_prompt},你想要{relation_prompt_2}。"
|
||||||
#检测机器人相关词汇,改为关键词检测与反应功能了,提取到全局配置中
|
else:
|
||||||
# bot_keywords = ['人机', 'bot', '机器', '入机', 'robot', '机器人']
|
activate_prompt = f"以上是你正在和{sender_name}私聊的内容,{memory_prompt} 现在昵称为 '{sender_name}' 的用户说的:{message_txt}。引起了你的注意,你和ta{relation_prompt},{mood_prompt},你想要{relation_prompt_2}。"
|
||||||
# is_bot = any(keyword in message_txt.lower() for keyword in bot_keywords)
|
|
||||||
# if is_bot:
|
|
||||||
# is_bot_prompt = '有人说你是人机或者机器人,否定这一事实,攻击或反问他。注意,只有认为你是机器人才回复,否则不要否认'
|
|
||||||
# else:
|
|
||||||
# is_bot_prompt = ''
|
|
||||||
|
|
||||||
# 关键词检测与反应
|
# 关键词检测与反应
|
||||||
keywords_reaction_prompt = ''
|
keywords_reaction_prompt = ''
|
||||||
for rule in global_config.keywords_reaction_rules:
|
for rule in global_config.keywords_reaction_rules:
|
||||||
if rule.get("enable", False):
|
if rule.get("enable", False):
|
||||||
if any(keyword in message_txt.lower() for keyword in rule.get("keywords", [])):
|
if any(keyword in message_txt.lower() for keyword in rule.get("keywords", [])):
|
||||||
print(f"检测到以下关键词之一:{rule.get('keywords', [])},触发反应:{rule.get('reaction', '')}")
|
logger.info(f"检测到以下关键词之一:{rule.get('keywords', [])},触发反应:{rule.get('reaction', '')}")
|
||||||
keywords_reaction_prompt += rule.get("reaction", "") + ','
|
keywords_reaction_prompt += rule.get("reaction", "") + ','
|
||||||
|
|
||||||
|
|
||||||
#人格选择
|
#人格选择
|
||||||
personality=global_config.PROMPT_PERSONALITY
|
personality=global_config.PROMPT_PERSONALITY
|
||||||
probability_1 = global_config.PERSONALITY_1
|
probability_1 = global_config.PERSONALITY_1
|
||||||
probability_2 = global_config.PERSONALITY_2
|
probability_2 = global_config.PERSONALITY_2
|
||||||
probability_3 = global_config.PERSONALITY_3
|
probability_3 = global_config.PERSONALITY_3
|
||||||
prompt_personality = ''
|
|
||||||
|
prompt_personality = f'{activate_prompt}你的网名叫{global_config.BOT_NICKNAME},你还有很多别名:{"/".join(global_config.BOT_ALIAS_NAMES)},'
|
||||||
personality_choice = random.random()
|
personality_choice = random.random()
|
||||||
|
if chat_in_group:
|
||||||
|
prompt_in_group=f"你正在浏览{chat_stream.platform}群"
|
||||||
|
else:
|
||||||
|
prompt_in_group=f"你正在{chat_stream.platform}上和{sender_name}私聊"
|
||||||
if personality_choice < probability_1: # 第一种人格
|
if personality_choice < probability_1: # 第一种人格
|
||||||
prompt_personality = f'''{activate_prompt}你的网名叫{global_config.BOT_NICKNAME},{personality[0]}, 你正在浏览qq群,{promt_info_prompt},
|
prompt_personality += f'''{personality[0]}, 你正在浏览qq群,{promt_info_prompt},
|
||||||
现在请你给出日常且口语化的回复,平淡一些,尽量简短一些。{keywords_reaction_prompt}
|
现在请你给出日常且口语化的回复,平淡一些,尽量简短一些。{keywords_reaction_prompt}
|
||||||
请注意把握群里的聊天内容,不要刻意突出自身学科背景,不要回复的太有条理,可以有个性。'''
|
请注意把握群里的聊天内容,不要刻意突出自身学科背景,不要回复的太有条理,可以有个性。'''
|
||||||
elif personality_choice < probability_1 + probability_2: # 第二种人格
|
elif personality_choice < probability_1 + probability_2: # 第二种人格
|
||||||
prompt_personality = f'''{activate_prompt}你的网名叫{global_config.BOT_NICKNAME},{personality[1]}, 你正在浏览qq群,{promt_info_prompt},
|
prompt_personality += f'''{personality[1]}, 你正在浏览qq群,{promt_info_prompt},
|
||||||
现在请你给出日常且口语化的回复,请表现你自己的见解,不要一昧迎合,尽量简短一些。{keywords_reaction_prompt}
|
现在请你给出日常且口语化的回复,请表现你自己的见解,不要一昧迎合,尽量简短一些。{keywords_reaction_prompt}
|
||||||
请你表达自己的见解和观点。可以有个性。'''
|
请你表达自己的见解和观点。可以有个性。'''
|
||||||
else: # 第三种人格
|
else: # 第三种人格
|
||||||
prompt_personality = f'''{activate_prompt}你的网名叫{global_config.BOT_NICKNAME},{personality[2]}, 你正在浏览qq群,{promt_info_prompt},
|
prompt_personality += f'''{personality[2]}, 你正在浏览qq群,{promt_info_prompt},
|
||||||
现在请你给出日常且口语化的回复,请表现你自己的见解,不要一昧迎合,尽量简短一些。{keywords_reaction_prompt}
|
现在请你给出日常且口语化的回复,请表现你自己的见解,不要一昧迎合,尽量简短一些。{keywords_reaction_prompt}
|
||||||
请你表达自己的见解和观点。可以有个性。'''
|
请你表达自己的见解和观点。可以有个性。'''
|
||||||
|
|
||||||
#中文高手(新加的好玩功能)
|
# 中文高手(新加的好玩功能)
|
||||||
prompt_ger = ''
|
prompt_ger = ''
|
||||||
if random.random() < 0.04:
|
if random.random() < 0.04:
|
||||||
prompt_ger += '你喜欢用倒装句'
|
prompt_ger += '你喜欢用倒装句'
|
||||||
@@ -160,10 +163,10 @@ class PromptBuilder:
|
|||||||
if random.random() < 0.01:
|
if random.random() < 0.01:
|
||||||
prompt_ger += '你喜欢用文言文'
|
prompt_ger += '你喜欢用文言文'
|
||||||
|
|
||||||
#额外信息要求
|
# 额外信息要求
|
||||||
extra_info = '''但是记得回复平淡一些,简短一些,尤其注意在没明确提到时不要过多提及自身的背景, 不要直接回复别人发的表情包,记住不要输出多余内容(包括前后缀,冒号和引号,括号,表情等),只需要输出回复内容就好,不要输出其他任何内容'''
|
extra_info = '''但是记得回复平淡一些,简短一些,尤其注意在没明确提到时不要过多提及自身的背景, 不要直接回复别人发的表情包,记住不要输出多余内容(包括前后缀,冒号和引号,括号,表情等),只需要输出回复内容就好,不要输出其他任何内容'''
|
||||||
|
|
||||||
#合并prompt
|
# 合并prompt
|
||||||
prompt = ""
|
prompt = ""
|
||||||
prompt += f"{prompt_info}\n"
|
prompt += f"{prompt_info}\n"
|
||||||
prompt += f"{prompt_date}\n"
|
prompt += f"{prompt_date}\n"
|
||||||
@@ -173,9 +176,9 @@ class PromptBuilder:
|
|||||||
prompt += f"{extra_info}\n"
|
prompt += f"{extra_info}\n"
|
||||||
|
|
||||||
'''读空气prompt处理'''
|
'''读空气prompt处理'''
|
||||||
activate_prompt_check=f"以上是群里正在进行的聊天,昵称为 '{sender_name}' 的用户说的:{message_txt}。引起了你的注意,你和他{relation_prompt},你想要{relation_prompt_2},但是这不一定是合适的时机,请你决定是否要回应这条消息。"
|
activate_prompt_check = f"以上是群里正在进行的聊天,昵称为 '{sender_name}' 的用户说的:{message_txt}。引起了你的注意,你和他{relation_prompt},你想要{relation_prompt_2},但是这不一定是合适的时机,请你决定是否要回应这条消息。"
|
||||||
prompt_personality_check = ''
|
prompt_personality_check = ''
|
||||||
extra_check_info=f"请注意把握群里的聊天内容的基础上,综合群内的氛围,例如,和{global_config.BOT_NICKNAME}相关的话题要积极回复,如果是at自己的消息一定要回复,如果自己正在和别人聊天一定要回复,其他话题如果合适搭话也可以回复,如果认为应该回复请输出yes,否则输出no,请注意是决定是否需要回复,而不是编写回复内容,除了yes和no不要输出任何回复内容。"
|
extra_check_info = f"请注意把握群里的聊天内容的基础上,综合群内的氛围,例如,和{global_config.BOT_NICKNAME}相关的话题要积极回复,如果是at自己的消息一定要回复,如果自己正在和别人聊天一定要回复,其他话题如果合适搭话也可以回复,如果认为应该回复请输出yes,否则输出no,请注意是决定是否需要回复,而不是编写回复内容,除了yes和no不要输出任何回复内容。"
|
||||||
if personality_choice < probability_1: # 第一种人格
|
if personality_choice < probability_1: # 第一种人格
|
||||||
prompt_personality_check = f'''你的网名叫{global_config.BOT_NICKNAME},{personality[0]}, 你正在浏览qq群,{promt_info_prompt} {activate_prompt_check} {extra_check_info}'''
|
prompt_personality_check = f'''你的网名叫{global_config.BOT_NICKNAME},{personality[0]}, 你正在浏览qq群,{promt_info_prompt} {activate_prompt_check} {extra_check_info}'''
|
||||||
elif personality_choice < probability_1 + probability_2: # 第二种人格
|
elif personality_choice < probability_1 + probability_2: # 第二种人格
|
||||||
@@ -183,34 +186,36 @@ class PromptBuilder:
|
|||||||
else: # 第三种人格
|
else: # 第三种人格
|
||||||
prompt_personality_check = f'''你的网名叫{global_config.BOT_NICKNAME},{personality[2]}, 你正在浏览qq群,{promt_info_prompt} {activate_prompt_check} {extra_check_info}'''
|
prompt_personality_check = f'''你的网名叫{global_config.BOT_NICKNAME},{personality[2]}, 你正在浏览qq群,{promt_info_prompt} {activate_prompt_check} {extra_check_info}'''
|
||||||
|
|
||||||
prompt_check_if_response=f"{prompt_info}\n{prompt_date}\n{chat_talking_prompt}\n{prompt_personality_check}"
|
prompt_check_if_response = f"{prompt_info}\n{prompt_date}\n{chat_talking_prompt}\n{prompt_personality_check}"
|
||||||
|
|
||||||
return prompt,prompt_check_if_response
|
return prompt, prompt_check_if_response
|
||||||
|
|
||||||
def _build_initiative_prompt_select(self,group_id):
|
def _build_initiative_prompt_select(self, group_id, probability_1=0.8, probability_2=0.1):
|
||||||
current_date = time.strftime("%Y-%m-%d", time.localtime())
|
current_date = time.strftime("%Y-%m-%d", time.localtime())
|
||||||
current_time = time.strftime("%H:%M:%S", time.localtime())
|
current_time = time.strftime("%H:%M:%S", time.localtime())
|
||||||
bot_schedule_now_time,bot_schedule_now_activity = bot_schedule.get_current_task()
|
bot_schedule_now_time, bot_schedule_now_activity = bot_schedule.get_current_task()
|
||||||
prompt_date = f'''今天是{current_date},现在是{current_time},你今天的日程是:\n{bot_schedule.today_schedule}\n你现在正在{bot_schedule_now_activity}\n'''
|
prompt_date = f'''今天是{current_date},现在是{current_time},你今天的日程是:\n{bot_schedule.today_schedule}\n你现在正在{bot_schedule_now_activity}\n'''
|
||||||
|
|
||||||
chat_talking_prompt = ''
|
chat_talking_prompt = ''
|
||||||
if group_id:
|
if group_id:
|
||||||
chat_talking_prompt = get_recent_group_detailed_plain_text(self.db, group_id, limit=global_config.MAX_CONTEXT_SIZE,combine = True)
|
chat_talking_prompt = get_recent_group_detailed_plain_text(group_id,
|
||||||
|
limit=global_config.MAX_CONTEXT_SIZE,
|
||||||
|
combine=True)
|
||||||
|
|
||||||
chat_talking_prompt = f"以下是群里正在聊天的内容:\n{chat_talking_prompt}"
|
chat_talking_prompt = f"以下是群里正在聊天的内容:\n{chat_talking_prompt}"
|
||||||
# print(f"\033[1;34m[调试]\033[0m 已从数据库获取群 {group_id} 的消息记录:{chat_talking_prompt}")
|
# print(f"\033[1;34m[调试]\033[0m 已从数据库获取群 {group_id} 的消息记录:{chat_talking_prompt}")
|
||||||
|
|
||||||
# 获取主动发言的话题
|
# 获取主动发言的话题
|
||||||
all_nodes=memory_graph.dots
|
all_nodes = memory_graph.dots
|
||||||
all_nodes=filter(lambda dot:len(dot[1]['memory_items'])>3,all_nodes)
|
all_nodes = filter(lambda dot: len(dot[1]['memory_items']) > 3, all_nodes)
|
||||||
nodes_for_select=random.sample(all_nodes,5)
|
nodes_for_select = random.sample(all_nodes, 5)
|
||||||
topics=[info[0] for info in nodes_for_select]
|
topics = [info[0] for info in nodes_for_select]
|
||||||
infos=[info[1] for info in nodes_for_select]
|
infos = [info[1] for info in nodes_for_select]
|
||||||
|
|
||||||
#激活prompt构建
|
# 激活prompt构建
|
||||||
activate_prompt = ''
|
activate_prompt = ''
|
||||||
activate_prompt = "以上是群里正在进行的聊天。"
|
activate_prompt = "以上是群里正在进行的聊天。"
|
||||||
personality=global_config.PROMPT_PERSONALITY
|
personality = global_config.PROMPT_PERSONALITY
|
||||||
prompt_personality = ''
|
prompt_personality = ''
|
||||||
personality_choice = random.random()
|
personality_choice = random.random()
|
||||||
if personality_choice < probability_1: # 第一种人格
|
if personality_choice < probability_1: # 第一种人格
|
||||||
@@ -220,30 +225,29 @@ class PromptBuilder:
|
|||||||
else: # 第三种人格
|
else: # 第三种人格
|
||||||
prompt_personality = f'''{activate_prompt}你的网名叫{global_config.BOT_NICKNAME},{personality[2]}'''
|
prompt_personality = f'''{activate_prompt}你的网名叫{global_config.BOT_NICKNAME},{personality[2]}'''
|
||||||
|
|
||||||
topics_str=','.join(f"\"{topics}\"")
|
topics_str = ','.join(f"\"{topics}\"")
|
||||||
prompt_for_select=f"你现在想在群里发言,回忆了一下,想到几个话题,分别是{topics_str},综合当前状态以及群内气氛,请你在其中选择一个合适的话题,注意只需要输出话题,除了话题什么也不要输出(双引号也不要输出)"
|
prompt_for_select = f"你现在想在群里发言,回忆了一下,想到几个话题,分别是{topics_str},综合当前状态以及群内气氛,请你在其中选择一个合适的话题,注意只需要输出话题,除了话题什么也不要输出(双引号也不要输出)"
|
||||||
|
|
||||||
prompt_initiative_select=f"{prompt_date}\n{prompt_personality}\n{prompt_for_select}"
|
prompt_initiative_select = f"{prompt_date}\n{prompt_personality}\n{prompt_for_select}"
|
||||||
prompt_regular=f"{prompt_date}\n{prompt_personality}"
|
prompt_regular = f"{prompt_date}\n{prompt_personality}"
|
||||||
|
|
||||||
return prompt_initiative_select,nodes_for_select,prompt_regular
|
return prompt_initiative_select, nodes_for_select, prompt_regular
|
||||||
|
|
||||||
def _build_initiative_prompt_check(self,selected_node,prompt_regular):
|
def _build_initiative_prompt_check(self, selected_node, prompt_regular):
|
||||||
memory=random.sample(selected_node['memory_items'],3)
|
memory = random.sample(selected_node['memory_items'], 3)
|
||||||
memory='\n'.join(memory)
|
memory = '\n'.join(memory)
|
||||||
prompt_for_check=f"{prompt_regular}你现在想在群里发言,回忆了一下,想到一个话题,是{selected_node['concept']},关于这个话题的记忆有\n{memory}\n,以这个作为主题发言合适吗?请在把握群里的聊天内容的基础上,综合群内的氛围,如果认为应该发言请输出yes,否则输出no,请注意是决定是否需要发言,而不是编写回复内容,除了yes和no不要输出任何回复内容。"
|
prompt_for_check = f"{prompt_regular}你现在想在群里发言,回忆了一下,想到一个话题,是{selected_node['concept']},关于这个话题的记忆有\n{memory}\n,以这个作为主题发言合适吗?请在把握群里的聊天内容的基础上,综合群内的氛围,如果认为应该发言请输出yes,否则输出no,请注意是决定是否需要发言,而不是编写回复内容,除了yes和no不要输出任何回复内容。"
|
||||||
return prompt_for_check,memory
|
return prompt_for_check, memory
|
||||||
|
|
||||||
def _build_initiative_prompt(self,selected_node,prompt_regular,memory):
|
def _build_initiative_prompt(self, selected_node, prompt_regular, memory):
|
||||||
prompt_for_initiative=f"{prompt_regular}你现在想在群里发言,回忆了一下,想到一个话题,是{selected_node['concept']},关于这个话题的记忆有\n{memory}\n,请在把握群里的聊天内容的基础上,综合群内的氛围,以日常且口语化的口吻,简短且随意一点进行发言,不要说的太有条理,可以有个性。记住不要输出多余内容(包括前后缀,冒号和引号,括号,表情等)"
|
prompt_for_initiative = f"{prompt_regular}你现在想在群里发言,回忆了一下,想到一个话题,是{selected_node['concept']},关于这个话题的记忆有\n{memory}\n,请在把握群里的聊天内容的基础上,综合群内的氛围,以日常且口语化的口吻,简短且随意一点进行发言,不要说的太有条理,可以有个性。记住不要输出多余内容(包括前后缀,冒号和引号,括号,表情等)"
|
||||||
return prompt_for_initiative
|
return prompt_for_initiative
|
||||||
|
|
||||||
|
async def get_prompt_info(self, message: str, threshold: float):
|
||||||
async def get_prompt_info(self,message:str,threshold:float):
|
|
||||||
related_info = ''
|
related_info = ''
|
||||||
print(f"\033[1;34m[调试]\033[0m 获取知识库内容,元消息:{message[:30]}...,消息长度: {len(message)}")
|
logger.debug(f"获取知识库内容,元消息:{message[:30]}...,消息长度: {len(message)}")
|
||||||
embedding = await get_embedding(message)
|
embedding = await get_embedding(message)
|
||||||
related_info += self.get_info_from_db(embedding,threshold=threshold)
|
related_info += self.get_info_from_db(embedding, threshold=threshold)
|
||||||
|
|
||||||
return related_info
|
return related_info
|
||||||
|
|
||||||
@@ -306,7 +310,7 @@ class PromptBuilder:
|
|||||||
{"$project": {"content": 1, "similarity": 1}}
|
{"$project": {"content": 1, "similarity": 1}}
|
||||||
]
|
]
|
||||||
|
|
||||||
results = list(self.db.db.knowledges.aggregate(pipeline))
|
results = list(db.knowledges.aggregate(pipeline))
|
||||||
# print(f"\033[1;34m[调试]\033[0m获取知识库内容结果: {results}")
|
# print(f"\033[1;34m[调试]\033[0m获取知识库内容结果: {results}")
|
||||||
|
|
||||||
if not results:
|
if not results:
|
||||||
@@ -315,4 +319,5 @@ class PromptBuilder:
|
|||||||
# 返回所有找到的内容,用换行分隔
|
# 返回所有找到的内容,用换行分隔
|
||||||
return '\n'.join(str(result['content']) for result in results)
|
return '\n'.join(str(result['content']) for result in results)
|
||||||
|
|
||||||
|
|
||||||
prompt_builder = PromptBuilder()
|
prompt_builder = PromptBuilder()
|
||||||
@@ -1,8 +1,10 @@
|
|||||||
import asyncio
|
import asyncio
|
||||||
from typing import Optional
|
from typing import Optional
|
||||||
|
from loguru import logger
|
||||||
|
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
|
from .message_base import UserInfo
|
||||||
|
from .chat_stream import ChatStream
|
||||||
|
|
||||||
class Impression:
|
class Impression:
|
||||||
traits: str = None
|
traits: str = None
|
||||||
@@ -11,62 +13,69 @@ class Impression:
|
|||||||
|
|
||||||
relationship_value: float = None
|
relationship_value: float = None
|
||||||
|
|
||||||
|
|
||||||
class Relationship:
|
class Relationship:
|
||||||
user_id: int = None
|
user_id: int = None
|
||||||
# impression: Impression = None
|
platform: str = None
|
||||||
# group_id: int = None
|
|
||||||
# group_name: str = None
|
|
||||||
gender: str = None
|
gender: str = None
|
||||||
age: int = None
|
age: int = None
|
||||||
nickname: str = None
|
nickname: str = None
|
||||||
relationship_value: float = None
|
relationship_value: float = None
|
||||||
saved = False
|
saved = False
|
||||||
|
|
||||||
def __init__(self, user_id: int, data=None, **kwargs):
|
def __init__(self, chat:ChatStream=None,data:dict=None):
|
||||||
if isinstance(data, dict):
|
self.user_id=chat.user_info.user_id if chat else data.get('user_id',0)
|
||||||
# 如果输入是字典,使用字典解析
|
self.platform=chat.platform if chat else data.get('platform','')
|
||||||
self.user_id = data.get('user_id')
|
self.nickname=chat.user_info.user_nickname if chat else data.get('nickname','')
|
||||||
self.gender = data.get('gender')
|
self.relationship_value=data.get('relationship_value',0) if data else 0
|
||||||
self.age = data.get('age')
|
self.age=data.get('age',0) if data else 0
|
||||||
self.nickname = data.get('nickname')
|
self.gender=data.get('gender','') if data else ''
|
||||||
self.relationship_value = data.get('relationship_value', 0.0)
|
|
||||||
self.saved = data.get('saved', False)
|
|
||||||
else:
|
|
||||||
# 如果是直接传入属性值
|
|
||||||
self.user_id = kwargs.get('user_id')
|
|
||||||
self.gender = kwargs.get('gender')
|
|
||||||
self.age = kwargs.get('age')
|
|
||||||
self.nickname = kwargs.get('nickname')
|
|
||||||
self.relationship_value = kwargs.get('relationship_value', 0.0)
|
|
||||||
self.saved = kwargs.get('saved', False)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
class RelationshipManager:
|
class RelationshipManager:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.relationships: dict[int, Relationship] = {}
|
self.relationships: dict[tuple[int, str], Relationship] = {} # 修改为使用(user_id, platform)作为键
|
||||||
|
|
||||||
|
async def update_relationship(self,
|
||||||
|
chat_stream:ChatStream,
|
||||||
|
data: dict = None,
|
||||||
|
**kwargs) -> Optional[Relationship]:
|
||||||
|
"""更新或创建关系
|
||||||
|
Args:
|
||||||
|
chat_stream: 聊天流对象
|
||||||
|
data: 字典格式的数据(可选)
|
||||||
|
**kwargs: 其他参数
|
||||||
|
Returns:
|
||||||
|
Relationship: 关系对象
|
||||||
|
"""
|
||||||
|
# 确定user_id和platform
|
||||||
|
if chat_stream.user_info is not None:
|
||||||
|
user_id = chat_stream.user_info.user_id
|
||||||
|
platform = chat_stream.user_info.platform or 'qq'
|
||||||
|
else:
|
||||||
|
platform = platform or 'qq'
|
||||||
|
|
||||||
|
if user_id is None:
|
||||||
|
raise ValueError("必须提供user_id或user_info")
|
||||||
|
|
||||||
|
# 使用(user_id, platform)作为键
|
||||||
|
key = (user_id, platform)
|
||||||
|
|
||||||
async def update_relationship(self, user_id: int, data=None, **kwargs):
|
|
||||||
# 检查是否在内存中已存在
|
# 检查是否在内存中已存在
|
||||||
relationship = self.relationships.get(user_id)
|
relationship = self.relationships.get(key)
|
||||||
if relationship:
|
if relationship:
|
||||||
# 如果存在,更新现有对象
|
# 如果存在,更新现有对象
|
||||||
if isinstance(data, dict):
|
if isinstance(data, dict):
|
||||||
for key, value in data.items():
|
for k, value in data.items():
|
||||||
if hasattr(relationship, key) and value is not None:
|
if hasattr(relationship, k) and value is not None:
|
||||||
setattr(relationship, key, value)
|
setattr(relationship, k, value)
|
||||||
else:
|
|
||||||
for key, value in kwargs.items():
|
|
||||||
if hasattr(relationship, key) and value is not None:
|
|
||||||
setattr(relationship, key, value)
|
|
||||||
else:
|
else:
|
||||||
# 如果不存在,创建新对象
|
# 如果不存在,创建新对象
|
||||||
relationship = Relationship(user_id, data=data) if isinstance(data, dict) else Relationship(user_id, **kwargs)
|
if chat_stream.user_info is not None:
|
||||||
self.relationships[user_id] = relationship
|
relationship = Relationship(chat=chat_stream, **kwargs)
|
||||||
|
else:
|
||||||
# 更新 id_name_nickname_table
|
raise ValueError("必须提供user_id或user_info")
|
||||||
# self.id_name_nickname_table[user_id] = [relationship.nickname] # 别称设置为空列表
|
self.relationships[key] = relationship
|
||||||
|
|
||||||
# 保存到数据库
|
# 保存到数据库
|
||||||
await self.storage_relationship(relationship)
|
await self.storage_relationship(relationship)
|
||||||
@@ -74,82 +83,130 @@ class RelationshipManager:
|
|||||||
|
|
||||||
return relationship
|
return relationship
|
||||||
|
|
||||||
async def update_relationship_value(self, user_id: int, **kwargs):
|
async def update_relationship_value(self,
|
||||||
|
chat_stream:ChatStream,
|
||||||
|
**kwargs) -> Optional[Relationship]:
|
||||||
|
"""更新关系值
|
||||||
|
Args:
|
||||||
|
user_id: 用户ID(可选,如果提供user_info则不需要)
|
||||||
|
platform: 平台(可选,如果提供user_info则不需要)
|
||||||
|
user_info: 用户信息对象(可选)
|
||||||
|
**kwargs: 其他参数
|
||||||
|
Returns:
|
||||||
|
Relationship: 关系对象
|
||||||
|
"""
|
||||||
|
# 确定user_id和platform
|
||||||
|
user_info = chat_stream.user_info
|
||||||
|
if user_info is not None:
|
||||||
|
user_id = user_info.user_id
|
||||||
|
platform = user_info.platform or 'qq'
|
||||||
|
else:
|
||||||
|
platform = platform or 'qq'
|
||||||
|
|
||||||
|
if user_id is None:
|
||||||
|
raise ValueError("必须提供user_id或user_info")
|
||||||
|
|
||||||
|
# 使用(user_id, platform)作为键
|
||||||
|
key = (user_id, platform)
|
||||||
|
|
||||||
# 检查是否在内存中已存在
|
# 检查是否在内存中已存在
|
||||||
relationship = self.relationships.get(user_id)
|
relationship = self.relationships.get(key)
|
||||||
if relationship:
|
if relationship:
|
||||||
for key, value in kwargs.items():
|
for k, value in kwargs.items():
|
||||||
if key == 'relationship_value':
|
if k == 'relationship_value':
|
||||||
relationship.relationship_value += value
|
relationship.relationship_value += value
|
||||||
await self.storage_relationship(relationship)
|
await self.storage_relationship(relationship)
|
||||||
relationship.saved = True
|
relationship.saved = True
|
||||||
return relationship
|
return relationship
|
||||||
else:
|
else:
|
||||||
print(f"\033[1;31m[关系管理]\033[0m 用户 {user_id} 不存在,无法更新")
|
# 如果不存在且提供了user_info,则创建新的关系
|
||||||
|
if user_info is not None:
|
||||||
|
return await self.update_relationship(chat_stream=chat_stream, **kwargs)
|
||||||
|
logger.warning(f"[关系管理] 用户 {user_id}({platform}) 不存在,无法更新")
|
||||||
return None
|
return None
|
||||||
|
|
||||||
|
def get_relationship(self,
|
||||||
|
chat_stream:ChatStream) -> Optional[Relationship]:
|
||||||
|
"""获取用户关系对象
|
||||||
|
Args:
|
||||||
|
user_id: 用户ID(可选,如果提供user_info则不需要)
|
||||||
|
platform: 平台(可选,如果提供user_info则不需要)
|
||||||
|
user_info: 用户信息对象(可选)
|
||||||
|
Returns:
|
||||||
|
Relationship: 关系对象
|
||||||
|
"""
|
||||||
|
# 确定user_id和platform
|
||||||
|
user_info = chat_stream.user_info
|
||||||
|
platform = chat_stream.user_info.platform or 'qq'
|
||||||
|
if user_info is not None:
|
||||||
|
user_id = user_info.user_id
|
||||||
|
platform = user_info.platform or 'qq'
|
||||||
|
else:
|
||||||
|
platform = platform or 'qq'
|
||||||
|
|
||||||
def get_relationship(self, user_id: int) -> Optional[Relationship]:
|
if user_id is None:
|
||||||
"""获取用户关系对象"""
|
raise ValueError("必须提供user_id或user_info")
|
||||||
if user_id in self.relationships:
|
|
||||||
return self.relationships[user_id]
|
key = (user_id, platform)
|
||||||
|
if key in self.relationships:
|
||||||
|
return self.relationships[key]
|
||||||
else:
|
else:
|
||||||
return 0
|
return 0
|
||||||
|
|
||||||
async def load_relationship(self, data: dict) -> Relationship:
|
async def load_relationship(self, data: dict) -> Relationship:
|
||||||
"""从数据库加载或创建新的关系对象"""
|
"""从数据库加载或创建新的关系对象"""
|
||||||
rela = Relationship(user_id=data['user_id'], data=data)
|
# 确保data中有platform字段,如果没有则默认为'qq'
|
||||||
|
if 'platform' not in data:
|
||||||
|
data['platform'] = 'qq'
|
||||||
|
|
||||||
|
rela = Relationship(data=data)
|
||||||
rela.saved = True
|
rela.saved = True
|
||||||
self.relationships[rela.user_id] = rela
|
key = (rela.user_id, rela.platform)
|
||||||
|
self.relationships[key] = rela
|
||||||
return rela
|
return rela
|
||||||
|
|
||||||
async def load_all_relationships(self):
|
async def load_all_relationships(self):
|
||||||
"""加载所有关系对象"""
|
"""加载所有关系对象"""
|
||||||
db = Database.get_instance()
|
all_relationships = db.relationships.find({})
|
||||||
all_relationships = db.db.relationships.find({})
|
|
||||||
for data in all_relationships:
|
for data in all_relationships:
|
||||||
await self.load_relationship(data)
|
await self.load_relationship(data)
|
||||||
|
|
||||||
async def _start_relationship_manager(self):
|
async def _start_relationship_manager(self):
|
||||||
"""每5分钟自动保存一次关系数据"""
|
"""每5分钟自动保存一次关系数据"""
|
||||||
db = Database.get_instance()
|
|
||||||
# 获取所有关系记录
|
# 获取所有关系记录
|
||||||
all_relationships = db.db.relationships.find({})
|
all_relationships = db.relationships.find({})
|
||||||
# 依次加载每条记录
|
# 依次加载每条记录
|
||||||
for data in all_relationships:
|
for data in all_relationships:
|
||||||
user_id = data['user_id']
|
await self.load_relationship(data)
|
||||||
relationship = await self.load_relationship(data)
|
logger.debug(f"[关系管理] 已加载 {len(self.relationships)} 条关系记录")
|
||||||
self.relationships[user_id] = relationship
|
|
||||||
print(f"\033[1;32m[关系管理]\033[0m 已加载 {len(self.relationships)} 条关系记录")
|
|
||||||
|
|
||||||
while True:
|
while True:
|
||||||
print("\033[1;32m[关系管理]\033[0m 正在自动保存关系")
|
logger.debug("正在自动保存关系")
|
||||||
await asyncio.sleep(300) # 等待300秒(5分钟)
|
await asyncio.sleep(300) # 等待300秒(5分钟)
|
||||||
await self._save_all_relationships()
|
await self._save_all_relationships()
|
||||||
|
|
||||||
async def _save_all_relationships(self):
|
async def _save_all_relationships(self):
|
||||||
"""将所有关系数据保存到数据库"""
|
"""将所有关系数据保存到数据库"""
|
||||||
# 保存所有关系数据
|
# 保存所有关系数据
|
||||||
for userid, relationship in self.relationships.items():
|
for (userid, platform), relationship in self.relationships.items():
|
||||||
if not relationship.saved:
|
if not relationship.saved:
|
||||||
relationship.saved = True
|
relationship.saved = True
|
||||||
await self.storage_relationship(relationship)
|
await self.storage_relationship(relationship)
|
||||||
|
|
||||||
async def storage_relationship(self,relationship: Relationship):
|
async def storage_relationship(self, relationship: Relationship):
|
||||||
"""
|
"""将关系记录存储到数据库中"""
|
||||||
将关系记录存储到数据库中
|
|
||||||
"""
|
|
||||||
user_id = relationship.user_id
|
user_id = relationship.user_id
|
||||||
|
platform = relationship.platform
|
||||||
nickname = relationship.nickname
|
nickname = relationship.nickname
|
||||||
relationship_value = relationship.relationship_value
|
relationship_value = relationship.relationship_value
|
||||||
gender = relationship.gender
|
gender = relationship.gender
|
||||||
age = relationship.age
|
age = relationship.age
|
||||||
saved = relationship.saved
|
saved = relationship.saved
|
||||||
|
|
||||||
db = Database.get_instance()
|
db.relationships.update_one(
|
||||||
db.db.relationships.update_one(
|
{'user_id': user_id, 'platform': platform},
|
||||||
{'user_id': user_id},
|
|
||||||
{'$set': {
|
{'$set': {
|
||||||
|
'platform': platform,
|
||||||
'nickname': nickname,
|
'nickname': nickname,
|
||||||
'relationship_value': relationship_value,
|
'relationship_value': relationship_value,
|
||||||
'gender': gender,
|
'gender': gender,
|
||||||
@@ -159,12 +216,36 @@ class RelationshipManager:
|
|||||||
upsert=True
|
upsert=True
|
||||||
)
|
)
|
||||||
|
|
||||||
def get_name(self, user_id: int) -> str:
|
|
||||||
|
def get_name(self,
|
||||||
|
user_id: int = None,
|
||||||
|
platform: str = None,
|
||||||
|
user_info: UserInfo = None) -> str:
|
||||||
|
"""获取用户昵称
|
||||||
|
Args:
|
||||||
|
user_id: 用户ID(可选,如果提供user_info则不需要)
|
||||||
|
platform: 平台(可选,如果提供user_info则不需要)
|
||||||
|
user_info: 用户信息对象(可选)
|
||||||
|
Returns:
|
||||||
|
str: 用户昵称
|
||||||
|
"""
|
||||||
|
# 确定user_id和platform
|
||||||
|
if user_info is not None:
|
||||||
|
user_id = user_info.user_id
|
||||||
|
platform = user_info.platform or 'qq'
|
||||||
|
else:
|
||||||
|
platform = platform or 'qq'
|
||||||
|
|
||||||
|
if user_id is None:
|
||||||
|
raise ValueError("必须提供user_id或user_info")
|
||||||
|
|
||||||
# 确保user_id是整数类型
|
# 确保user_id是整数类型
|
||||||
user_id = int(user_id)
|
user_id = int(user_id)
|
||||||
if user_id in self.relationships:
|
key = (user_id, platform)
|
||||||
|
if key in self.relationships:
|
||||||
return self.relationships[user_id].nickname
|
return self.relationships[key].nickname
|
||||||
|
elif user_info is not None:
|
||||||
|
return user_info.user_nickname or user_info.user_cardname or "某人"
|
||||||
else:
|
else:
|
||||||
return "某人"
|
return "某人"
|
||||||
|
|
||||||
|
|||||||
@@ -1,49 +1,27 @@
|
|||||||
from typing import Optional
|
from typing import Optional, Union
|
||||||
|
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
from .message import Message
|
from .message import MessageSending, MessageRecv
|
||||||
|
from .chat_stream import ChatStream
|
||||||
|
from loguru import logger
|
||||||
|
|
||||||
|
|
||||||
class MessageStorage:
|
class MessageStorage:
|
||||||
def __init__(self):
|
async def store_message(self, message: Union[MessageSending, MessageRecv],chat_stream:ChatStream, topic: Optional[str] = None) -> None:
|
||||||
self.db = Database.get_instance()
|
|
||||||
|
|
||||||
async def store_message(self, message: Message, topic: Optional[str] = None) -> None:
|
|
||||||
"""存储消息到数据库"""
|
"""存储消息到数据库"""
|
||||||
try:
|
try:
|
||||||
if not message.is_emoji:
|
|
||||||
message_data = {
|
message_data = {
|
||||||
"group_id": message.group_id,
|
"message_id": message.message_info.message_id,
|
||||||
"user_id": message.user_id,
|
"time": message.message_info.time,
|
||||||
"message_id": message.message_id,
|
"chat_id":chat_stream.stream_id,
|
||||||
"raw_message": message.raw_message,
|
"chat_info": chat_stream.to_dict(),
|
||||||
"plain_text": message.plain_text,
|
"user_info": message.message_info.user_info.to_dict(),
|
||||||
"processed_plain_text": message.processed_plain_text,
|
"processed_plain_text": message.processed_plain_text,
|
||||||
"time": message.time,
|
|
||||||
"user_nickname": message.user_nickname,
|
|
||||||
"user_cardname": message.user_cardname,
|
|
||||||
"group_name": message.group_name,
|
|
||||||
"topic": topic,
|
|
||||||
"detailed_plain_text": message.detailed_plain_text,
|
"detailed_plain_text": message.detailed_plain_text,
|
||||||
}
|
|
||||||
else:
|
|
||||||
message_data = {
|
|
||||||
"group_id": message.group_id,
|
|
||||||
"user_id": message.user_id,
|
|
||||||
"message_id": message.message_id,
|
|
||||||
"raw_message": message.raw_message,
|
|
||||||
"plain_text": message.plain_text,
|
|
||||||
"processed_plain_text": '[表情包]',
|
|
||||||
"time": message.time,
|
|
||||||
"user_nickname": message.user_nickname,
|
|
||||||
"user_cardname": message.user_cardname,
|
|
||||||
"group_name": message.group_name,
|
|
||||||
"topic": topic,
|
"topic": topic,
|
||||||
"detailed_plain_text": message.detailed_plain_text,
|
|
||||||
}
|
}
|
||||||
|
db.messages.insert_one(message_data)
|
||||||
self.db.db.messages.insert_one(message_data)
|
except Exception:
|
||||||
except Exception as e:
|
logger.exception("存储消息失败")
|
||||||
print(f"\033[1;31m[错误]\033[0m 存储消息失败: {e}")
|
|
||||||
|
|
||||||
# 如果需要其他存储相关的函数,可以在这里添加
|
# 如果需要其他存储相关的函数,可以在这里添加
|
||||||
@@ -4,10 +4,12 @@ from nonebot import get_driver
|
|||||||
|
|
||||||
from ..models.utils_model import LLM_request
|
from ..models.utils_model import LLM_request
|
||||||
from .config import global_config
|
from .config import global_config
|
||||||
|
from loguru import logger
|
||||||
|
|
||||||
driver = get_driver()
|
driver = get_driver()
|
||||||
config = driver.config
|
config = driver.config
|
||||||
|
|
||||||
|
|
||||||
class TopicIdentifier:
|
class TopicIdentifier:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.llm_topic_judge = LLM_request(model=global_config.llm_topic_judge)
|
self.llm_topic_judge = LLM_request(model=global_config.llm_topic_judge)
|
||||||
@@ -25,7 +27,7 @@ class TopicIdentifier:
|
|||||||
topic, _ = await self.llm_topic_judge.generate_response(prompt)
|
topic, _ = await self.llm_topic_judge.generate_response(prompt)
|
||||||
|
|
||||||
if not topic:
|
if not topic:
|
||||||
print("\033[1;31m[错误]\033[0m LLM API 返回为空")
|
logger.error("LLM API 返回为空")
|
||||||
return None
|
return None
|
||||||
|
|
||||||
# 直接在这里处理主题解析
|
# 直接在这里处理主题解析
|
||||||
@@ -35,7 +37,8 @@ class TopicIdentifier:
|
|||||||
# 解析主题字符串为列表
|
# 解析主题字符串为列表
|
||||||
topic_list = [t.strip() for t in topic.split(",") if t.strip()]
|
topic_list = [t.strip() for t in topic.split(",") if t.strip()]
|
||||||
|
|
||||||
print(f"\033[1;32m[主题识别]\033[0m 主题: {topic_list}")
|
logger.info(f"主题: {topic_list}")
|
||||||
return topic_list if topic_list else None
|
return topic_list if topic_list else None
|
||||||
|
|
||||||
|
|
||||||
topic_identifier = TopicIdentifier()
|
topic_identifier = TopicIdentifier()
|
||||||
@@ -7,39 +7,24 @@ from typing import Dict, List
|
|||||||
import jieba
|
import jieba
|
||||||
import numpy as np
|
import numpy as np
|
||||||
from nonebot import get_driver
|
from nonebot import get_driver
|
||||||
|
from loguru import logger
|
||||||
|
|
||||||
from ..models.utils_model import LLM_request
|
from ..models.utils_model import LLM_request
|
||||||
from ..utils.typo_generator import ChineseTypoGenerator
|
from ..utils.typo_generator import ChineseTypoGenerator
|
||||||
from .config import global_config
|
from .config import global_config
|
||||||
from .message import Message
|
from .message import MessageRecv,Message
|
||||||
|
from .message_base import UserInfo
|
||||||
|
from .chat_stream import ChatStream
|
||||||
from ..moods.moods import MoodManager
|
from ..moods.moods import MoodManager
|
||||||
|
from ...common.database import db
|
||||||
|
|
||||||
driver = get_driver()
|
driver = get_driver()
|
||||||
config = driver.config
|
config = driver.config
|
||||||
|
|
||||||
|
|
||||||
def combine_messages(messages: List[Message]) -> str:
|
|
||||||
"""将消息列表组合成格式化的字符串
|
|
||||||
|
|
||||||
Args:
|
|
||||||
messages: Message对象列表
|
|
||||||
|
|
||||||
Returns:
|
|
||||||
str: 格式化后的消息字符串
|
|
||||||
"""
|
|
||||||
result = ""
|
|
||||||
for message in messages:
|
|
||||||
time_str = time.strftime("%m-%d %H:%M:%S", time.localtime(message.time))
|
|
||||||
name = message.user_nickname or f"用户{message.user_id}"
|
|
||||||
content = message.processed_plain_text or message.plain_text
|
|
||||||
|
|
||||||
result += f"[{time_str}] {name}: {content}\n"
|
|
||||||
|
|
||||||
return result
|
|
||||||
|
|
||||||
|
|
||||||
def db_message_to_str(message_dict: Dict) -> str:
|
def db_message_to_str(message_dict: Dict) -> str:
|
||||||
print(f"message_dict: {message_dict}")
|
logger.debug(f"message_dict: {message_dict}")
|
||||||
time_str = time.strftime("%m-%d %H:%M:%S", time.localtime(message_dict["time"]))
|
time_str = time.strftime("%m-%d %H:%M:%S", time.localtime(message_dict["time"]))
|
||||||
try:
|
try:
|
||||||
name = "[(%s)%s]%s" % (
|
name = "[(%s)%s]%s" % (
|
||||||
@@ -48,24 +33,19 @@ def db_message_to_str(message_dict: Dict) -> str:
|
|||||||
name = message_dict.get("user_nickname", "") or f"用户{message_dict['user_id']}"
|
name = message_dict.get("user_nickname", "") or f"用户{message_dict['user_id']}"
|
||||||
content = message_dict.get("processed_plain_text", "")
|
content = message_dict.get("processed_plain_text", "")
|
||||||
result = f"[{time_str}] {name}: {content}\n"
|
result = f"[{time_str}] {name}: {content}\n"
|
||||||
print(f"result: {result}")
|
logger.debug(f"result: {result}")
|
||||||
return result
|
return result
|
||||||
|
|
||||||
|
|
||||||
def is_mentioned_bot_in_message(message: Message) -> bool:
|
def is_mentioned_bot_in_message(message: MessageRecv) -> bool:
|
||||||
"""检查消息是否提到了机器人"""
|
"""检查消息是否提到了机器人"""
|
||||||
keywords = [global_config.BOT_NICKNAME]
|
keywords = [global_config.BOT_NICKNAME]
|
||||||
|
nicknames = global_config.BOT_ALIAS_NAMES
|
||||||
for keyword in keywords:
|
for keyword in keywords:
|
||||||
if keyword in message.processed_plain_text:
|
if keyword in message.processed_plain_text:
|
||||||
return True
|
return True
|
||||||
return False
|
for nickname in nicknames:
|
||||||
|
if nickname in message.processed_plain_text:
|
||||||
|
|
||||||
def is_mentioned_bot_in_txt(message: str) -> bool:
|
|
||||||
"""检查消息是否提到了机器人"""
|
|
||||||
keywords = [global_config.BOT_NICKNAME]
|
|
||||||
for keyword in keywords:
|
|
||||||
if keyword in message:
|
|
||||||
return True
|
return True
|
||||||
return False
|
return False
|
||||||
|
|
||||||
@@ -97,51 +77,48 @@ def calculate_information_content(text):
|
|||||||
return entropy
|
return entropy
|
||||||
|
|
||||||
|
|
||||||
def get_cloest_chat_from_db(db, length: int, timestamp: str):
|
def get_closest_chat_from_db(length: int, timestamp: str):
|
||||||
"""从数据库中获取最接近指定时间戳的聊天记录,并记录读取次数
|
"""从数据库中获取最接近指定时间戳的聊天记录
|
||||||
|
|
||||||
|
Args:
|
||||||
|
length: 要获取的消息数量
|
||||||
|
timestamp: 时间戳
|
||||||
|
|
||||||
Returns:
|
Returns:
|
||||||
list: 消息记录字典列表,每个字典包含消息内容和时间信息
|
list: 消息记录列表,每个记录包含时间和文本信息
|
||||||
"""
|
"""
|
||||||
chat_records = []
|
chat_records = []
|
||||||
closest_record = db.db.messages.find_one({"time": {"$lte": timestamp}}, sort=[('time', -1)])
|
closest_record = db.messages.find_one({"time": {"$lte": timestamp}}, sort=[('time', -1)])
|
||||||
|
|
||||||
if closest_record and closest_record.get('memorized', 0) < 4:
|
if closest_record:
|
||||||
closest_time = closest_record['time']
|
closest_time = closest_record['time']
|
||||||
group_id = closest_record['group_id']
|
chat_id = closest_record['chat_id'] # 获取chat_id
|
||||||
# 获取该时间戳之后的length条消息,且groupid相同
|
# 获取该时间戳之后的length条消息,保持相同的chat_id
|
||||||
records = list(db.db.messages.find(
|
chat_records = list(db.messages.find(
|
||||||
{"time": {"$gt": closest_time}, "group_id": group_id}
|
{
|
||||||
|
"time": {"$gt": closest_time},
|
||||||
|
"chat_id": chat_id # 添加chat_id过滤
|
||||||
|
}
|
||||||
).sort('time', 1).limit(length))
|
).sort('time', 1).limit(length))
|
||||||
|
|
||||||
# 更新每条消息的memorized属性
|
# 转换记录格式
|
||||||
for record in records:
|
formatted_records = []
|
||||||
current_memorized = record.get('memorized', 0)
|
for record in chat_records:
|
||||||
if current_memorized > 3:
|
formatted_records.append({
|
||||||
print("消息已读取3次,跳过")
|
|
||||||
return ''
|
|
||||||
|
|
||||||
# 更新memorized值
|
|
||||||
db.db.messages.update_one(
|
|
||||||
{"_id": record["_id"]},
|
|
||||||
{"$set": {"memorized": current_memorized + 1}}
|
|
||||||
)
|
|
||||||
|
|
||||||
# 添加到记录列表中
|
|
||||||
chat_records.append({
|
|
||||||
'text': record["detailed_plain_text"],
|
|
||||||
'time': record["time"],
|
'time': record["time"],
|
||||||
'group_id': record["group_id"]
|
'chat_id': record["chat_id"],
|
||||||
|
'detailed_plain_text': record.get("detailed_plain_text", "") # 添加文本内容
|
||||||
})
|
})
|
||||||
|
|
||||||
return chat_records
|
return formatted_records
|
||||||
|
|
||||||
|
return []
|
||||||
|
|
||||||
|
|
||||||
async def get_recent_group_messages(db, group_id: int, limit: int = 12) -> list:
|
async def get_recent_group_messages(chat_id:str, limit: int = 12) -> list:
|
||||||
"""从数据库获取群组最近的消息记录
|
"""从数据库获取群组最近的消息记录
|
||||||
|
|
||||||
Args:
|
Args:
|
||||||
db: Database实例
|
|
||||||
group_id: 群组ID
|
group_id: 群组ID
|
||||||
limit: 获取消息数量,默认12条
|
limit: 获取消息数量,默认12条
|
||||||
|
|
||||||
@@ -150,39 +127,32 @@ async def get_recent_group_messages(db, group_id: int, limit: int = 12) -> list:
|
|||||||
"""
|
"""
|
||||||
|
|
||||||
# 从数据库获取最近消息
|
# 从数据库获取最近消息
|
||||||
recent_messages = list(db.db.messages.find(
|
recent_messages = list(db.messages.find(
|
||||||
{"group_id": group_id},
|
{"chat_id": chat_id},
|
||||||
# {
|
|
||||||
# "time": 1,
|
|
||||||
# "user_id": 1,
|
|
||||||
# "user_nickname": 1,
|
|
||||||
# "message_id": 1,
|
|
||||||
# "raw_message": 1,
|
|
||||||
# "processed_text": 1
|
|
||||||
# }
|
|
||||||
).sort("time", -1).limit(limit))
|
).sort("time", -1).limit(limit))
|
||||||
|
|
||||||
if not recent_messages:
|
if not recent_messages:
|
||||||
return []
|
return []
|
||||||
|
|
||||||
# 转换为 Message对象列表
|
# 转换为 Message对象列表
|
||||||
from .message import Message
|
|
||||||
message_objects = []
|
message_objects = []
|
||||||
for msg_data in recent_messages:
|
for msg_data in recent_messages:
|
||||||
try:
|
try:
|
||||||
|
chat_info=msg_data.get("chat_info",{})
|
||||||
|
chat_stream=ChatStream.from_dict(chat_info)
|
||||||
|
user_info=msg_data.get("user_info",{})
|
||||||
|
user_info=UserInfo.from_dict(user_info)
|
||||||
msg = Message(
|
msg = Message(
|
||||||
time=msg_data["time"],
|
|
||||||
user_id=msg_data["user_id"],
|
|
||||||
user_nickname=msg_data.get("user_nickname", ""),
|
|
||||||
message_id=msg_data["message_id"],
|
message_id=msg_data["message_id"],
|
||||||
raw_message=msg_data["raw_message"],
|
chat_stream=chat_stream,
|
||||||
|
time=msg_data["time"],
|
||||||
|
user_info=user_info,
|
||||||
processed_plain_text=msg_data.get("processed_text", ""),
|
processed_plain_text=msg_data.get("processed_text", ""),
|
||||||
group_id=group_id
|
detailed_plain_text=msg_data.get("detailed_plain_text", "")
|
||||||
)
|
)
|
||||||
await msg.initialize()
|
|
||||||
message_objects.append(msg)
|
message_objects.append(msg)
|
||||||
except KeyError:
|
except KeyError:
|
||||||
print("[WARNING] 数据库中存在无效的消息")
|
logger.warning("数据库中存在无效的消息")
|
||||||
continue
|
continue
|
||||||
|
|
||||||
# 按时间正序排列
|
# 按时间正序排列
|
||||||
@@ -190,13 +160,14 @@ async def get_recent_group_messages(db, group_id: int, limit: int = 12) -> list:
|
|||||||
return message_objects
|
return message_objects
|
||||||
|
|
||||||
|
|
||||||
def get_recent_group_detailed_plain_text(db, group_id: int, limit: int = 12, combine=False):
|
def get_recent_group_detailed_plain_text(chat_stream_id: int, limit: int = 12, combine=False):
|
||||||
recent_messages = list(db.db.messages.find(
|
recent_messages = list(db.messages.find(
|
||||||
{"group_id": group_id},
|
{"chat_id": chat_stream_id},
|
||||||
{
|
{
|
||||||
"time": 1, # 返回时间字段
|
"time": 1, # 返回时间字段
|
||||||
"user_id": 1, # 返回用户ID字段
|
"chat_id":1,
|
||||||
"user_nickname": 1, # 返回用户昵称字段
|
"chat_info":1,
|
||||||
|
"user_info": 1,
|
||||||
"message_id": 1, # 返回消息ID字段
|
"message_id": 1, # 返回消息ID字段
|
||||||
"detailed_plain_text": 1 # 返回处理后的文本字段
|
"detailed_plain_text": 1 # 返回处理后的文本字段
|
||||||
}
|
}
|
||||||
@@ -298,11 +269,10 @@ def split_into_sentences_w_remove_punctuation(text: str) -> List[str]:
|
|||||||
sentence = sentence.replace(',', ' ').replace(',', ' ')
|
sentence = sentence.replace(',', ' ').replace(',', ' ')
|
||||||
sentences_done.append(sentence)
|
sentences_done.append(sentence)
|
||||||
|
|
||||||
print(f"处理后的句子: {sentences_done}")
|
logger.info(f"处理后的句子: {sentences_done}")
|
||||||
return sentences_done
|
return sentences_done
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
def random_remove_punctuation(text: str) -> str:
|
def random_remove_punctuation(text: str) -> str:
|
||||||
"""随机处理标点符号,模拟人类打字习惯
|
"""随机处理标点符号,模拟人类打字习惯
|
||||||
|
|
||||||
@@ -330,11 +300,10 @@ def random_remove_punctuation(text: str) -> str:
|
|||||||
return result
|
return result
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
def process_llm_response(text: str) -> List[str]:
|
def process_llm_response(text: str) -> List[str]:
|
||||||
# processed_response = process_text_with_typos(content)
|
# processed_response = process_text_with_typos(content)
|
||||||
if len(text) > 200:
|
if len(text) > 200:
|
||||||
print(f"回复过长 ({len(text)} 字符),返回默认回复")
|
logger.warning(f"回复过长 ({len(text)} 字符),返回默认回复")
|
||||||
return ['懒得说']
|
return ['懒得说']
|
||||||
# 处理长消息
|
# 处理长消息
|
||||||
typo_generator = ChineseTypoGenerator(
|
typo_generator = ChineseTypoGenerator(
|
||||||
@@ -356,7 +325,7 @@ def process_llm_response(text: str) -> List[str]:
|
|||||||
# 检查分割后的消息数量是否过多(超过3条)
|
# 检查分割后的消息数量是否过多(超过3条)
|
||||||
|
|
||||||
if len(sentences) > 5:
|
if len(sentences) > 5:
|
||||||
print(f"分割后消息数量过多 ({len(sentences)} 条),返回默认回复")
|
logger.warning(f"分割后消息数量过多 ({len(sentences)} 条),返回默认回复")
|
||||||
return [f'{global_config.BOT_NICKNAME}不知道哦']
|
return [f'{global_config.BOT_NICKNAME}不知道哦']
|
||||||
|
|
||||||
return sentences
|
return sentences
|
||||||
@@ -378,8 +347,8 @@ def calculate_typing_time(input_string: str, chinese_time: float = 0.4, english_
|
|||||||
mood_arousal = mood_manager.current_mood.arousal
|
mood_arousal = mood_manager.current_mood.arousal
|
||||||
# 映射到0.5到2倍的速度系数
|
# 映射到0.5到2倍的速度系数
|
||||||
typing_speed_multiplier = 1.5 ** mood_arousal # 唤醒度为1时速度翻倍,为-1时速度减半
|
typing_speed_multiplier = 1.5 ** mood_arousal # 唤醒度为1时速度翻倍,为-1时速度减半
|
||||||
chinese_time *= 1/typing_speed_multiplier
|
chinese_time *= 1 / typing_speed_multiplier
|
||||||
english_time *= 1/typing_speed_multiplier
|
english_time *= 1 / typing_speed_multiplier
|
||||||
# 计算中文字符数
|
# 计算中文字符数
|
||||||
chinese_chars = sum(1 for char in input_string if '\u4e00' <= char <= '\u9fff')
|
chinese_chars = sum(1 for char in input_string if '\u4e00' <= char <= '\u9fff')
|
||||||
|
|
||||||
@@ -436,3 +405,10 @@ def find_similar_topics_simple(text: str, topics: list, top_k: int = 5) -> list:
|
|||||||
|
|
||||||
# 按相似度降序排序并返回前k个
|
# 按相似度降序排序并返回前k个
|
||||||
return sorted(similarities, key=lambda x: x[1], reverse=True)[:top_k]
|
return sorted(similarities, key=lambda x: x[1], reverse=True)[:top_k]
|
||||||
|
|
||||||
|
|
||||||
|
def truncate_message(message: str, max_length=20) -> str:
|
||||||
|
"""截断消息,使其不超过指定长度"""
|
||||||
|
if len(message) > max_length:
|
||||||
|
return message[:max_length] + "..."
|
||||||
|
return message
|
||||||
|
|||||||
@@ -1,296 +1,232 @@
|
|||||||
import base64
|
import base64
|
||||||
import io
|
|
||||||
import os
|
import os
|
||||||
import time
|
import time
|
||||||
import zlib # 用于 CRC32
|
import aiohttp
|
||||||
|
import hashlib
|
||||||
|
from typing import Optional, Union
|
||||||
|
from PIL import Image
|
||||||
|
import io
|
||||||
|
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
from nonebot import get_driver
|
from nonebot import get_driver
|
||||||
from PIL import Image
|
|
||||||
|
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
from ..chat.config import global_config
|
from ..chat.config import global_config
|
||||||
|
from ..models.utils_model import LLM_request
|
||||||
|
|
||||||
driver = get_driver()
|
driver = get_driver()
|
||||||
config = driver.config
|
config = driver.config
|
||||||
|
|
||||||
|
|
||||||
|
class ImageManager:
|
||||||
|
_instance = None
|
||||||
|
IMAGE_DIR = "data" # 图像存储根目录
|
||||||
|
|
||||||
|
def __new__(cls):
|
||||||
|
if cls._instance is None:
|
||||||
|
cls._instance = super().__new__(cls)
|
||||||
|
cls._instance._initialized = False
|
||||||
|
return cls._instance
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
if not self._initialized:
|
||||||
|
self._ensure_image_collection()
|
||||||
|
self._ensure_description_collection()
|
||||||
|
self._ensure_image_dir()
|
||||||
|
self._initialized = True
|
||||||
|
self._llm = LLM_request(model=global_config.vlm, temperature=0.4, max_tokens=300)
|
||||||
|
|
||||||
|
def _ensure_image_dir(self):
|
||||||
|
"""确保图像存储目录存在"""
|
||||||
|
os.makedirs(self.IMAGE_DIR, exist_ok=True)
|
||||||
|
|
||||||
|
def _ensure_image_collection(self):
|
||||||
|
"""确保images集合存在并创建索引"""
|
||||||
|
if "images" not in db.list_collection_names():
|
||||||
|
db.create_collection("images")
|
||||||
|
|
||||||
|
# 删除旧索引
|
||||||
|
db.images.drop_indexes()
|
||||||
|
# 创建新的复合索引
|
||||||
|
db.images.create_index([("hash", 1), ("type", 1)], unique=True)
|
||||||
|
db.images.create_index([("url", 1)])
|
||||||
|
db.images.create_index([("path", 1)])
|
||||||
|
|
||||||
|
def _ensure_description_collection(self):
|
||||||
|
"""确保image_descriptions集合存在并创建索引"""
|
||||||
|
if "image_descriptions" not in db.list_collection_names():
|
||||||
|
db.create_collection("image_descriptions")
|
||||||
|
|
||||||
|
# 删除旧索引
|
||||||
|
db.image_descriptions.drop_indexes()
|
||||||
|
# 创建新的复合索引
|
||||||
|
db.image_descriptions.create_index([("hash", 1), ("type", 1)], unique=True)
|
||||||
|
|
||||||
|
def _get_description_from_db(self, image_hash: str, description_type: str) -> Optional[str]:
|
||||||
|
"""从数据库获取图片描述
|
||||||
|
|
||||||
def storage_compress_image(base64_data: str, max_size: int = 200) -> str:
|
|
||||||
"""
|
|
||||||
压缩base64格式的图片到指定大小(单位:KB)并在数据库中记录图片信息
|
|
||||||
Args:
|
Args:
|
||||||
base64_data: base64编码的图片数据
|
image_hash: 图片哈希值
|
||||||
max_size: 最大文件大小(KB)
|
description_type: 描述类型 ('emoji' 或 'image')
|
||||||
|
|
||||||
Returns:
|
Returns:
|
||||||
str: 压缩后的base64图片数据
|
Optional[str]: 描述文本,如果不存在则返回None
|
||||||
|
"""
|
||||||
|
result = db.image_descriptions.find_one({"hash": image_hash, "type": description_type})
|
||||||
|
return result["description"] if result else None
|
||||||
|
|
||||||
|
def _save_description_to_db(self, image_hash: str, description: str, description_type: str) -> None:
|
||||||
|
"""保存图片描述到数据库
|
||||||
|
|
||||||
|
Args:
|
||||||
|
image_hash: 图片哈希值
|
||||||
|
description: 描述文本
|
||||||
|
description_type: 描述类型 ('emoji' 或 'image')
|
||||||
"""
|
"""
|
||||||
try:
|
try:
|
||||||
# 将base64转换为字节数据
|
db.image_descriptions.update_one(
|
||||||
image_data = base64.b64decode(base64_data)
|
{"hash": image_hash, "type": description_type},
|
||||||
|
{
|
||||||
# 使用 CRC32 计算哈希值
|
"$set": {
|
||||||
hash_value = format(zlib.crc32(image_data) & 0xFFFFFFFF, 'x')
|
"description": description,
|
||||||
|
"timestamp": int(time.time()),
|
||||||
# 确保图片目录存在
|
"hash": image_hash, # 确保hash字段存在
|
||||||
images_dir = "data/images"
|
"type": description_type, # 确保type字段存在
|
||||||
os.makedirs(images_dir, exist_ok=True)
|
|
||||||
|
|
||||||
# 连接数据库
|
|
||||||
db = Database(
|
|
||||||
host=config.mongodb_host,
|
|
||||||
port=int(config.mongodb_port),
|
|
||||||
db_name=config.database_name,
|
|
||||||
username=config.mongodb_username,
|
|
||||||
password=config.mongodb_password,
|
|
||||||
auth_source=config.mongodb_auth_source
|
|
||||||
)
|
|
||||||
|
|
||||||
# 检查是否已存在相同哈希值的图片
|
|
||||||
collection = db.db['images']
|
|
||||||
existing_image = collection.find_one({'hash': hash_value})
|
|
||||||
|
|
||||||
if existing_image:
|
|
||||||
print(f"\033[1;33m[提示]\033[0m 发现重复图片,使用已存在的文件: {existing_image['path']}")
|
|
||||||
return base64_data
|
|
||||||
|
|
||||||
# 将字节数据转换为图片对象
|
|
||||||
img = Image.open(io.BytesIO(image_data))
|
|
||||||
|
|
||||||
# 如果是动图,直接返回原图
|
|
||||||
if getattr(img, 'is_animated', False):
|
|
||||||
return base64_data
|
|
||||||
|
|
||||||
# 计算当前大小(KB)
|
|
||||||
current_size = len(image_data) / 1024
|
|
||||||
|
|
||||||
# 如果已经小于目标大小,直接使用原图
|
|
||||||
if current_size <= max_size:
|
|
||||||
compressed_data = image_data
|
|
||||||
else:
|
|
||||||
# 压缩逻辑
|
|
||||||
# 先缩放到50%
|
|
||||||
new_width = int(img.width * 0.5)
|
|
||||||
new_height = int(img.height * 0.5)
|
|
||||||
img = img.resize((new_width, new_height), Image.Resampling.LANCZOS)
|
|
||||||
|
|
||||||
# 如果缩放后的最大边长仍然大于400,继续缩放
|
|
||||||
max_dimension = 400
|
|
||||||
max_current = max(new_width, new_height)
|
|
||||||
if max_current > max_dimension:
|
|
||||||
ratio = max_dimension / max_current
|
|
||||||
new_width = int(new_width * ratio)
|
|
||||||
new_height = int(new_height * ratio)
|
|
||||||
img = img.resize((new_width, new_height), Image.Resampling.LANCZOS)
|
|
||||||
|
|
||||||
# 转换为RGB模式(去除透明通道)
|
|
||||||
if img.mode in ('RGBA', 'P'):
|
|
||||||
img = img.convert('RGB')
|
|
||||||
|
|
||||||
# 使用固定质量参数压缩
|
|
||||||
output = io.BytesIO()
|
|
||||||
img.save(output, format='JPEG', quality=85, optimize=True)
|
|
||||||
compressed_data = output.getvalue()
|
|
||||||
|
|
||||||
# 生成文件名(使用时间戳和哈希值确保唯一性)
|
|
||||||
timestamp = int(time.time())
|
|
||||||
filename = f"{timestamp}_{hash_value}.jpg"
|
|
||||||
image_path = os.path.join(images_dir, filename)
|
|
||||||
|
|
||||||
# 保存文件
|
|
||||||
with open(image_path, "wb") as f:
|
|
||||||
f.write(compressed_data)
|
|
||||||
|
|
||||||
print(f"\033[1;32m[成功]\033[0m 保存图片到: {image_path}")
|
|
||||||
|
|
||||||
try:
|
|
||||||
# 准备数据库记录
|
|
||||||
image_record = {
|
|
||||||
'filename': filename,
|
|
||||||
'path': image_path,
|
|
||||||
'size': len(compressed_data) / 1024,
|
|
||||||
'timestamp': timestamp,
|
|
||||||
'width': img.width,
|
|
||||||
'height': img.height,
|
|
||||||
'description': '',
|
|
||||||
'tags': [],
|
|
||||||
'type': 'image',
|
|
||||||
'hash': hash_value
|
|
||||||
}
|
}
|
||||||
|
},
|
||||||
# 保存记录
|
upsert=True,
|
||||||
collection.insert_one(image_record)
|
|
||||||
print("\033[1;32m[成功]\033[0m 保存图片记录到数据库")
|
|
||||||
|
|
||||||
except Exception as db_error:
|
|
||||||
print(f"\033[1;31m[错误]\033[0m 数据库操作失败: {str(db_error)}")
|
|
||||||
|
|
||||||
# 将压缩后的数据转换为base64
|
|
||||||
compressed_base64 = base64.b64encode(compressed_data).decode('utf-8')
|
|
||||||
return compressed_base64
|
|
||||||
|
|
||||||
except Exception as e:
|
|
||||||
print(f"\033[1;31m[错误]\033[0m 压缩图片失败: {str(e)}")
|
|
||||||
import traceback
|
|
||||||
print(traceback.format_exc())
|
|
||||||
return base64_data
|
|
||||||
|
|
||||||
def storage_emoji(image_data: bytes) -> bytes:
|
|
||||||
"""
|
|
||||||
存储表情包到本地文件夹
|
|
||||||
Args:
|
|
||||||
image_data: 图片字节数据
|
|
||||||
group_id: 群组ID(仅用于日志)
|
|
||||||
user_id: 用户ID(仅用于日志)
|
|
||||||
Returns:
|
|
||||||
bytes: 原始图片数据
|
|
||||||
"""
|
|
||||||
if not global_config.EMOJI_SAVE:
|
|
||||||
return image_data
|
|
||||||
try:
|
|
||||||
# 使用 CRC32 计算哈希值
|
|
||||||
hash_value = format(zlib.crc32(image_data) & 0xFFFFFFFF, 'x')
|
|
||||||
|
|
||||||
# 确保表情包目录存在
|
|
||||||
emoji_dir = "data/emoji"
|
|
||||||
os.makedirs(emoji_dir, exist_ok=True)
|
|
||||||
|
|
||||||
# 检查是否已存在相同哈希值的文件
|
|
||||||
for filename in os.listdir(emoji_dir):
|
|
||||||
if hash_value in filename:
|
|
||||||
# print(f"\033[1;33m[提示]\033[0m 发现重复表情包: {filename}")
|
|
||||||
return image_data
|
|
||||||
|
|
||||||
# 生成文件名
|
|
||||||
timestamp = int(time.time())
|
|
||||||
filename = f"{timestamp}_{hash_value}.jpg"
|
|
||||||
emoji_path = os.path.join(emoji_dir, filename)
|
|
||||||
|
|
||||||
# 直接保存原始文件
|
|
||||||
with open(emoji_path, "wb") as f:
|
|
||||||
f.write(image_data)
|
|
||||||
|
|
||||||
print(f"\033[1;32m[成功]\033[0m 保存表情包到: {emoji_path}")
|
|
||||||
return image_data
|
|
||||||
|
|
||||||
except Exception as e:
|
|
||||||
print(f"\033[1;31m[错误]\033[0m 保存表情包失败: {str(e)}")
|
|
||||||
return image_data
|
|
||||||
|
|
||||||
|
|
||||||
def storage_image(image_data: bytes) -> bytes:
|
|
||||||
"""
|
|
||||||
存储图片到本地文件夹
|
|
||||||
Args:
|
|
||||||
image_data: 图片字节数据
|
|
||||||
group_id: 群组ID(仅用于日志)
|
|
||||||
user_id: 用户ID(仅用于日志)
|
|
||||||
Returns:
|
|
||||||
bytes: 原始图片数据
|
|
||||||
"""
|
|
||||||
try:
|
|
||||||
# 使用 CRC32 计算哈希值
|
|
||||||
hash_value = format(zlib.crc32(image_data) & 0xFFFFFFFF, 'x')
|
|
||||||
|
|
||||||
# 确保表情包目录存在
|
|
||||||
image_dir = "data/image"
|
|
||||||
os.makedirs(image_dir, exist_ok=True)
|
|
||||||
|
|
||||||
# 检查是否已存在相同哈希值的文件
|
|
||||||
for filename in os.listdir(image_dir):
|
|
||||||
if hash_value in filename:
|
|
||||||
# print(f"\033[1;33m[提示]\033[0m 发现重复表情包: {filename}")
|
|
||||||
return image_data
|
|
||||||
|
|
||||||
# 生成文件名
|
|
||||||
timestamp = int(time.time())
|
|
||||||
filename = f"{timestamp}_{hash_value}.jpg"
|
|
||||||
image_path = os.path.join(image_dir, filename)
|
|
||||||
|
|
||||||
# 直接保存原始文件
|
|
||||||
with open(image_path, "wb") as f:
|
|
||||||
f.write(image_data)
|
|
||||||
|
|
||||||
print(f"\033[1;32m[成功]\033[0m 保存图片到: {image_path}")
|
|
||||||
return image_data
|
|
||||||
|
|
||||||
except Exception as e:
|
|
||||||
print(f"\033[1;31m[错误]\033[0m 保存图片失败: {str(e)}")
|
|
||||||
return image_data
|
|
||||||
|
|
||||||
def compress_base64_image_by_scale(base64_data: str, target_size: int = 0.8 * 1024 * 1024) -> str:
|
|
||||||
"""压缩base64格式的图片到指定大小
|
|
||||||
Args:
|
|
||||||
base64_data: base64编码的图片数据
|
|
||||||
target_size: 目标文件大小(字节),默认0.8MB
|
|
||||||
Returns:
|
|
||||||
str: 压缩后的base64图片数据
|
|
||||||
"""
|
|
||||||
try:
|
|
||||||
# 将base64转换为字节数据
|
|
||||||
image_data = base64.b64decode(base64_data)
|
|
||||||
|
|
||||||
# 如果已经小于目标大小,直接返回原图
|
|
||||||
if len(image_data) <= 2*1024*1024:
|
|
||||||
return base64_data
|
|
||||||
|
|
||||||
# 将字节数据转换为图片对象
|
|
||||||
img = Image.open(io.BytesIO(image_data))
|
|
||||||
|
|
||||||
# 获取原始尺寸
|
|
||||||
original_width, original_height = img.size
|
|
||||||
|
|
||||||
# 计算缩放比例
|
|
||||||
scale = min(1.0, (target_size / len(image_data)) ** 0.5)
|
|
||||||
|
|
||||||
# 计算新的尺寸
|
|
||||||
new_width = int(original_width * scale)
|
|
||||||
new_height = int(original_height * scale)
|
|
||||||
|
|
||||||
# 创建内存缓冲区
|
|
||||||
output_buffer = io.BytesIO()
|
|
||||||
|
|
||||||
# 如果是GIF,处理所有帧
|
|
||||||
if getattr(img, "is_animated", False):
|
|
||||||
frames = []
|
|
||||||
for frame_idx in range(img.n_frames):
|
|
||||||
img.seek(frame_idx)
|
|
||||||
new_frame = img.copy()
|
|
||||||
new_frame = new_frame.resize((new_width//2, new_height//2), Image.Resampling.LANCZOS) # 动图折上折
|
|
||||||
frames.append(new_frame)
|
|
||||||
|
|
||||||
# 保存到缓冲区
|
|
||||||
frames[0].save(
|
|
||||||
output_buffer,
|
|
||||||
format='GIF',
|
|
||||||
save_all=True,
|
|
||||||
append_images=frames[1:],
|
|
||||||
optimize=True,
|
|
||||||
duration=img.info.get('duration', 100),
|
|
||||||
loop=img.info.get('loop', 0)
|
|
||||||
)
|
)
|
||||||
else:
|
|
||||||
# 处理静态图片
|
|
||||||
resized_img = img.resize((new_width, new_height), Image.Resampling.LANCZOS)
|
|
||||||
|
|
||||||
# 保存到缓冲区,保持原始格式
|
|
||||||
if img.format == 'PNG' and img.mode in ('RGBA', 'LA'):
|
|
||||||
resized_img.save(output_buffer, format='PNG', optimize=True)
|
|
||||||
else:
|
|
||||||
resized_img.save(output_buffer, format='JPEG', quality=95, optimize=True)
|
|
||||||
|
|
||||||
# 获取压缩后的数据并转换为base64
|
|
||||||
compressed_data = output_buffer.getvalue()
|
|
||||||
logger.success(f"压缩图片: {original_width}x{original_height} -> {new_width}x{new_height}")
|
|
||||||
logger.info(f"压缩前大小: {len(image_data)/1024:.1f}KB, 压缩后大小: {len(compressed_data)/1024:.1f}KB")
|
|
||||||
|
|
||||||
return base64.b64encode(compressed_data).decode('utf-8')
|
|
||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logger.error(f"压缩图片失败: {str(e)}")
|
logger.error(f"保存描述到数据库失败: {str(e)}")
|
||||||
import traceback
|
|
||||||
logger.error(traceback.format_exc())
|
async def get_emoji_description(self, image_base64: str) -> str:
|
||||||
return base64_data
|
"""获取表情包描述,带查重和保存功能"""
|
||||||
|
try:
|
||||||
|
# 计算图片哈希
|
||||||
|
image_bytes = base64.b64decode(image_base64)
|
||||||
|
image_hash = hashlib.md5(image_bytes).hexdigest()
|
||||||
|
image_format = Image.open(io.BytesIO(image_bytes)).format.lower()
|
||||||
|
|
||||||
|
# 查询缓存的描述
|
||||||
|
cached_description = self._get_description_from_db(image_hash, "emoji")
|
||||||
|
if cached_description:
|
||||||
|
logger.info(f"缓存表情包描述: {cached_description}")
|
||||||
|
return f"[表情包:{cached_description}]"
|
||||||
|
|
||||||
|
# 调用AI获取描述
|
||||||
|
prompt = "这是一个表情包,使用中文简洁的描述一下表情包的内容和表情包所表达的情感"
|
||||||
|
description, _ = await self._llm.generate_response_for_image(prompt, image_base64, image_format)
|
||||||
|
|
||||||
|
cached_description = self._get_description_from_db(image_hash, "emoji")
|
||||||
|
if cached_description:
|
||||||
|
logger.warning(f"虽然生成了描述,但是找到缓存表情包描述: {cached_description}")
|
||||||
|
return f"[表情包:{cached_description}]"
|
||||||
|
|
||||||
|
# 根据配置决定是否保存图片
|
||||||
|
if global_config.EMOJI_SAVE:
|
||||||
|
# 生成文件名和路径
|
||||||
|
timestamp = int(time.time())
|
||||||
|
filename = f"{timestamp}_{image_hash[:8]}.{image_format}"
|
||||||
|
if not os.path.exists(os.path.join(self.IMAGE_DIR, "emoji")):
|
||||||
|
os.makedirs(os.path.join(self.IMAGE_DIR, "emoji"))
|
||||||
|
file_path = os.path.join(self.IMAGE_DIR, "emoji", filename)
|
||||||
|
|
||||||
|
try:
|
||||||
|
# 保存文件
|
||||||
|
with open(file_path, "wb") as f:
|
||||||
|
f.write(image_bytes)
|
||||||
|
|
||||||
|
# 保存到数据库
|
||||||
|
image_doc = {
|
||||||
|
"hash": image_hash,
|
||||||
|
"path": file_path,
|
||||||
|
"type": "emoji",
|
||||||
|
"description": description,
|
||||||
|
"timestamp": timestamp,
|
||||||
|
}
|
||||||
|
db.images.update_one({"hash": image_hash}, {"$set": image_doc}, upsert=True)
|
||||||
|
logger.success(f"保存表情包: {file_path}")
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"保存表情包文件失败: {str(e)}")
|
||||||
|
|
||||||
|
# 保存描述到数据库
|
||||||
|
self._save_description_to_db(image_hash, description, "emoji")
|
||||||
|
|
||||||
|
return f"[表情包:{description}]"
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"获取表情包描述失败: {str(e)}")
|
||||||
|
return "[表情包]"
|
||||||
|
|
||||||
|
async def get_image_description(self, image_base64: str) -> str:
|
||||||
|
"""获取普通图片描述,带查重和保存功能"""
|
||||||
|
try:
|
||||||
|
# 计算图片哈希
|
||||||
|
image_bytes = base64.b64decode(image_base64)
|
||||||
|
image_hash = hashlib.md5(image_bytes).hexdigest()
|
||||||
|
image_format = Image.open(io.BytesIO(image_bytes)).format.lower()
|
||||||
|
|
||||||
|
# 查询缓存的描述
|
||||||
|
cached_description = self._get_description_from_db(image_hash, "image")
|
||||||
|
if cached_description:
|
||||||
|
logger.info(f"图片描述缓存中 {cached_description}")
|
||||||
|
return f"[图片:{cached_description}]"
|
||||||
|
|
||||||
|
# 调用AI获取描述
|
||||||
|
prompt = (
|
||||||
|
"请用中文描述这张图片的内容。如果有文字,请把文字都描述出来。并尝试猜测这个图片的含义。最多200个字。"
|
||||||
|
)
|
||||||
|
description, _ = await self._llm.generate_response_for_image(prompt, image_base64, image_format)
|
||||||
|
|
||||||
|
cached_description = self._get_description_from_db(image_hash, "image")
|
||||||
|
if cached_description:
|
||||||
|
logger.warning(f"虽然生成了描述,但是找到缓存图片描述 {cached_description}")
|
||||||
|
return f"[图片:{cached_description}]"
|
||||||
|
|
||||||
|
logger.info(f"描述是{description}")
|
||||||
|
|
||||||
|
if description is None:
|
||||||
|
logger.warning("AI未能生成图片描述")
|
||||||
|
return "[图片]"
|
||||||
|
|
||||||
|
# 根据配置决定是否保存图片
|
||||||
|
if global_config.EMOJI_SAVE:
|
||||||
|
# 生成文件名和路径
|
||||||
|
timestamp = int(time.time())
|
||||||
|
filename = f"{timestamp}_{image_hash[:8]}.{image_format}"
|
||||||
|
if not os.path.exists(os.path.join(self.IMAGE_DIR, "image")):
|
||||||
|
os.makedirs(os.path.join(self.IMAGE_DIR, "image"))
|
||||||
|
file_path = os.path.join(self.IMAGE_DIR, "image", filename)
|
||||||
|
|
||||||
|
try:
|
||||||
|
# 保存文件
|
||||||
|
with open(file_path, "wb") as f:
|
||||||
|
f.write(image_bytes)
|
||||||
|
|
||||||
|
# 保存到数据库
|
||||||
|
image_doc = {
|
||||||
|
"hash": image_hash,
|
||||||
|
"path": file_path,
|
||||||
|
"type": "image",
|
||||||
|
"description": description,
|
||||||
|
"timestamp": timestamp,
|
||||||
|
}
|
||||||
|
db.images.update_one({"hash": image_hash}, {"$set": image_doc}, upsert=True)
|
||||||
|
logger.success(f"保存图片: {file_path}")
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"保存图片文件失败: {str(e)}")
|
||||||
|
|
||||||
|
# 保存描述到数据库
|
||||||
|
self._save_description_to_db(image_hash, description, "image")
|
||||||
|
|
||||||
|
return f"[图片:{description}]"
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"获取图片描述失败: {str(e)}")
|
||||||
|
return "[图片]"
|
||||||
|
|
||||||
|
|
||||||
|
# 创建全局单例
|
||||||
|
image_manager = ImageManager()
|
||||||
|
|
||||||
|
|
||||||
def image_path_to_base64(image_path: str) -> str:
|
def image_path_to_base64(image_path: str) -> str:
|
||||||
"""将图片路径转换为base64编码
|
"""将图片路径转换为base64编码
|
||||||
@@ -300,9 +236,9 @@ def image_path_to_base64(image_path: str) -> str:
|
|||||||
str: base64编码的图片数据
|
str: base64编码的图片数据
|
||||||
"""
|
"""
|
||||||
try:
|
try:
|
||||||
with open(image_path, 'rb') as f:
|
with open(image_path, "rb") as f:
|
||||||
image_data = f.read()
|
image_data = f.read()
|
||||||
return base64.b64encode(image_data).decode('utf-8')
|
return base64.b64encode(image_data).decode("utf-8")
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logger.error(f"读取图片失败: {image_path}, 错误: {str(e)}")
|
logger.error(f"读取图片失败: {image_path}, 错误: {str(e)}")
|
||||||
return None
|
return None
|
||||||
@@ -5,14 +5,16 @@ from .relationship_manager import relationship_manager
|
|||||||
def get_user_nickname(user_id: int) -> str:
|
def get_user_nickname(user_id: int) -> str:
|
||||||
if int(user_id) == int(global_config.BOT_QQ):
|
if int(user_id) == int(global_config.BOT_QQ):
|
||||||
return global_config.BOT_NICKNAME
|
return global_config.BOT_NICKNAME
|
||||||
# print(user_id)
|
# print(user_id)
|
||||||
return relationship_manager.get_name(user_id)
|
return relationship_manager.get_name(user_id)
|
||||||
|
|
||||||
|
|
||||||
def get_user_cardname(user_id: int) -> str:
|
def get_user_cardname(user_id: int) -> str:
|
||||||
if int(user_id) == int(global_config.BOT_QQ):
|
if int(user_id) == int(global_config.BOT_QQ):
|
||||||
return global_config.BOT_NICKNAME
|
return global_config.BOT_NICKNAME
|
||||||
# print(user_id)
|
# print(user_id)
|
||||||
return ''
|
return ""
|
||||||
|
|
||||||
|
|
||||||
def get_groupname(group_id: int) -> str:
|
def get_groupname(group_id: int) -> str:
|
||||||
return f"群{group_id}"
|
return f"群{group_id}"
|
||||||
@@ -1,85 +1,258 @@
|
|||||||
import asyncio
|
import asyncio
|
||||||
|
import random
|
||||||
|
import time
|
||||||
|
from typing import Dict
|
||||||
|
from loguru import logger
|
||||||
|
|
||||||
|
|
||||||
from .config import global_config
|
from .config import global_config
|
||||||
|
from .chat_stream import ChatStream
|
||||||
|
|
||||||
|
|
||||||
class WillingManager:
|
class WillingManager:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.group_reply_willing = {} # 存储每个群的回复意愿
|
self.chat_reply_willing: Dict[str, float] = {} # 存储每个聊天流的回复意愿
|
||||||
|
self.chat_high_willing_mode: Dict[str, bool] = {} # 存储每个聊天流是否处于高回复意愿期
|
||||||
|
self.chat_msg_count: Dict[str, int] = {} # 存储每个聊天流接收到的消息数量
|
||||||
|
self.chat_last_mode_change: Dict[str, float] = {} # 存储每个聊天流上次模式切换的时间
|
||||||
|
self.chat_high_willing_duration: Dict[str, int] = {} # 高意愿期持续时间(秒)
|
||||||
|
self.chat_low_willing_duration: Dict[str, int] = {} # 低意愿期持续时间(秒)
|
||||||
|
self.chat_last_reply_time: Dict[str, float] = {} # 存储每个聊天流上次回复的时间
|
||||||
|
self.chat_last_sender_id: Dict[str, str] = {} # 存储每个聊天流上次回复的用户ID
|
||||||
|
self.chat_conversation_context: Dict[str, bool] = {} # 标记是否处于对话上下文中
|
||||||
self._decay_task = None
|
self._decay_task = None
|
||||||
|
self._mode_switch_task = None
|
||||||
self._started = False
|
self._started = False
|
||||||
|
|
||||||
async def _decay_reply_willing(self):
|
async def _decay_reply_willing(self):
|
||||||
"""定期衰减回复意愿"""
|
"""定期衰减回复意愿"""
|
||||||
while True:
|
while True:
|
||||||
await asyncio.sleep(5)
|
await asyncio.sleep(5)
|
||||||
for group_id in self.group_reply_willing:
|
for chat_id in self.chat_reply_willing:
|
||||||
self.group_reply_willing[group_id] = max(0, self.group_reply_willing[group_id] * 0.6)
|
is_high_mode = self.chat_high_willing_mode.get(chat_id, False)
|
||||||
|
if is_high_mode:
|
||||||
|
# 高回复意愿期内轻微衰减
|
||||||
|
self.chat_reply_willing[chat_id] = max(0.5, self.chat_reply_willing[chat_id] * 0.95)
|
||||||
|
else:
|
||||||
|
# 低回复意愿期内正常衰减
|
||||||
|
self.chat_reply_willing[chat_id] = max(0, self.chat_reply_willing[chat_id] * 0.8)
|
||||||
|
|
||||||
def get_willing(self, group_id: int) -> float:
|
async def _mode_switch_check(self):
|
||||||
"""获取指定群组的回复意愿"""
|
"""定期检查是否需要切换回复意愿模式"""
|
||||||
return self.group_reply_willing.get(group_id, 0)
|
while True:
|
||||||
|
current_time = time.time()
|
||||||
|
await asyncio.sleep(10) # 每10秒检查一次
|
||||||
|
|
||||||
def set_willing(self, group_id: int, willing: float):
|
for chat_id in self.chat_high_willing_mode:
|
||||||
"""设置指定群组的回复意愿"""
|
last_change_time = self.chat_last_mode_change.get(chat_id, 0)
|
||||||
self.group_reply_willing[group_id] = willing
|
is_high_mode = self.chat_high_willing_mode.get(chat_id, False)
|
||||||
|
|
||||||
def change_reply_willing_received(self, group_id: int, topic: str, is_mentioned_bot: bool, config, user_id: int = None, is_emoji: bool = False, interested_rate: float = 0) -> float:
|
# 获取当前模式的持续时间
|
||||||
"""改变指定群组的回复意愿并返回回复概率"""
|
duration = 0
|
||||||
current_willing = self.group_reply_willing.get(group_id, 0)
|
if is_high_mode:
|
||||||
|
duration = self.chat_high_willing_duration.get(chat_id, 180) # 默认3分钟
|
||||||
|
else:
|
||||||
|
duration = self.chat_low_willing_duration.get(chat_id, random.randint(300, 1200)) # 默认5-20分钟
|
||||||
|
|
||||||
# print(f"初始意愿: {current_willing}")
|
# 检查是否需要切换模式
|
||||||
if is_mentioned_bot and current_willing < 1.0:
|
if current_time - last_change_time > duration:
|
||||||
current_willing += 0.9
|
self._switch_willing_mode(chat_id)
|
||||||
print(f"被提及, 当前意愿: {current_willing}")
|
elif not is_high_mode and random.random() < 0.1:
|
||||||
elif is_mentioned_bot:
|
# 低回复意愿期有10%概率随机切换到高回复期
|
||||||
current_willing += 0.05
|
self._switch_willing_mode(chat_id)
|
||||||
print(f"被重复提及, 当前意愿: {current_willing}")
|
|
||||||
|
# 检查对话上下文状态是否需要重置
|
||||||
|
last_reply_time = self.chat_last_reply_time.get(chat_id, 0)
|
||||||
|
if current_time - last_reply_time > 300: # 5分钟无交互,重置对话上下文
|
||||||
|
self.chat_conversation_context[chat_id] = False
|
||||||
|
|
||||||
|
def _switch_willing_mode(self, chat_id: str):
|
||||||
|
"""切换聊天流的回复意愿模式"""
|
||||||
|
is_high_mode = self.chat_high_willing_mode.get(chat_id, False)
|
||||||
|
|
||||||
|
if is_high_mode:
|
||||||
|
# 从高回复期切换到低回复期
|
||||||
|
self.chat_high_willing_mode[chat_id] = False
|
||||||
|
self.chat_reply_willing[chat_id] = 0.1 # 设置为最低回复意愿
|
||||||
|
self.chat_low_willing_duration[chat_id] = random.randint(600, 1200) # 10-20分钟
|
||||||
|
logger.debug(f"聊天流 {chat_id} 切换到低回复意愿期,持续 {self.chat_low_willing_duration[chat_id]} 秒")
|
||||||
|
else:
|
||||||
|
# 从低回复期切换到高回复期
|
||||||
|
self.chat_high_willing_mode[chat_id] = True
|
||||||
|
self.chat_reply_willing[chat_id] = 1.0 # 设置为较高回复意愿
|
||||||
|
self.chat_high_willing_duration[chat_id] = random.randint(180, 240) # 3-4分钟
|
||||||
|
logger.debug(f"聊天流 {chat_id} 切换到高回复意愿期,持续 {self.chat_high_willing_duration[chat_id]} 秒")
|
||||||
|
|
||||||
|
self.chat_last_mode_change[chat_id] = time.time()
|
||||||
|
self.chat_msg_count[chat_id] = 0 # 重置消息计数
|
||||||
|
|
||||||
|
def get_willing(self, chat_stream: ChatStream) -> float:
|
||||||
|
"""获取指定聊天流的回复意愿"""
|
||||||
|
stream = chat_stream
|
||||||
|
if stream:
|
||||||
|
return self.chat_reply_willing.get(stream.stream_id, 0)
|
||||||
|
return 0
|
||||||
|
|
||||||
|
def set_willing(self, chat_id: str, willing: float):
|
||||||
|
"""设置指定聊天流的回复意愿"""
|
||||||
|
self.chat_reply_willing[chat_id] = willing
|
||||||
|
|
||||||
|
def _ensure_chat_initialized(self, chat_id: str):
|
||||||
|
"""确保聊天流的所有数据已初始化"""
|
||||||
|
if chat_id not in self.chat_reply_willing:
|
||||||
|
self.chat_reply_willing[chat_id] = 0.1
|
||||||
|
|
||||||
|
if chat_id not in self.chat_high_willing_mode:
|
||||||
|
self.chat_high_willing_mode[chat_id] = False
|
||||||
|
self.chat_last_mode_change[chat_id] = time.time()
|
||||||
|
self.chat_low_willing_duration[chat_id] = random.randint(300, 1200) # 5-20分钟
|
||||||
|
|
||||||
|
if chat_id not in self.chat_msg_count:
|
||||||
|
self.chat_msg_count[chat_id] = 0
|
||||||
|
|
||||||
|
if chat_id not in self.chat_conversation_context:
|
||||||
|
self.chat_conversation_context[chat_id] = False
|
||||||
|
|
||||||
|
async def change_reply_willing_received(self,
|
||||||
|
chat_stream: ChatStream,
|
||||||
|
topic: str = None,
|
||||||
|
is_mentioned_bot: bool = False,
|
||||||
|
config = None,
|
||||||
|
is_emoji: bool = False,
|
||||||
|
interested_rate: float = 0,
|
||||||
|
sender_id: str = None) -> float:
|
||||||
|
"""改变指定聊天流的回复意愿并返回回复概率"""
|
||||||
|
# 获取或创建聊天流
|
||||||
|
stream = chat_stream
|
||||||
|
chat_id = stream.stream_id
|
||||||
|
current_time = time.time()
|
||||||
|
|
||||||
|
self._ensure_chat_initialized(chat_id)
|
||||||
|
|
||||||
|
# 增加消息计数
|
||||||
|
self.chat_msg_count[chat_id] = self.chat_msg_count.get(chat_id, 0) + 1
|
||||||
|
|
||||||
|
current_willing = self.chat_reply_willing.get(chat_id, 0)
|
||||||
|
is_high_mode = self.chat_high_willing_mode.get(chat_id, False)
|
||||||
|
msg_count = self.chat_msg_count.get(chat_id, 0)
|
||||||
|
in_conversation_context = self.chat_conversation_context.get(chat_id, False)
|
||||||
|
|
||||||
|
# 检查是否是对话上下文中的追问
|
||||||
|
last_reply_time = self.chat_last_reply_time.get(chat_id, 0)
|
||||||
|
last_sender = self.chat_last_sender_id.get(chat_id, "")
|
||||||
|
is_follow_up_question = False
|
||||||
|
|
||||||
|
# 如果是同一个人在短时间内(2分钟内)发送消息,且消息数量较少(<=5条),视为追问
|
||||||
|
if sender_id and sender_id == last_sender and current_time - last_reply_time < 120 and msg_count <= 5:
|
||||||
|
is_follow_up_question = True
|
||||||
|
in_conversation_context = True
|
||||||
|
self.chat_conversation_context[chat_id] = True
|
||||||
|
logger.debug(f"检测到追问 (同一用户), 提高回复意愿")
|
||||||
|
current_willing += 0.3
|
||||||
|
|
||||||
|
# 特殊情况处理
|
||||||
|
if is_mentioned_bot:
|
||||||
|
current_willing += 0.5
|
||||||
|
in_conversation_context = True
|
||||||
|
self.chat_conversation_context[chat_id] = True
|
||||||
|
logger.debug(f"被提及, 当前意愿: {current_willing}")
|
||||||
|
|
||||||
if is_emoji:
|
if is_emoji:
|
||||||
current_willing *= 0.1
|
current_willing *= 0.1
|
||||||
print(f"表情包, 当前意愿: {current_willing}")
|
logger.debug(f"表情包, 当前意愿: {current_willing}")
|
||||||
|
|
||||||
print(f"放大系数_interested_rate: {global_config.response_interested_rate_amplifier}")
|
# 根据话题兴趣度适当调整
|
||||||
interested_rate *= global_config.response_interested_rate_amplifier #放大回复兴趣度
|
if interested_rate > 0.5:
|
||||||
if interested_rate > 0.4:
|
current_willing += (interested_rate - 0.5) * 0.5
|
||||||
# print(f"兴趣度: {interested_rate}, 当前意愿: {current_willing}")
|
|
||||||
current_willing += interested_rate-0.4
|
|
||||||
|
|
||||||
current_willing *= global_config.response_willing_amplifier #放大回复意愿
|
# 根据当前模式计算回复概率
|
||||||
# print(f"放大系数_willing: {global_config.response_willing_amplifier}, 当前意愿: {current_willing}")
|
base_probability = 0.0
|
||||||
|
|
||||||
reply_probability = max((current_willing - 0.45) * 2, 0)
|
if in_conversation_context:
|
||||||
if group_id not in config.talk_allowed_groups:
|
# 在对话上下文中,降低基础回复概率
|
||||||
current_willing = 0
|
base_probability = 0.5 if is_high_mode else 0.25
|
||||||
reply_probability = 0
|
logger.debug(f"处于对话上下文中,基础回复概率: {base_probability}")
|
||||||
|
elif is_high_mode:
|
||||||
|
# 高回复周期:4-8句话有50%的概率会回复一次
|
||||||
|
base_probability = 0.50 if 4 <= msg_count <= 8 else 0.2
|
||||||
|
else:
|
||||||
|
# 低回复周期:需要最少15句才有30%的概率会回一句
|
||||||
|
base_probability = 0.30 if msg_count >= 15 else 0.03 * min(msg_count, 10)
|
||||||
|
|
||||||
if group_id in config.talk_frequency_down_groups:
|
# 考虑回复意愿的影响
|
||||||
|
reply_probability = base_probability * current_willing
|
||||||
|
|
||||||
|
# 检查群组权限(如果是群聊)
|
||||||
|
if chat_stream.group_info and config:
|
||||||
|
if chat_stream.group_info.group_id in config.talk_frequency_down_groups:
|
||||||
reply_probability = reply_probability / global_config.down_frequency_rate
|
reply_probability = reply_probability / global_config.down_frequency_rate
|
||||||
|
|
||||||
reply_probability = min(reply_probability, 1)
|
# 限制最大回复概率
|
||||||
|
reply_probability = min(reply_probability, 0.75) # 设置最大回复概率为75%
|
||||||
if reply_probability < 0:
|
if reply_probability < 0:
|
||||||
reply_probability = 0
|
reply_probability = 0
|
||||||
|
|
||||||
|
# 记录当前发送者ID以便后续追踪
|
||||||
|
if sender_id:
|
||||||
|
self.chat_last_sender_id[chat_id] = sender_id
|
||||||
|
|
||||||
self.group_reply_willing[group_id] = min(current_willing, 3.0)
|
self.chat_reply_willing[chat_id] = min(current_willing, 3.0)
|
||||||
return reply_probability
|
return reply_probability
|
||||||
|
|
||||||
def change_reply_willing_sent(self, group_id: int):
|
def change_reply_willing_sent(self, chat_stream: ChatStream):
|
||||||
"""开始思考后降低群组的回复意愿"""
|
"""开始思考后降低聊天流的回复意愿"""
|
||||||
current_willing = self.group_reply_willing.get(group_id, 0)
|
stream = chat_stream
|
||||||
self.group_reply_willing[group_id] = max(0, current_willing - 2)
|
if stream:
|
||||||
|
chat_id = stream.stream_id
|
||||||
|
self._ensure_chat_initialized(chat_id)
|
||||||
|
is_high_mode = self.chat_high_willing_mode.get(chat_id, False)
|
||||||
|
current_willing = self.chat_reply_willing.get(chat_id, 0)
|
||||||
|
|
||||||
def change_reply_willing_after_sent(self, group_id: int):
|
# 回复后减少回复意愿
|
||||||
"""发送消息后提高群组的回复意愿"""
|
self.chat_reply_willing[chat_id] = max(0, current_willing - 0.3)
|
||||||
current_willing = self.group_reply_willing.get(group_id, 0)
|
|
||||||
if current_willing < 1:
|
# 标记为对话上下文中
|
||||||
self.group_reply_willing[group_id] = min(1, current_willing + 0.2)
|
self.chat_conversation_context[chat_id] = True
|
||||||
|
|
||||||
|
# 记录最后回复时间
|
||||||
|
self.chat_last_reply_time[chat_id] = time.time()
|
||||||
|
|
||||||
|
# 重置消息计数
|
||||||
|
self.chat_msg_count[chat_id] = 0
|
||||||
|
|
||||||
|
def change_reply_willing_not_sent(self, chat_stream: ChatStream):
|
||||||
|
"""决定不回复后提高聊天流的回复意愿"""
|
||||||
|
stream = chat_stream
|
||||||
|
if stream:
|
||||||
|
chat_id = stream.stream_id
|
||||||
|
self._ensure_chat_initialized(chat_id)
|
||||||
|
is_high_mode = self.chat_high_willing_mode.get(chat_id, False)
|
||||||
|
current_willing = self.chat_reply_willing.get(chat_id, 0)
|
||||||
|
in_conversation_context = self.chat_conversation_context.get(chat_id, False)
|
||||||
|
|
||||||
|
# 根据当前模式调整不回复后的意愿增加
|
||||||
|
if is_high_mode:
|
||||||
|
willing_increase = 0.1
|
||||||
|
elif in_conversation_context:
|
||||||
|
# 在对话上下文中但决定不回复,小幅增加回复意愿
|
||||||
|
willing_increase = 0.15
|
||||||
|
else:
|
||||||
|
willing_increase = random.uniform(0.05, 0.1)
|
||||||
|
|
||||||
|
self.chat_reply_willing[chat_id] = min(2.0, current_willing + willing_increase)
|
||||||
|
|
||||||
|
def change_reply_willing_after_sent(self, chat_stream: ChatStream):
|
||||||
|
"""发送消息后提高聊天流的回复意愿"""
|
||||||
|
# 由于已经在sent中处理,这个方法保留但不再需要额外调整
|
||||||
|
pass
|
||||||
|
|
||||||
async def ensure_started(self):
|
async def ensure_started(self):
|
||||||
"""确保衰减任务已启动"""
|
"""确保所有任务已启动"""
|
||||||
if not self._started:
|
if not self._started:
|
||||||
if self._decay_task is None:
|
if self._decay_task is None:
|
||||||
self._decay_task = asyncio.create_task(self._decay_reply_willing())
|
self._decay_task = asyncio.create_task(self._decay_reply_willing())
|
||||||
|
if self._mode_switch_task is None:
|
||||||
|
self._mode_switch_task = asyncio.create_task(self._mode_switch_check())
|
||||||
self._started = True
|
self._started = True
|
||||||
|
|
||||||
# 创建全局实例
|
# 创建全局实例
|
||||||
|
|||||||
10
src/plugins/config_reload/__init__.py
Normal file
@@ -0,0 +1,10 @@
|
|||||||
|
from nonebot import get_app
|
||||||
|
from .api import router
|
||||||
|
from loguru import logger
|
||||||
|
|
||||||
|
# 获取主应用实例并挂载路由
|
||||||
|
app = get_app()
|
||||||
|
app.include_router(router, prefix="/api")
|
||||||
|
|
||||||
|
# 打印日志,方便确认API已注册
|
||||||
|
logger.success("配置重载API已注册,可通过 /api/reload-config 访问")
|
||||||
17
src/plugins/config_reload/api.py
Normal file
@@ -0,0 +1,17 @@
|
|||||||
|
from fastapi import APIRouter, HTTPException
|
||||||
|
from src.plugins.chat.config import BotConfig
|
||||||
|
import os
|
||||||
|
|
||||||
|
# 创建APIRouter而不是FastAPI实例
|
||||||
|
router = APIRouter()
|
||||||
|
|
||||||
|
@router.post("/reload-config")
|
||||||
|
async def reload_config():
|
||||||
|
try:
|
||||||
|
bot_config_path = os.path.join(BotConfig.get_config_dir(), "bot_config.toml")
|
||||||
|
global_config = BotConfig.load_config(config_path=bot_config_path)
|
||||||
|
return {"message": "配置重载成功", "status": "success"}
|
||||||
|
except FileNotFoundError as e:
|
||||||
|
raise HTTPException(status_code=404, detail=str(e))
|
||||||
|
except Exception as e:
|
||||||
|
raise HTTPException(status_code=500, detail=f"重载配置时发生错误: {str(e)}")
|
||||||
3
src/plugins/config_reload/test.py
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
import requests
|
||||||
|
response = requests.post("http://localhost:8080/api/reload-config")
|
||||||
|
print(response.json())
|
||||||
@@ -1,198 +0,0 @@
|
|||||||
import os
|
|
||||||
import sys
|
|
||||||
import time
|
|
||||||
|
|
||||||
import requests
|
|
||||||
from dotenv import load_dotenv
|
|
||||||
|
|
||||||
# 添加项目根目录到 Python 路径
|
|
||||||
root_path = os.path.abspath(os.path.join(os.path.dirname(__file__), "../../.."))
|
|
||||||
sys.path.append(root_path)
|
|
||||||
|
|
||||||
# 加载根目录下的env.edv文件
|
|
||||||
env_path = os.path.join(root_path, ".env.dev")
|
|
||||||
if not os.path.exists(env_path):
|
|
||||||
raise FileNotFoundError(f"配置文件不存在: {env_path}")
|
|
||||||
load_dotenv(env_path)
|
|
||||||
|
|
||||||
from src.common.database import Database
|
|
||||||
|
|
||||||
# 从环境变量获取配置
|
|
||||||
Database.initialize(
|
|
||||||
host=os.getenv("MONGODB_HOST", "127.0.0.1"),
|
|
||||||
port=int(os.getenv("MONGODB_PORT", "27017")),
|
|
||||||
db_name=os.getenv("DATABASE_NAME", "maimai"),
|
|
||||||
username=os.getenv("MONGODB_USERNAME"),
|
|
||||||
password=os.getenv("MONGODB_PASSWORD"),
|
|
||||||
auth_source=os.getenv("MONGODB_AUTH_SOURCE", "admin")
|
|
||||||
)
|
|
||||||
|
|
||||||
class KnowledgeLibrary:
|
|
||||||
def __init__(self):
|
|
||||||
self.db = Database.get_instance()
|
|
||||||
self.raw_info_dir = "data/raw_info"
|
|
||||||
self._ensure_dirs()
|
|
||||||
self.api_key = os.getenv("SILICONFLOW_KEY")
|
|
||||||
if not self.api_key:
|
|
||||||
raise ValueError("SILICONFLOW_API_KEY 环境变量未设置")
|
|
||||||
|
|
||||||
def _ensure_dirs(self):
|
|
||||||
"""确保必要的目录存在"""
|
|
||||||
os.makedirs(self.raw_info_dir, exist_ok=True)
|
|
||||||
|
|
||||||
def get_embedding(self, text: str) -> list:
|
|
||||||
"""获取文本的embedding向量"""
|
|
||||||
url = "https://api.siliconflow.cn/v1/embeddings"
|
|
||||||
payload = {
|
|
||||||
"model": "BAAI/bge-m3",
|
|
||||||
"input": text,
|
|
||||||
"encoding_format": "float"
|
|
||||||
}
|
|
||||||
headers = {
|
|
||||||
"Authorization": f"Bearer {self.api_key}",
|
|
||||||
"Content-Type": "application/json"
|
|
||||||
}
|
|
||||||
|
|
||||||
response = requests.post(url, json=payload, headers=headers)
|
|
||||||
if response.status_code != 200:
|
|
||||||
print(f"获取embedding失败: {response.text}")
|
|
||||||
return None
|
|
||||||
|
|
||||||
return response.json()['data'][0]['embedding']
|
|
||||||
|
|
||||||
def process_files(self):
|
|
||||||
"""处理raw_info目录下的所有txt文件"""
|
|
||||||
for filename in os.listdir(self.raw_info_dir):
|
|
||||||
if filename.endswith('.txt'):
|
|
||||||
file_path = os.path.join(self.raw_info_dir, filename)
|
|
||||||
self.process_single_file(file_path)
|
|
||||||
|
|
||||||
def process_single_file(self, file_path: str):
|
|
||||||
"""处理单个文件"""
|
|
||||||
try:
|
|
||||||
# 检查文件是否已处理
|
|
||||||
if self.db.db.processed_files.find_one({"file_path": file_path}):
|
|
||||||
print(f"文件已处理过,跳过: {file_path}")
|
|
||||||
return
|
|
||||||
|
|
||||||
with open(file_path, 'r', encoding='utf-8') as f:
|
|
||||||
content = f.read()
|
|
||||||
|
|
||||||
# 按1024字符分段
|
|
||||||
segments = [content[i:i+600] for i in range(0, len(content), 600)]
|
|
||||||
|
|
||||||
# 处理每个分段
|
|
||||||
for segment in segments:
|
|
||||||
if not segment.strip(): # 跳过空段
|
|
||||||
continue
|
|
||||||
|
|
||||||
# 获取embedding
|
|
||||||
embedding = self.get_embedding(segment)
|
|
||||||
if not embedding:
|
|
||||||
continue
|
|
||||||
|
|
||||||
# 存储到数据库
|
|
||||||
doc = {
|
|
||||||
"content": segment,
|
|
||||||
"embedding": embedding,
|
|
||||||
"file_path": file_path,
|
|
||||||
"segment_length": len(segment)
|
|
||||||
}
|
|
||||||
|
|
||||||
# 使用文本内容的哈希值作为唯一标识
|
|
||||||
content_hash = hash(segment)
|
|
||||||
|
|
||||||
# 更新或插入文档
|
|
||||||
self.db.db.knowledges.update_one(
|
|
||||||
{"content_hash": content_hash},
|
|
||||||
{"$set": doc},
|
|
||||||
upsert=True
|
|
||||||
)
|
|
||||||
|
|
||||||
# 记录文件已处理
|
|
||||||
self.db.db.processed_files.insert_one({
|
|
||||||
"file_path": file_path,
|
|
||||||
"processed_time": time.time()
|
|
||||||
})
|
|
||||||
|
|
||||||
print(f"成功处理文件: {file_path}")
|
|
||||||
|
|
||||||
except Exception as e:
|
|
||||||
print(f"处理文件 {file_path} 时出错: {str(e)}")
|
|
||||||
|
|
||||||
def search_similar_segments(self, query: str, limit: int = 5) -> list:
|
|
||||||
"""搜索与查询文本相似的片段"""
|
|
||||||
query_embedding = self.get_embedding(query)
|
|
||||||
if not query_embedding:
|
|
||||||
return []
|
|
||||||
|
|
||||||
# 使用余弦相似度计算
|
|
||||||
pipeline = [
|
|
||||||
{
|
|
||||||
"$addFields": {
|
|
||||||
"dotProduct": {
|
|
||||||
"$reduce": {
|
|
||||||
"input": {"$range": [0, {"$size": "$embedding"}]},
|
|
||||||
"initialValue": 0,
|
|
||||||
"in": {
|
|
||||||
"$add": [
|
|
||||||
"$$value",
|
|
||||||
{"$multiply": [
|
|
||||||
{"$arrayElemAt": ["$embedding", "$$this"]},
|
|
||||||
{"$arrayElemAt": [query_embedding, "$$this"]}
|
|
||||||
]}
|
|
||||||
]
|
|
||||||
}
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"magnitude1": {
|
|
||||||
"$sqrt": {
|
|
||||||
"$reduce": {
|
|
||||||
"input": "$embedding",
|
|
||||||
"initialValue": 0,
|
|
||||||
"in": {"$add": ["$$value", {"$multiply": ["$$this", "$$this"]}]}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"magnitude2": {
|
|
||||||
"$sqrt": {
|
|
||||||
"$reduce": {
|
|
||||||
"input": query_embedding,
|
|
||||||
"initialValue": 0,
|
|
||||||
"in": {"$add": ["$$value", {"$multiply": ["$$this", "$$this"]}]}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"$addFields": {
|
|
||||||
"similarity": {
|
|
||||||
"$divide": ["$dotProduct", {"$multiply": ["$magnitude1", "$magnitude2"]}]
|
|
||||||
}
|
|
||||||
}
|
|
||||||
},
|
|
||||||
{"$sort": {"similarity": -1}},
|
|
||||||
{"$limit": limit},
|
|
||||||
{"$project": {"content": 1, "similarity": 1, "file_path": 1}}
|
|
||||||
]
|
|
||||||
|
|
||||||
results = list(self.db.db.knowledges.aggregate(pipeline))
|
|
||||||
return results
|
|
||||||
|
|
||||||
# 创建单例实例
|
|
||||||
knowledge_library = KnowledgeLibrary()
|
|
||||||
|
|
||||||
if __name__ == "__main__":
|
|
||||||
# 测试知识库功能
|
|
||||||
print("开始处理知识库文件...")
|
|
||||||
knowledge_library.process_files()
|
|
||||||
|
|
||||||
# 测试搜索功能
|
|
||||||
test_query = "麦麦评价一下僕と花"
|
|
||||||
print(f"\n搜索与'{test_query}'相似的内容:")
|
|
||||||
results = knowledge_library.search_similar_segments(test_query)
|
|
||||||
for result in results:
|
|
||||||
print(f"相似度: {result['similarity']:.4f}")
|
|
||||||
print(f"内容: {result['content'][:100]}...")
|
|
||||||
print("-" * 50)
|
|
||||||
@@ -7,9 +7,13 @@ import jieba
|
|||||||
import matplotlib.pyplot as plt
|
import matplotlib.pyplot as plt
|
||||||
import networkx as nx
|
import networkx as nx
|
||||||
from dotenv import load_dotenv
|
from dotenv import load_dotenv
|
||||||
|
from loguru import logger
|
||||||
|
|
||||||
sys.path.append("C:/GitHub/MaiMBot") # 添加项目根目录到 Python 路径
|
# 添加项目根目录到 Python 路径
|
||||||
from src.common.database import Database # 使用正确的导入语法
|
root_path = os.path.abspath(os.path.join(os.path.dirname(__file__), "../../.."))
|
||||||
|
sys.path.append(root_path)
|
||||||
|
|
||||||
|
from src.common.database import db # 使用正确的导入语法
|
||||||
|
|
||||||
# 加载.env.dev文件
|
# 加载.env.dev文件
|
||||||
env_path = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(os.path.dirname(__file__)))), '.env.dev')
|
env_path = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(os.path.dirname(__file__)))), '.env.dev')
|
||||||
@@ -19,7 +23,6 @@ load_dotenv(env_path)
|
|||||||
class Memory_graph:
|
class Memory_graph:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.G = nx.Graph() # 使用 networkx 的图结构
|
self.G = nx.Graph() # 使用 networkx 的图结构
|
||||||
self.db = Database.get_instance()
|
|
||||||
|
|
||||||
def connect_dot(self, concept1, concept2):
|
def connect_dot(self, concept1, concept2):
|
||||||
self.G.add_edge(concept1, concept2)
|
self.G.add_edge(concept1, concept2)
|
||||||
@@ -45,7 +48,7 @@ class Memory_graph:
|
|||||||
node_data = self.G.nodes[concept]
|
node_data = self.G.nodes[concept]
|
||||||
# print(node_data)
|
# print(node_data)
|
||||||
# 创建新的Memory_dot对象
|
# 创建新的Memory_dot对象
|
||||||
return concept,node_data
|
return concept, node_data
|
||||||
return None
|
return None
|
||||||
|
|
||||||
def get_related_item(self, topic, depth=1):
|
def get_related_item(self, topic, depth=1):
|
||||||
@@ -92,31 +95,33 @@ class Memory_graph:
|
|||||||
dot_data = {
|
dot_data = {
|
||||||
"concept": node
|
"concept": node
|
||||||
}
|
}
|
||||||
self.db.db.store_memory_dots.insert_one(dot_data)
|
db.store_memory_dots.insert_one(dot_data)
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def dots(self):
|
def dots(self):
|
||||||
# 返回所有节点对应的 Memory_dot 对象
|
# 返回所有节点对应的 Memory_dot 对象
|
||||||
return [self.get_dot(node) for node in self.G.nodes()]
|
return [self.get_dot(node) for node in self.G.nodes()]
|
||||||
|
|
||||||
|
|
||||||
def get_random_chat_from_db(self, length: int, timestamp: str):
|
def get_random_chat_from_db(self, length: int, timestamp: str):
|
||||||
# 从数据库中根据时间戳获取离其最近的聊天记录
|
# 从数据库中根据时间戳获取离其最近的聊天记录
|
||||||
chat_text = ''
|
chat_text = ''
|
||||||
closest_record = self.db.db.messages.find_one({"time": {"$lte": timestamp}}, sort=[('time', -1)]) # 调试输出
|
closest_record = db.messages.find_one({"time": {"$lte": timestamp}}, sort=[('time', -1)]) # 调试输出
|
||||||
print(f"距离time最近的消息时间: {time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(int(closest_record['time'])))}")
|
logger.info(
|
||||||
|
f"距离time最近的消息时间: {time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(int(closest_record['time'])))}")
|
||||||
|
|
||||||
if closest_record:
|
if closest_record:
|
||||||
closest_time = closest_record['time']
|
closest_time = closest_record['time']
|
||||||
group_id = closest_record['group_id'] # 获取groupid
|
group_id = closest_record['group_id'] # 获取groupid
|
||||||
# 获取该时间戳之后的length条消息,且groupid相同
|
# 获取该时间戳之后的length条消息,且groupid相同
|
||||||
chat_record = list(self.db.db.messages.find({"time": {"$gt": closest_time}, "group_id": group_id}).sort('time', 1).limit(length))
|
chat_record = list(
|
||||||
|
db.messages.find({"time": {"$gt": closest_time}, "group_id": group_id}).sort('time', 1).limit(
|
||||||
|
length))
|
||||||
for record in chat_record:
|
for record in chat_record:
|
||||||
time_str = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(int(record['time'])))
|
time_str = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(int(record['time'])))
|
||||||
try:
|
try:
|
||||||
displayname="[(%s)%s]%s" % (record["user_id"],record["user_nickname"],record["user_cardname"])
|
displayname = "[(%s)%s]%s" % (record["user_id"], record["user_nickname"], record["user_cardname"])
|
||||||
except:
|
except:
|
||||||
displayname=record["user_nickname"] or "用户" + str(record["user_id"])
|
displayname = record["user_nickname"] or "用户" + str(record["user_id"])
|
||||||
chat_text += f'[{time_str}] {displayname}: {record["processed_plain_text"]}\n' # 添加发送者和时间信息
|
chat_text += f'[{time_str}] {displayname}: {record["processed_plain_text"]}\n' # 添加发送者和时间信息
|
||||||
return chat_text
|
return chat_text
|
||||||
|
|
||||||
@@ -124,49 +129,39 @@ class Memory_graph:
|
|||||||
|
|
||||||
def save_graph_to_db(self):
|
def save_graph_to_db(self):
|
||||||
# 清空现有的图数据
|
# 清空现有的图数据
|
||||||
self.db.db.graph_data.delete_many({})
|
db.graph_data.delete_many({})
|
||||||
# 保存节点
|
# 保存节点
|
||||||
for node in self.G.nodes(data=True):
|
for node in self.G.nodes(data=True):
|
||||||
node_data = {
|
node_data = {
|
||||||
'concept': node[0],
|
'concept': node[0],
|
||||||
'memory_items': node[1].get('memory_items', []) # 默认为空列表
|
'memory_items': node[1].get('memory_items', []) # 默认为空列表
|
||||||
}
|
}
|
||||||
self.db.db.graph_data.nodes.insert_one(node_data)
|
db.graph_data.nodes.insert_one(node_data)
|
||||||
# 保存边
|
# 保存边
|
||||||
for edge in self.G.edges():
|
for edge in self.G.edges():
|
||||||
edge_data = {
|
edge_data = {
|
||||||
'source': edge[0],
|
'source': edge[0],
|
||||||
'target': edge[1]
|
'target': edge[1]
|
||||||
}
|
}
|
||||||
self.db.db.graph_data.edges.insert_one(edge_data)
|
db.graph_data.edges.insert_one(edge_data)
|
||||||
|
|
||||||
def load_graph_from_db(self):
|
def load_graph_from_db(self):
|
||||||
# 清空当前图
|
# 清空当前图
|
||||||
self.G.clear()
|
self.G.clear()
|
||||||
# 加载节点
|
# 加载节点
|
||||||
nodes = self.db.db.graph_data.nodes.find()
|
nodes = db.graph_data.nodes.find()
|
||||||
for node in nodes:
|
for node in nodes:
|
||||||
memory_items = node.get('memory_items', [])
|
memory_items = node.get('memory_items', [])
|
||||||
if not isinstance(memory_items, list):
|
if not isinstance(memory_items, list):
|
||||||
memory_items = [memory_items] if memory_items else []
|
memory_items = [memory_items] if memory_items else []
|
||||||
self.G.add_node(node['concept'], memory_items=memory_items)
|
self.G.add_node(node['concept'], memory_items=memory_items)
|
||||||
# 加载边
|
# 加载边
|
||||||
edges = self.db.db.graph_data.edges.find()
|
edges = db.graph_data.edges.find()
|
||||||
for edge in edges:
|
for edge in edges:
|
||||||
self.G.add_edge(edge['source'], edge['target'])
|
self.G.add_edge(edge['source'], edge['target'])
|
||||||
|
|
||||||
|
|
||||||
def main():
|
def main():
|
||||||
# 初始化数据库
|
|
||||||
Database.initialize(
|
|
||||||
host=os.getenv("MONGODB_HOST", "127.0.0.1"),
|
|
||||||
port=int(os.getenv("MONGODB_PORT", "27017")),
|
|
||||||
db_name=os.getenv("DATABASE_NAME", "MegBot"),
|
|
||||||
username=os.getenv("MONGODB_USERNAME", ""),
|
|
||||||
password=os.getenv("MONGODB_PASSWORD", ""),
|
|
||||||
auth_source=os.getenv("MONGODB_AUTH_SOURCE", "")
|
|
||||||
)
|
|
||||||
|
|
||||||
memory_graph = Memory_graph()
|
memory_graph = Memory_graph()
|
||||||
memory_graph.load_graph_from_db()
|
memory_graph.load_graph_from_db()
|
||||||
|
|
||||||
@@ -179,30 +174,31 @@ def main():
|
|||||||
break
|
break
|
||||||
first_layer_items, second_layer_items = memory_graph.get_related_item(query)
|
first_layer_items, second_layer_items = memory_graph.get_related_item(query)
|
||||||
if first_layer_items or second_layer_items:
|
if first_layer_items or second_layer_items:
|
||||||
print("\n第一层记忆:")
|
logger.debug("第一层记忆:")
|
||||||
for item in first_layer_items:
|
for item in first_layer_items:
|
||||||
print(item)
|
logger.debug(item)
|
||||||
print("\n第二层记忆:")
|
logger.debug("第二层记忆:")
|
||||||
for item in second_layer_items:
|
for item in second_layer_items:
|
||||||
print(item)
|
logger.debug(item)
|
||||||
else:
|
else:
|
||||||
print("未找到相关记忆。")
|
logger.debug("未找到相关记忆。")
|
||||||
|
|
||||||
|
|
||||||
def segment_text(text):
|
def segment_text(text):
|
||||||
seg_text = list(jieba.cut(text))
|
seg_text = list(jieba.cut(text))
|
||||||
return seg_text
|
return seg_text
|
||||||
|
|
||||||
|
|
||||||
def find_topic(text, topic_num):
|
def find_topic(text, topic_num):
|
||||||
prompt = f'这是一段文字:{text}。请你从这段话中总结出{topic_num}个话题,帮我列出来,用逗号隔开,尽可能精简。只需要列举{topic_num}个话题就好,不要告诉我其他内容。'
|
prompt = f'这是一段文字:{text}。请你从这段话中总结出{topic_num}个话题,帮我列出来,用逗号隔开,尽可能精简。只需要列举{topic_num}个话题就好,不要告诉我其他内容。'
|
||||||
return prompt
|
return prompt
|
||||||
|
|
||||||
|
|
||||||
def topic_what(text, topic):
|
def topic_what(text, topic):
|
||||||
prompt = f'这是一段文字:{text}。我想知道这记忆里有什么关于{topic}的话题,帮我总结成一句自然的话,可以包含时间和人物。只输出这句话就好'
|
prompt = f'这是一段文字:{text}。我想知道这记忆里有什么关于{topic}的话题,帮我总结成一句自然的话,可以包含时间和人物。只输出这句话就好'
|
||||||
return prompt
|
return prompt
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
def visualize_graph_lite(memory_graph: Memory_graph, color_by_memory: bool = False):
|
def visualize_graph_lite(memory_graph: Memory_graph, color_by_memory: bool = False):
|
||||||
# 设置中文字体
|
# 设置中文字体
|
||||||
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
|
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
|
||||||
@@ -226,7 +222,7 @@ def visualize_graph_lite(memory_graph: Memory_graph, color_by_memory: bool = Fal
|
|||||||
|
|
||||||
# 如果过滤后没有节点,则返回
|
# 如果过滤后没有节点,则返回
|
||||||
if len(H.nodes()) == 0:
|
if len(H.nodes()) == 0:
|
||||||
print("过滤后没有符合条件的节点可显示")
|
logger.debug("过滤后没有符合条件的节点可显示")
|
||||||
return
|
return
|
||||||
|
|
||||||
# 保存图到本地
|
# 保存图到本地
|
||||||
@@ -254,7 +250,7 @@ def visualize_graph_lite(memory_graph: Memory_graph, color_by_memory: bool = Fal
|
|||||||
memory_count = len(memory_items) if isinstance(memory_items, list) else (1 if memory_items else 0)
|
memory_count = len(memory_items) if isinstance(memory_items, list) else (1 if memory_items else 0)
|
||||||
# 使用指数函数使变化更明显
|
# 使用指数函数使变化更明显
|
||||||
ratio = memory_count / max_memories
|
ratio = memory_count / max_memories
|
||||||
size = 500 + 5000 * (ratio ) # 使用1.5次方函数使差异不那么明显
|
size = 500 + 5000 * (ratio) # 使用1.5次方函数使差异不那么明显
|
||||||
node_sizes.append(size)
|
node_sizes.append(size)
|
||||||
|
|
||||||
# 计算节点颜色(基于连接数)
|
# 计算节点颜色(基于连接数)
|
||||||
@@ -287,6 +283,5 @@ def visualize_graph_lite(memory_graph: Memory_graph, color_by_memory: bool = Fal
|
|||||||
plt.show()
|
plt.show()
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
if __name__ == "__main__":
|
if __name__ == "__main__":
|
||||||
main()
|
main()
|
||||||
@@ -3,47 +3,68 @@ import datetime
|
|||||||
import math
|
import math
|
||||||
import random
|
import random
|
||||||
import time
|
import time
|
||||||
|
import os
|
||||||
|
|
||||||
import jieba
|
import jieba
|
||||||
import networkx as nx
|
import networkx as nx
|
||||||
|
|
||||||
from ...common.database import Database # 使用正确的导入语法
|
from loguru import logger
|
||||||
|
from nonebot import get_driver
|
||||||
|
from ...common.database import db # 使用正确的导入语法
|
||||||
from ..chat.config import global_config
|
from ..chat.config import global_config
|
||||||
from ..chat.utils import (
|
from ..chat.utils import (
|
||||||
calculate_information_content,
|
calculate_information_content,
|
||||||
cosine_similarity,
|
cosine_similarity,
|
||||||
get_cloest_chat_from_db,
|
get_closest_chat_from_db,
|
||||||
text_to_vector,
|
text_to_vector,
|
||||||
)
|
)
|
||||||
from ..models.utils_model import LLM_request
|
from ..models.utils_model import LLM_request
|
||||||
|
|
||||||
|
|
||||||
class Memory_graph:
|
class Memory_graph:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.G = nx.Graph() # 使用 networkx 的图结构
|
self.G = nx.Graph() # 使用 networkx 的图结构
|
||||||
self.db = Database.get_instance()
|
|
||||||
|
|
||||||
def connect_dot(self, concept1, concept2):
|
def connect_dot(self, concept1, concept2):
|
||||||
# 如果边已存在,增加 strength
|
# 避免自连接
|
||||||
|
if concept1 == concept2:
|
||||||
|
return
|
||||||
|
|
||||||
|
current_time = datetime.datetime.now().timestamp()
|
||||||
|
|
||||||
|
# 如果边已存在,增加 strength
|
||||||
if self.G.has_edge(concept1, concept2):
|
if self.G.has_edge(concept1, concept2):
|
||||||
self.G[concept1][concept2]['strength'] = self.G[concept1][concept2].get('strength', 1) + 1
|
self.G[concept1][concept2]['strength'] = self.G[concept1][concept2].get('strength', 1) + 1
|
||||||
|
# 更新最后修改时间
|
||||||
|
self.G[concept1][concept2]['last_modified'] = current_time
|
||||||
else:
|
else:
|
||||||
# 如果是新边,初始化 strength 为 1
|
# 如果是新边,初始化 strength 为 1
|
||||||
self.G.add_edge(concept1, concept2, strength=1)
|
self.G.add_edge(concept1, concept2,
|
||||||
|
strength=1,
|
||||||
|
created_time=current_time, # 添加创建时间
|
||||||
|
last_modified=current_time) # 添加最后修改时间
|
||||||
|
|
||||||
def add_dot(self, concept, memory):
|
def add_dot(self, concept, memory):
|
||||||
|
current_time = datetime.datetime.now().timestamp()
|
||||||
|
|
||||||
if concept in self.G:
|
if concept in self.G:
|
||||||
# 如果节点已存在,将新记忆添加到现有列表中
|
|
||||||
if 'memory_items' in self.G.nodes[concept]:
|
if 'memory_items' in self.G.nodes[concept]:
|
||||||
if not isinstance(self.G.nodes[concept]['memory_items'], list):
|
if not isinstance(self.G.nodes[concept]['memory_items'], list):
|
||||||
# 如果当前不是列表,将其转换为列表
|
|
||||||
self.G.nodes[concept]['memory_items'] = [self.G.nodes[concept]['memory_items']]
|
self.G.nodes[concept]['memory_items'] = [self.G.nodes[concept]['memory_items']]
|
||||||
self.G.nodes[concept]['memory_items'].append(memory)
|
self.G.nodes[concept]['memory_items'].append(memory)
|
||||||
|
# 更新最后修改时间
|
||||||
|
self.G.nodes[concept]['last_modified'] = current_time
|
||||||
else:
|
else:
|
||||||
self.G.nodes[concept]['memory_items'] = [memory]
|
self.G.nodes[concept]['memory_items'] = [memory]
|
||||||
|
# 如果节点存在但没有memory_items,说明是第一次添加memory,设置created_time
|
||||||
|
if 'created_time' not in self.G.nodes[concept]:
|
||||||
|
self.G.nodes[concept]['created_time'] = current_time
|
||||||
|
self.G.nodes[concept]['last_modified'] = current_time
|
||||||
else:
|
else:
|
||||||
# 如果是新节点,创建新的记忆列表
|
# 如果是新节点,创建新的记忆列表
|
||||||
self.G.add_node(concept, memory_items=[memory])
|
self.G.add_node(concept,
|
||||||
|
memory_items=[memory],
|
||||||
|
created_time=current_time, # 添加创建时间
|
||||||
|
last_modified=current_time) # 添加最后修改时间
|
||||||
|
|
||||||
def get_dot(self, concept):
|
def get_dot(self, concept):
|
||||||
# 检查节点是否存在于图中
|
# 检查节点是否存在于图中
|
||||||
@@ -131,10 +152,10 @@ class Memory_graph:
|
|||||||
|
|
||||||
# 海马体
|
# 海马体
|
||||||
class Hippocampus:
|
class Hippocampus:
|
||||||
def __init__(self,memory_graph:Memory_graph):
|
def __init__(self, memory_graph: Memory_graph):
|
||||||
self.memory_graph = memory_graph
|
self.memory_graph = memory_graph
|
||||||
self.llm_topic_judge = LLM_request(model = global_config.llm_topic_judge,temperature=0.5)
|
self.llm_topic_judge = LLM_request(model=global_config.llm_topic_judge, temperature=0.5)
|
||||||
self.llm_summary_by_topic = LLM_request(model = global_config.llm_summary_by_topic,temperature=0.5)
|
self.llm_summary_by_topic = LLM_request(model=global_config.llm_summary_by_topic, temperature=0.5)
|
||||||
|
|
||||||
def get_all_node_names(self) -> list:
|
def get_all_node_names(self) -> list:
|
||||||
"""获取记忆图中所有节点的名字列表
|
"""获取记忆图中所有节点的名字列表
|
||||||
@@ -157,7 +178,7 @@ class Hippocampus:
|
|||||||
nodes = sorted([source, target])
|
nodes = sorted([source, target])
|
||||||
return hash(f"{nodes[0]}:{nodes[1]}")
|
return hash(f"{nodes[0]}:{nodes[1]}")
|
||||||
|
|
||||||
def get_memory_sample(self, chat_size=20, time_frequency:dict={'near':2,'mid':4,'far':3}):
|
def get_memory_sample(self, chat_size=20, time_frequency: dict = {'near': 2, 'mid': 4, 'far': 3}):
|
||||||
"""获取记忆样本
|
"""获取记忆样本
|
||||||
|
|
||||||
Returns:
|
Returns:
|
||||||
@@ -169,19 +190,19 @@ class Hippocampus:
|
|||||||
# 短期:1h 中期:4h 长期:24h
|
# 短期:1h 中期:4h 长期:24h
|
||||||
for _ in range(time_frequency.get('near')):
|
for _ in range(time_frequency.get('near')):
|
||||||
random_time = current_timestamp - random.randint(1, 3600)
|
random_time = current_timestamp - random.randint(1, 3600)
|
||||||
messages = get_cloest_chat_from_db(db=self.memory_graph.db, length=chat_size, timestamp=random_time)
|
messages = get_closest_chat_from_db(length=chat_size, timestamp=random_time)
|
||||||
if messages:
|
if messages:
|
||||||
chat_samples.append(messages)
|
chat_samples.append(messages)
|
||||||
|
|
||||||
for _ in range(time_frequency.get('mid')):
|
for _ in range(time_frequency.get('mid')):
|
||||||
random_time = current_timestamp - random.randint(3600, 3600*4)
|
random_time = current_timestamp - random.randint(3600, 3600 * 4)
|
||||||
messages = get_cloest_chat_from_db(db=self.memory_graph.db, length=chat_size, timestamp=random_time)
|
messages = get_closest_chat_from_db(length=chat_size, timestamp=random_time)
|
||||||
if messages:
|
if messages:
|
||||||
chat_samples.append(messages)
|
chat_samples.append(messages)
|
||||||
|
|
||||||
for _ in range(time_frequency.get('far')):
|
for _ in range(time_frequency.get('far')):
|
||||||
random_time = current_timestamp - random.randint(3600*4, 3600*24)
|
random_time = current_timestamp - random.randint(3600 * 4, 3600 * 24)
|
||||||
messages = get_cloest_chat_from_db(db=self.memory_graph.db, length=chat_size, timestamp=random_time)
|
messages = get_closest_chat_from_db(length=chat_size, timestamp=random_time)
|
||||||
if messages:
|
if messages:
|
||||||
chat_samples.append(messages)
|
chat_samples.append(messages)
|
||||||
|
|
||||||
@@ -190,15 +211,11 @@ class Hippocampus:
|
|||||||
async def memory_compress(self, messages: list, compress_rate=0.1):
|
async def memory_compress(self, messages: list, compress_rate=0.1):
|
||||||
"""压缩消息记录为记忆
|
"""压缩消息记录为记忆
|
||||||
|
|
||||||
Args:
|
|
||||||
messages: 消息记录字典列表,每个字典包含text和time字段
|
|
||||||
compress_rate: 压缩率
|
|
||||||
|
|
||||||
Returns:
|
Returns:
|
||||||
set: (话题, 记忆) 元组集合
|
tuple: (压缩记忆集合, 相似主题字典)
|
||||||
"""
|
"""
|
||||||
if not messages:
|
if not messages:
|
||||||
return set()
|
return set(), {}
|
||||||
|
|
||||||
# 合并消息文本,同时保留时间信息
|
# 合并消息文本,同时保留时间信息
|
||||||
input_text = ""
|
input_text = ""
|
||||||
@@ -221,19 +238,20 @@ class Hippocampus:
|
|||||||
time_info += f"是从 {earliest_str} 到 {latest_str} 的对话:\n"
|
time_info += f"是从 {earliest_str} 到 {latest_str} 的对话:\n"
|
||||||
|
|
||||||
for msg in messages:
|
for msg in messages:
|
||||||
input_text += f"{msg['text']}\n"
|
input_text += f"{msg['detailed_plain_text']}\n"
|
||||||
|
|
||||||
print(input_text)
|
logger.debug(input_text)
|
||||||
|
|
||||||
topic_num = self.calculate_topic_num(input_text, compress_rate)
|
topic_num = self.calculate_topic_num(input_text, compress_rate)
|
||||||
topics_response = await self.llm_topic_judge.generate_response(self.find_topic_llm(input_text, topic_num))
|
topics_response = await self.llm_topic_judge.generate_response(self.find_topic_llm(input_text, topic_num))
|
||||||
|
|
||||||
# 过滤topics
|
# 过滤topics
|
||||||
filter_keywords = global_config.memory_ban_words
|
filter_keywords = global_config.memory_ban_words
|
||||||
topics = [topic.strip() for topic in topics_response[0].replace(",", ",").replace("、", ",").replace(" ", ",").split(",") if topic.strip()]
|
topics = [topic.strip() for topic in
|
||||||
|
topics_response[0].replace(",", ",").replace("、", ",").replace(" ", ",").split(",") if topic.strip()]
|
||||||
filtered_topics = [topic for topic in topics if not any(keyword in topic for keyword in filter_keywords)]
|
filtered_topics = [topic for topic in topics if not any(keyword in topic for keyword in filter_keywords)]
|
||||||
|
|
||||||
print(f"过滤后话题: {filtered_topics}")
|
logger.info(f"过滤后话题: {filtered_topics}")
|
||||||
|
|
||||||
# 创建所有话题的请求任务
|
# 创建所有话题的请求任务
|
||||||
tasks = []
|
tasks = []
|
||||||
@@ -244,50 +262,85 @@ class Hippocampus:
|
|||||||
|
|
||||||
# 等待所有任务完成
|
# 等待所有任务完成
|
||||||
compressed_memory = set()
|
compressed_memory = set()
|
||||||
|
similar_topics_dict = {} # 存储每个话题的相似主题列表
|
||||||
for topic, task in tasks:
|
for topic, task in tasks:
|
||||||
response = await task
|
response = await task
|
||||||
if response:
|
if response:
|
||||||
compressed_memory.add((topic, response[0]))
|
compressed_memory.add((topic, response[0]))
|
||||||
|
# 为每个话题查找相似的已存在主题
|
||||||
|
existing_topics = list(self.memory_graph.G.nodes())
|
||||||
|
similar_topics = []
|
||||||
|
|
||||||
return compressed_memory
|
for existing_topic in existing_topics:
|
||||||
|
topic_words = set(jieba.cut(topic))
|
||||||
|
existing_words = set(jieba.cut(existing_topic))
|
||||||
|
|
||||||
def calculate_topic_num(self,text, compress_rate):
|
all_words = topic_words | existing_words
|
||||||
|
v1 = [1 if word in topic_words else 0 for word in all_words]
|
||||||
|
v2 = [1 if word in existing_words else 0 for word in all_words]
|
||||||
|
|
||||||
|
similarity = cosine_similarity(v1, v2)
|
||||||
|
|
||||||
|
if similarity >= 0.6:
|
||||||
|
similar_topics.append((existing_topic, similarity))
|
||||||
|
|
||||||
|
similar_topics.sort(key=lambda x: x[1], reverse=True)
|
||||||
|
similar_topics = similar_topics[:5]
|
||||||
|
similar_topics_dict[topic] = similar_topics
|
||||||
|
|
||||||
|
return compressed_memory, similar_topics_dict
|
||||||
|
|
||||||
|
def calculate_topic_num(self, text, compress_rate):
|
||||||
"""计算文本的话题数量"""
|
"""计算文本的话题数量"""
|
||||||
information_content = calculate_information_content(text)
|
information_content = calculate_information_content(text)
|
||||||
topic_by_length = text.count('\n')*compress_rate
|
topic_by_length = text.count('\n') * compress_rate
|
||||||
topic_by_information_content = max(1, min(5, int((information_content-3) * 2)))
|
topic_by_information_content = max(1, min(5, int((information_content - 3) * 2)))
|
||||||
topic_num = int((topic_by_length + topic_by_information_content)/2)
|
topic_num = int((topic_by_length + topic_by_information_content) / 2)
|
||||||
print(f"topic_by_length: {topic_by_length}, topic_by_information_content: {topic_by_information_content}, topic_num: {topic_num}")
|
logger.debug(
|
||||||
|
f"topic_by_length: {topic_by_length}, topic_by_information_content: {topic_by_information_content}, "
|
||||||
|
f"topic_num: {topic_num}")
|
||||||
return topic_num
|
return topic_num
|
||||||
|
|
||||||
async def operation_build_memory(self,chat_size=20):
|
async def operation_build_memory(self, chat_size=20):
|
||||||
# 最近消息获取频率
|
time_frequency = {'near': 1, 'mid': 4, 'far': 4}
|
||||||
time_frequency = {'near':2,'mid':4,'far':2}
|
memory_samples = self.get_memory_sample(chat_size, time_frequency)
|
||||||
memory_sample = self.get_memory_sample(chat_size,time_frequency)
|
|
||||||
|
|
||||||
for i, input_text in enumerate(memory_sample, 1):
|
for i, messages in enumerate(memory_samples, 1):
|
||||||
# 加载进度可视化
|
|
||||||
all_topics = []
|
all_topics = []
|
||||||
progress = (i / len(memory_sample)) * 100
|
# 加载进度可视化
|
||||||
|
progress = (i / len(memory_samples)) * 100
|
||||||
bar_length = 30
|
bar_length = 30
|
||||||
filled_length = int(bar_length * i // len(memory_sample))
|
filled_length = int(bar_length * i // len(memory_samples))
|
||||||
bar = '█' * filled_length + '-' * (bar_length - filled_length)
|
bar = '█' * filled_length + '-' * (bar_length - filled_length)
|
||||||
print(f"\n进度: [{bar}] {progress:.1f}% ({i}/{len(memory_sample)})")
|
logger.debug(f"进度: [{bar}] {progress:.1f}% ({i}/{len(memory_samples)})")
|
||||||
|
|
||||||
# 生成压缩后记忆 ,表现为 (话题,记忆) 的元组
|
compress_rate = global_config.memory_compress_rate
|
||||||
compressed_memory = set()
|
compressed_memory, similar_topics_dict = await self.memory_compress(messages, compress_rate)
|
||||||
compress_rate = 0.1
|
logger.info(f"压缩后记忆数量: {len(compressed_memory)},似曾相识的话题: {len(similar_topics_dict)}")
|
||||||
compressed_memory = await self.memory_compress(input_text, compress_rate)
|
|
||||||
print(f"\033[1;33m压缩后记忆数量\033[0m: {len(compressed_memory)}")
|
current_time = datetime.datetime.now().timestamp()
|
||||||
|
|
||||||
# 将记忆加入到图谱中
|
|
||||||
for topic, memory in compressed_memory:
|
for topic, memory in compressed_memory:
|
||||||
print(f"\033[1;32m添加节点\033[0m: {topic}")
|
logger.info(f"添加节点: {topic}")
|
||||||
self.memory_graph.add_dot(topic, memory)
|
self.memory_graph.add_dot(topic, memory)
|
||||||
all_topics.append(topic) # 收集所有话题
|
all_topics.append(topic)
|
||||||
|
|
||||||
|
# 连接相似的已存在主题
|
||||||
|
if topic in similar_topics_dict:
|
||||||
|
similar_topics = similar_topics_dict[topic]
|
||||||
|
for similar_topic, similarity in similar_topics:
|
||||||
|
if topic != similar_topic:
|
||||||
|
strength = int(similarity * 10)
|
||||||
|
logger.info(f"连接相似节点: {topic} 和 {similar_topic} (强度: {strength})")
|
||||||
|
self.memory_graph.G.add_edge(topic, similar_topic,
|
||||||
|
strength=strength,
|
||||||
|
created_time=current_time,
|
||||||
|
last_modified=current_time)
|
||||||
|
|
||||||
|
# 连接同批次的相关话题
|
||||||
for i in range(len(all_topics)):
|
for i in range(len(all_topics)):
|
||||||
for j in range(i + 1, len(all_topics)):
|
for j in range(i + 1, len(all_topics)):
|
||||||
print(f"\033[1;32m连接节点\033[0m: {all_topics[i]} 和 {all_topics[j]}")
|
logger.info(f"连接同批次节点: {all_topics[i]} 和 {all_topics[j]}")
|
||||||
self.memory_graph.connect_dot(all_topics[i], all_topics[j])
|
self.memory_graph.connect_dot(all_topics[i], all_topics[j])
|
||||||
|
|
||||||
self.sync_memory_to_db()
|
self.sync_memory_to_db()
|
||||||
@@ -295,10 +348,10 @@ class Hippocampus:
|
|||||||
def sync_memory_to_db(self):
|
def sync_memory_to_db(self):
|
||||||
"""检查并同步内存中的图结构与数据库"""
|
"""检查并同步内存中的图结构与数据库"""
|
||||||
# 获取数据库中所有节点和内存中所有节点
|
# 获取数据库中所有节点和内存中所有节点
|
||||||
db_nodes = list(self.memory_graph.db.db.graph_data.nodes.find())
|
db_nodes = list(db.graph_data.nodes.find())
|
||||||
memory_nodes = list(self.memory_graph.G.nodes(data=True))
|
memory_nodes = list(self.memory_graph.G.nodes(data=True))
|
||||||
|
|
||||||
# 转换数据库节点为字典格式,方便查找
|
# 转换数据库节点为字典格式,方便查找
|
||||||
db_nodes_dict = {node['concept']: node for node in db_nodes}
|
db_nodes_dict = {node['concept']: node for node in db_nodes}
|
||||||
|
|
||||||
# 检查并更新节点
|
# 检查并更新节点
|
||||||
@@ -310,38 +363,40 @@ class Hippocampus:
|
|||||||
# 计算内存中节点的特征值
|
# 计算内存中节点的特征值
|
||||||
memory_hash = self.calculate_node_hash(concept, memory_items)
|
memory_hash = self.calculate_node_hash(concept, memory_items)
|
||||||
|
|
||||||
|
# 获取时间信息
|
||||||
|
created_time = data.get('created_time', datetime.datetime.now().timestamp())
|
||||||
|
last_modified = data.get('last_modified', datetime.datetime.now().timestamp())
|
||||||
|
|
||||||
if concept not in db_nodes_dict:
|
if concept not in db_nodes_dict:
|
||||||
# 数据库中缺少的节点,添加
|
# 数据库中缺少的节点,添加
|
||||||
node_data = {
|
node_data = {
|
||||||
'concept': concept,
|
'concept': concept,
|
||||||
'memory_items': memory_items,
|
'memory_items': memory_items,
|
||||||
'hash': memory_hash
|
'hash': memory_hash,
|
||||||
|
'created_time': created_time,
|
||||||
|
'last_modified': last_modified
|
||||||
}
|
}
|
||||||
self.memory_graph.db.db.graph_data.nodes.insert_one(node_data)
|
db.graph_data.nodes.insert_one(node_data)
|
||||||
else:
|
else:
|
||||||
# 获取数据库中节点的特征值
|
# 获取数据库中节点的特征值
|
||||||
db_node = db_nodes_dict[concept]
|
db_node = db_nodes_dict[concept]
|
||||||
db_hash = db_node.get('hash', None)
|
db_hash = db_node.get('hash', None)
|
||||||
|
|
||||||
# 如果特征值不同,则更新节点
|
# 如果特征值不同,则更新节点
|
||||||
if db_hash != memory_hash:
|
if db_hash != memory_hash:
|
||||||
self.memory_graph.db.db.graph_data.nodes.update_one(
|
db.graph_data.nodes.update_one(
|
||||||
{'concept': concept},
|
{'concept': concept},
|
||||||
{'$set': {
|
{'$set': {
|
||||||
'memory_items': memory_items,
|
'memory_items': memory_items,
|
||||||
'hash': memory_hash
|
'hash': memory_hash,
|
||||||
|
'created_time': created_time,
|
||||||
|
'last_modified': last_modified
|
||||||
}}
|
}}
|
||||||
)
|
)
|
||||||
|
|
||||||
# 检查并删除数据库中多余的节点
|
|
||||||
memory_concepts = set(node[0] for node in memory_nodes)
|
|
||||||
for db_node in db_nodes:
|
|
||||||
if db_node['concept'] not in memory_concepts:
|
|
||||||
self.memory_graph.db.db.graph_data.nodes.delete_one({'concept': db_node['concept']})
|
|
||||||
|
|
||||||
# 处理边的信息
|
# 处理边的信息
|
||||||
db_edges = list(self.memory_graph.db.db.graph_data.edges.find())
|
db_edges = list(db.graph_data.edges.find())
|
||||||
memory_edges = list(self.memory_graph.G.edges())
|
memory_edges = list(self.memory_graph.G.edges(data=True))
|
||||||
|
|
||||||
# 创建边的哈希值字典
|
# 创建边的哈希值字典
|
||||||
db_edge_dict = {}
|
db_edge_dict = {}
|
||||||
@@ -353,10 +408,14 @@ class Hippocampus:
|
|||||||
}
|
}
|
||||||
|
|
||||||
# 检查并更新边
|
# 检查并更新边
|
||||||
for source, target in memory_edges:
|
for source, target, data in memory_edges:
|
||||||
edge_hash = self.calculate_edge_hash(source, target)
|
edge_hash = self.calculate_edge_hash(source, target)
|
||||||
edge_key = (source, target)
|
edge_key = (source, target)
|
||||||
strength = self.memory_graph.G[source][target].get('strength', 1)
|
strength = data.get('strength', 1)
|
||||||
|
|
||||||
|
# 获取边的时间信息
|
||||||
|
created_time = data.get('created_time', datetime.datetime.now().timestamp())
|
||||||
|
last_modified = data.get('last_modified', datetime.datetime.now().timestamp())
|
||||||
|
|
||||||
if edge_key not in db_edge_dict:
|
if edge_key not in db_edge_dict:
|
||||||
# 添加新边
|
# 添加新边
|
||||||
@@ -364,98 +423,180 @@ class Hippocampus:
|
|||||||
'source': source,
|
'source': source,
|
||||||
'target': target,
|
'target': target,
|
||||||
'strength': strength,
|
'strength': strength,
|
||||||
'hash': edge_hash
|
'hash': edge_hash,
|
||||||
|
'created_time': created_time,
|
||||||
|
'last_modified': last_modified
|
||||||
}
|
}
|
||||||
self.memory_graph.db.db.graph_data.edges.insert_one(edge_data)
|
db.graph_data.edges.insert_one(edge_data)
|
||||||
else:
|
else:
|
||||||
# 检查边的特征值是否变化
|
# 检查边的特征值是否变化
|
||||||
if db_edge_dict[edge_key]['hash'] != edge_hash:
|
if db_edge_dict[edge_key]['hash'] != edge_hash:
|
||||||
self.memory_graph.db.db.graph_data.edges.update_one(
|
db.graph_data.edges.update_one(
|
||||||
{'source': source, 'target': target},
|
{'source': source, 'target': target},
|
||||||
{'$set': {
|
{'$set': {
|
||||||
'hash': edge_hash,
|
'hash': edge_hash,
|
||||||
'strength': strength
|
'strength': strength,
|
||||||
|
'created_time': created_time,
|
||||||
|
'last_modified': last_modified
|
||||||
}}
|
}}
|
||||||
)
|
)
|
||||||
|
|
||||||
# 删除多余的边
|
|
||||||
memory_edge_set = set(memory_edges)
|
|
||||||
for edge_key in db_edge_dict:
|
|
||||||
if edge_key not in memory_edge_set:
|
|
||||||
source, target = edge_key
|
|
||||||
self.memory_graph.db.db.graph_data.edges.delete_one({
|
|
||||||
'source': source,
|
|
||||||
'target': target
|
|
||||||
})
|
|
||||||
|
|
||||||
def sync_memory_from_db(self):
|
def sync_memory_from_db(self):
|
||||||
"""从数据库同步数据到内存中的图结构"""
|
"""从数据库同步数据到内存中的图结构"""
|
||||||
|
current_time = datetime.datetime.now().timestamp()
|
||||||
|
need_update = False
|
||||||
|
|
||||||
# 清空当前图
|
# 清空当前图
|
||||||
self.memory_graph.G.clear()
|
self.memory_graph.G.clear()
|
||||||
|
|
||||||
# 从数据库加载所有节点
|
# 从数据库加载所有节点
|
||||||
nodes = self.memory_graph.db.db.graph_data.nodes.find()
|
nodes = list(db.graph_data.nodes.find())
|
||||||
for node in nodes:
|
for node in nodes:
|
||||||
concept = node['concept']
|
concept = node['concept']
|
||||||
memory_items = node.get('memory_items', [])
|
memory_items = node.get('memory_items', [])
|
||||||
# 确保memory_items是列表
|
|
||||||
if not isinstance(memory_items, list):
|
if not isinstance(memory_items, list):
|
||||||
memory_items = [memory_items] if memory_items else []
|
memory_items = [memory_items] if memory_items else []
|
||||||
|
|
||||||
|
# 检查时间字段是否存在
|
||||||
|
if 'created_time' not in node or 'last_modified' not in node:
|
||||||
|
need_update = True
|
||||||
|
# 更新数据库中的节点
|
||||||
|
update_data = {}
|
||||||
|
if 'created_time' not in node:
|
||||||
|
update_data['created_time'] = current_time
|
||||||
|
if 'last_modified' not in node:
|
||||||
|
update_data['last_modified'] = current_time
|
||||||
|
|
||||||
|
db.graph_data.nodes.update_one(
|
||||||
|
{'concept': concept},
|
||||||
|
{'$set': update_data}
|
||||||
|
)
|
||||||
|
logger.info(f"为节点 {concept} 添加缺失的时间字段")
|
||||||
|
|
||||||
|
# 获取时间信息(如果不存在则使用当前时间)
|
||||||
|
created_time = node.get('created_time', current_time)
|
||||||
|
last_modified = node.get('last_modified', current_time)
|
||||||
|
|
||||||
# 添加节点到图中
|
# 添加节点到图中
|
||||||
self.memory_graph.G.add_node(concept, memory_items=memory_items)
|
self.memory_graph.G.add_node(concept,
|
||||||
|
memory_items=memory_items,
|
||||||
|
created_time=created_time,
|
||||||
|
last_modified=last_modified)
|
||||||
|
|
||||||
# 从数据库加载所有边
|
# 从数据库加载所有边
|
||||||
edges = self.memory_graph.db.db.graph_data.edges.find()
|
edges = list(db.graph_data.edges.find())
|
||||||
for edge in edges:
|
for edge in edges:
|
||||||
source = edge['source']
|
source = edge['source']
|
||||||
target = edge['target']
|
target = edge['target']
|
||||||
strength = edge.get('strength', 1) # 获取 strength,默认为 1
|
strength = edge.get('strength', 1)
|
||||||
|
|
||||||
|
# 检查时间字段是否存在
|
||||||
|
if 'created_time' not in edge or 'last_modified' not in edge:
|
||||||
|
need_update = True
|
||||||
|
# 更新数据库中的边
|
||||||
|
update_data = {}
|
||||||
|
if 'created_time' not in edge:
|
||||||
|
update_data['created_time'] = current_time
|
||||||
|
if 'last_modified' not in edge:
|
||||||
|
update_data['last_modified'] = current_time
|
||||||
|
|
||||||
|
db.graph_data.edges.update_one(
|
||||||
|
{'source': source, 'target': target},
|
||||||
|
{'$set': update_data}
|
||||||
|
)
|
||||||
|
logger.info(f"为边 {source} - {target} 添加缺失的时间字段")
|
||||||
|
|
||||||
|
# 获取时间信息(如果不存在则使用当前时间)
|
||||||
|
created_time = edge.get('created_time', current_time)
|
||||||
|
last_modified = edge.get('last_modified', current_time)
|
||||||
|
|
||||||
# 只有当源节点和目标节点都存在时才添加边
|
# 只有当源节点和目标节点都存在时才添加边
|
||||||
if source in self.memory_graph.G and target in self.memory_graph.G:
|
if source in self.memory_graph.G and target in self.memory_graph.G:
|
||||||
self.memory_graph.G.add_edge(source, target, strength=strength)
|
self.memory_graph.G.add_edge(source, target,
|
||||||
|
strength=strength,
|
||||||
|
created_time=created_time,
|
||||||
|
last_modified=last_modified)
|
||||||
|
|
||||||
|
if need_update:
|
||||||
|
logger.success("已为缺失的时间字段进行补充")
|
||||||
|
|
||||||
async def operation_forget_topic(self, percentage=0.1):
|
async def operation_forget_topic(self, percentage=0.1):
|
||||||
"""随机选择图中一定比例的节点进行检查,根据条件决定是否遗忘"""
|
"""随机选择图中一定比例的节点和边进行检查,根据时间条件决定是否遗忘"""
|
||||||
# 获取所有节点
|
# 检查数据库是否为空
|
||||||
all_nodes = list(self.memory_graph.G.nodes())
|
all_nodes = list(self.memory_graph.G.nodes())
|
||||||
# 计算要检查的节点数量
|
all_edges = list(self.memory_graph.G.edges())
|
||||||
check_count = max(1, int(len(all_nodes) * percentage))
|
|
||||||
# 随机选择节点
|
|
||||||
nodes_to_check = random.sample(all_nodes, check_count)
|
|
||||||
|
|
||||||
forgotten_nodes = []
|
if not all_nodes and not all_edges:
|
||||||
|
logger.info("记忆图为空,无需进行遗忘操作")
|
||||||
|
return
|
||||||
|
|
||||||
|
check_nodes_count = max(1, int(len(all_nodes) * percentage))
|
||||||
|
check_edges_count = max(1, int(len(all_edges) * percentage))
|
||||||
|
|
||||||
|
nodes_to_check = random.sample(all_nodes, check_nodes_count)
|
||||||
|
edges_to_check = random.sample(all_edges, check_edges_count)
|
||||||
|
|
||||||
|
edge_changes = {'weakened': 0, 'removed': 0}
|
||||||
|
node_changes = {'reduced': 0, 'removed': 0}
|
||||||
|
|
||||||
|
current_time = datetime.datetime.now().timestamp()
|
||||||
|
|
||||||
|
# 检查并遗忘连接
|
||||||
|
logger.info("开始检查连接...")
|
||||||
|
for source, target in edges_to_check:
|
||||||
|
edge_data = self.memory_graph.G[source][target]
|
||||||
|
last_modified = edge_data.get('last_modified')
|
||||||
|
# print(source,target)
|
||||||
|
# print(f"float(last_modified):{float(last_modified)}" )
|
||||||
|
# print(f"current_time:{current_time}")
|
||||||
|
# print(f"current_time - last_modified:{current_time - last_modified}")
|
||||||
|
if current_time - last_modified > 3600*global_config.memory_forget_time: # test
|
||||||
|
current_strength = edge_data.get('strength', 1)
|
||||||
|
new_strength = current_strength - 1
|
||||||
|
|
||||||
|
if new_strength <= 0:
|
||||||
|
self.memory_graph.G.remove_edge(source, target)
|
||||||
|
edge_changes['removed'] += 1
|
||||||
|
logger.info(f"\033[1;31m[连接移除]\033[0m {source} - {target}")
|
||||||
|
else:
|
||||||
|
edge_data['strength'] = new_strength
|
||||||
|
edge_data['last_modified'] = current_time
|
||||||
|
edge_changes['weakened'] += 1
|
||||||
|
logger.info(f"\033[1;34m[连接减弱]\033[0m {source} - {target} (强度: {current_strength} -> {new_strength})")
|
||||||
|
|
||||||
|
# 检查并遗忘话题
|
||||||
|
logger.info("开始检查节点...")
|
||||||
for node in nodes_to_check:
|
for node in nodes_to_check:
|
||||||
# 获取节点的连接数
|
node_data = self.memory_graph.G.nodes[node]
|
||||||
connections = self.memory_graph.G.degree(node)
|
last_modified = node_data.get('last_modified', current_time)
|
||||||
|
|
||||||
# 获取节点的内容条数
|
if current_time - last_modified > 3600*24: # test
|
||||||
memory_items = self.memory_graph.G.nodes[node].get('memory_items', [])
|
memory_items = node_data.get('memory_items', [])
|
||||||
if not isinstance(memory_items, list):
|
if not isinstance(memory_items, list):
|
||||||
memory_items = [memory_items] if memory_items else []
|
memory_items = [memory_items] if memory_items else []
|
||||||
content_count = len(memory_items)
|
|
||||||
|
|
||||||
# 检查连接强度
|
if memory_items:
|
||||||
weak_connections = True
|
current_count = len(memory_items)
|
||||||
if connections > 1: # 只有当连接数大于1时才检查强度
|
removed_item = random.choice(memory_items)
|
||||||
for neighbor in self.memory_graph.G.neighbors(node):
|
memory_items.remove(removed_item)
|
||||||
strength = self.memory_graph.G[node][neighbor].get('strength', 1)
|
|
||||||
if strength > 2:
|
|
||||||
weak_connections = False
|
|
||||||
break
|
|
||||||
|
|
||||||
# 如果满足遗忘条件
|
if memory_items:
|
||||||
if (connections <= 1 and weak_connections) or content_count <= 2:
|
self.memory_graph.G.nodes[node]['memory_items'] = memory_items
|
||||||
removed_item = self.memory_graph.forget_topic(node)
|
self.memory_graph.G.nodes[node]['last_modified'] = current_time
|
||||||
if removed_item:
|
node_changes['reduced'] += 1
|
||||||
forgotten_nodes.append((node, removed_item))
|
logger.info(f"\033[1;33m[记忆减少]\033[0m {node} (记忆数量: {current_count} -> {len(memory_items)})")
|
||||||
print(f"遗忘节点 {node} 的记忆: {removed_item}")
|
|
||||||
|
|
||||||
# 同步到数据库
|
|
||||||
if forgotten_nodes:
|
|
||||||
self.sync_memory_to_db()
|
|
||||||
print(f"完成遗忘操作,共遗忘 {len(forgotten_nodes)} 个节点的记忆")
|
|
||||||
else:
|
else:
|
||||||
print("本次检查没有节点满足遗忘条件")
|
self.memory_graph.G.remove_node(node)
|
||||||
|
node_changes['removed'] += 1
|
||||||
|
logger.info(f"\033[1;31m[节点移除]\033[0m {node}")
|
||||||
|
|
||||||
|
if any(count > 0 for count in edge_changes.values()) or any(count > 0 for count in node_changes.values()):
|
||||||
|
self.sync_memory_to_db()
|
||||||
|
logger.info("\n遗忘操作统计:")
|
||||||
|
logger.info(f"连接变化: {edge_changes['weakened']} 个减弱, {edge_changes['removed']} 个移除")
|
||||||
|
logger.info(f"节点变化: {node_changes['reduced']} 个减少记忆, {node_changes['removed']} 个移除")
|
||||||
|
else:
|
||||||
|
logger.info("\n本次检查没有节点或连接满足遗忘条件")
|
||||||
|
|
||||||
async def merge_memory(self, topic):
|
async def merge_memory(self, topic):
|
||||||
"""
|
"""
|
||||||
@@ -478,11 +619,11 @@ class Hippocampus:
|
|||||||
|
|
||||||
# 拼接成文本
|
# 拼接成文本
|
||||||
merged_text = "\n".join(selected_memories)
|
merged_text = "\n".join(selected_memories)
|
||||||
print(f"\n[合并记忆] 话题: {topic}")
|
logger.debug(f"\n[合并记忆] 话题: {topic}")
|
||||||
print(f"选择的记忆:\n{merged_text}")
|
logger.debug(f"选择的记忆:\n{merged_text}")
|
||||||
|
|
||||||
# 使用memory_compress生成新的压缩记忆
|
# 使用memory_compress生成新的压缩记忆
|
||||||
compressed_memories = await self.memory_compress(selected_memories, 0.1)
|
compressed_memories, _ = await self.memory_compress(selected_memories, 0.1)
|
||||||
|
|
||||||
# 从原记忆列表中移除被选中的记忆
|
# 从原记忆列表中移除被选中的记忆
|
||||||
for memory in selected_memories:
|
for memory in selected_memories:
|
||||||
@@ -491,11 +632,11 @@ class Hippocampus:
|
|||||||
# 添加新的压缩记忆
|
# 添加新的压缩记忆
|
||||||
for _, compressed_memory in compressed_memories:
|
for _, compressed_memory in compressed_memories:
|
||||||
memory_items.append(compressed_memory)
|
memory_items.append(compressed_memory)
|
||||||
print(f"添加压缩记忆: {compressed_memory}")
|
logger.info(f"添加压缩记忆: {compressed_memory}")
|
||||||
|
|
||||||
# 更新节点的记忆项
|
# 更新节点的记忆项
|
||||||
self.memory_graph.G.nodes[topic]['memory_items'] = memory_items
|
self.memory_graph.G.nodes[topic]['memory_items'] = memory_items
|
||||||
print(f"完成记忆合并,当前记忆数量: {len(memory_items)}")
|
logger.debug(f"完成记忆合并,当前记忆数量: {len(memory_items)}")
|
||||||
|
|
||||||
async def operation_merge_memory(self, percentage=0.1):
|
async def operation_merge_memory(self, percentage=0.1):
|
||||||
"""
|
"""
|
||||||
@@ -521,22 +662,22 @@ class Hippocampus:
|
|||||||
|
|
||||||
# 如果内容数量超过100,进行合并
|
# 如果内容数量超过100,进行合并
|
||||||
if content_count > 100:
|
if content_count > 100:
|
||||||
print(f"\n检查节点: {node}, 当前记忆数量: {content_count}")
|
logger.debug(f"检查节点: {node}, 当前记忆数量: {content_count}")
|
||||||
await self.merge_memory(node)
|
await self.merge_memory(node)
|
||||||
merged_nodes.append(node)
|
merged_nodes.append(node)
|
||||||
|
|
||||||
# 同步到数据库
|
# 同步到数据库
|
||||||
if merged_nodes:
|
if merged_nodes:
|
||||||
self.sync_memory_to_db()
|
self.sync_memory_to_db()
|
||||||
print(f"\n完成记忆合并操作,共处理 {len(merged_nodes)} 个节点")
|
logger.debug(f"完成记忆合并操作,共处理 {len(merged_nodes)} 个节点")
|
||||||
else:
|
else:
|
||||||
print("\n本次检查没有需要合并的节点")
|
logger.debug("本次检查没有需要合并的节点")
|
||||||
|
|
||||||
def find_topic_llm(self,text, topic_num):
|
def find_topic_llm(self, text, topic_num):
|
||||||
prompt = f'这是一段文字:{text}。请你从这段话中总结出{topic_num}个关键的概念,可以是名词,动词,或者特定人物,帮我列出来,用逗号,隔开,尽可能精简。只需要列举{topic_num}个话题就好,不要有序号,不要告诉我其他内容。'
|
prompt = f'这是一段文字:{text}。请你从这段话中总结出{topic_num}个关键的概念,可以是名词,动词,或者特定人物,帮我列出来,用逗号,隔开,尽可能精简。只需要列举{topic_num}个话题就好,不要有序号,不要告诉我其他内容。'
|
||||||
return prompt
|
return prompt
|
||||||
|
|
||||||
def topic_what(self,text, topic, time_info):
|
def topic_what(self, text, topic, time_info):
|
||||||
prompt = f'这是一段文字,{time_info}:{text}。我想让你基于这段文字来概括"{topic}"这个概念,帮我总结成一句自然的话,可以包含时间和人物,以及具体的观点。只输出这句话就好'
|
prompt = f'这是一段文字,{time_info}:{text}。我想让你基于这段文字来概括"{topic}"这个概念,帮我总结成一句自然的话,可以包含时间和人物,以及具体的观点。只输出这句话就好'
|
||||||
return prompt
|
return prompt
|
||||||
|
|
||||||
@@ -551,7 +692,8 @@ class Hippocampus:
|
|||||||
"""
|
"""
|
||||||
topics_response = await self.llm_topic_judge.generate_response(self.find_topic_llm(text, 5))
|
topics_response = await self.llm_topic_judge.generate_response(self.find_topic_llm(text, 5))
|
||||||
# print(f"话题: {topics_response[0]}")
|
# print(f"话题: {topics_response[0]}")
|
||||||
topics = [topic.strip() for topic in topics_response[0].replace(",", ",").replace("、", ",").replace(" ", ",").split(",") if topic.strip()]
|
topics = [topic.strip() for topic in
|
||||||
|
topics_response[0].replace(",", ",").replace("、", ",").replace(" ", ",").split(",") if topic.strip()]
|
||||||
# print(f"话题: {topics}")
|
# print(f"话题: {topics}")
|
||||||
|
|
||||||
return topics
|
return topics
|
||||||
@@ -624,7 +766,7 @@ class Hippocampus:
|
|||||||
|
|
||||||
async def memory_activate_value(self, text: str, max_topics: int = 5, similarity_threshold: float = 0.3) -> int:
|
async def memory_activate_value(self, text: str, max_topics: int = 5, similarity_threshold: float = 0.3) -> int:
|
||||||
"""计算输入文本对记忆的激活程度"""
|
"""计算输入文本对记忆的激活程度"""
|
||||||
print(f"\033[1;32m[记忆激活]\033[0m 识别主题: {await self._identify_topics(text)}")
|
logger.info(f"识别主题: {await self._identify_topics(text)}")
|
||||||
|
|
||||||
# 识别主题
|
# 识别主题
|
||||||
identified_topics = await self._identify_topics(text)
|
identified_topics = await self._identify_topics(text)
|
||||||
@@ -655,7 +797,8 @@ class Hippocampus:
|
|||||||
penalty = 1.0 / (1 + math.log(content_count + 1))
|
penalty = 1.0 / (1 + math.log(content_count + 1))
|
||||||
|
|
||||||
activation = int(score * 50 * penalty)
|
activation = int(score * 50 * penalty)
|
||||||
print(f"\033[1;32m[记忆激活]\033[0m 单主题「{topic}」- 相似度: {score:.3f}, 内容数: {content_count}, 激活值: {activation}")
|
logger.info(
|
||||||
|
f"[记忆激活]单主题「{topic}」- 相似度: {score:.3f}, 内容数: {content_count}, 激活值: {activation}")
|
||||||
return activation
|
return activation
|
||||||
|
|
||||||
# 计算关键词匹配率,同时考虑内容数量
|
# 计算关键词匹配率,同时考虑内容数量
|
||||||
@@ -682,7 +825,8 @@ class Hippocampus:
|
|||||||
matched_topics.add(input_topic)
|
matched_topics.add(input_topic)
|
||||||
adjusted_sim = sim * penalty
|
adjusted_sim = sim * penalty
|
||||||
topic_similarities[input_topic] = max(topic_similarities.get(input_topic, 0), adjusted_sim)
|
topic_similarities[input_topic] = max(topic_similarities.get(input_topic, 0), adjusted_sim)
|
||||||
print(f"\033[1;32m[记忆激活]\033[0m 主题「{input_topic}」-> 「{memory_topic}」(内容数: {content_count}, 相似度: {adjusted_sim:.3f})")
|
logger.info(
|
||||||
|
f"[记忆激活]主题「{input_topic}」-> 「{memory_topic}」(内容数: {content_count}, 相似度: {adjusted_sim:.3f})")
|
||||||
|
|
||||||
# 计算主题匹配率和平均相似度
|
# 计算主题匹配率和平均相似度
|
||||||
topic_match = len(matched_topics) / len(identified_topics)
|
topic_match = len(matched_topics) / len(identified_topics)
|
||||||
@@ -690,11 +834,13 @@ class Hippocampus:
|
|||||||
|
|
||||||
# 计算最终激活值
|
# 计算最终激活值
|
||||||
activation = int((topic_match + average_similarities) / 2 * 100)
|
activation = int((topic_match + average_similarities) / 2 * 100)
|
||||||
print(f"\033[1;32m[记忆激活]\033[0m 匹配率: {topic_match:.3f}, 平均相似度: {average_similarities:.3f}, 激活值: {activation}")
|
logger.info(
|
||||||
|
f"[记忆激活]匹配率: {topic_match:.3f}, 平均相似度: {average_similarities:.3f}, 激活值: {activation}")
|
||||||
|
|
||||||
return activation
|
return activation
|
||||||
|
|
||||||
async def get_relevant_memories(self, text: str, max_topics: int = 5, similarity_threshold: float = 0.4, max_memory_num: int = 5) -> list:
|
async def get_relevant_memories(self, text: str, max_topics: int = 5, similarity_threshold: float = 0.4,
|
||||||
|
max_memory_num: int = 5) -> list:
|
||||||
"""根据输入文本获取相关的记忆内容"""
|
"""根据输入文本获取相关的记忆内容"""
|
||||||
# 识别主题
|
# 识别主题
|
||||||
identified_topics = await self._identify_topics(text)
|
identified_topics = await self._identify_topics(text)
|
||||||
@@ -716,8 +862,8 @@ class Hippocampus:
|
|||||||
first_layer, _ = self.memory_graph.get_related_item(topic, depth=1)
|
first_layer, _ = self.memory_graph.get_related_item(topic, depth=1)
|
||||||
if first_layer:
|
if first_layer:
|
||||||
# 如果记忆条数超过限制,随机选择指定数量的记忆
|
# 如果记忆条数超过限制,随机选择指定数量的记忆
|
||||||
if len(first_layer) > max_memory_num/2:
|
if len(first_layer) > max_memory_num / 2:
|
||||||
first_layer = random.sample(first_layer, max_memory_num//2)
|
first_layer = random.sample(first_layer, max_memory_num // 2)
|
||||||
# 为每条记忆添加来源主题和相似度信息
|
# 为每条记忆添加来源主题和相似度信息
|
||||||
for memory in first_layer:
|
for memory in first_layer:
|
||||||
relevant_memories.append({
|
relevant_memories.append({
|
||||||
@@ -740,28 +886,17 @@ def segment_text(text):
|
|||||||
seg_text = list(jieba.cut(text))
|
seg_text = list(jieba.cut(text))
|
||||||
return seg_text
|
return seg_text
|
||||||
|
|
||||||
|
|
||||||
from nonebot import get_driver
|
|
||||||
|
|
||||||
driver = get_driver()
|
driver = get_driver()
|
||||||
config = driver.config
|
config = driver.config
|
||||||
|
|
||||||
start_time = time.time()
|
start_time = time.time()
|
||||||
|
|
||||||
Database.initialize(
|
# 创建记忆图
|
||||||
host= config.MONGODB_HOST,
|
|
||||||
port= config.MONGODB_PORT,
|
|
||||||
db_name= config.DATABASE_NAME,
|
|
||||||
username= config.MONGODB_USERNAME,
|
|
||||||
password= config.MONGODB_PASSWORD,
|
|
||||||
auth_source=config.MONGODB_AUTH_SOURCE
|
|
||||||
)
|
|
||||||
#创建记忆图
|
|
||||||
memory_graph = Memory_graph()
|
memory_graph = Memory_graph()
|
||||||
#创建海马体
|
# 创建海马体
|
||||||
hippocampus = Hippocampus(memory_graph)
|
hippocampus = Hippocampus(memory_graph)
|
||||||
#从数据库加载记忆图
|
# 从数据库加载记忆图
|
||||||
hippocampus.sync_memory_from_db()
|
hippocampus.sync_memory_from_db()
|
||||||
|
|
||||||
end_time = time.time()
|
end_time = time.time()
|
||||||
print(f"\033[32m[加载海马体耗时: {end_time - start_time:.2f} 秒]\033[0m")
|
logger.success(f"加载海马体耗时: {end_time - start_time:.2f} 秒")
|
||||||
|
|||||||
@@ -10,14 +10,16 @@ from pathlib import Path
|
|||||||
|
|
||||||
import matplotlib.pyplot as plt
|
import matplotlib.pyplot as plt
|
||||||
import networkx as nx
|
import networkx as nx
|
||||||
import pymongo
|
|
||||||
from dotenv import load_dotenv
|
from dotenv import load_dotenv
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
import jieba
|
import jieba
|
||||||
|
|
||||||
# from chat.config import global_config
|
# from chat.config import global_config
|
||||||
sys.path.append("C:/GitHub/MaiMBot") # 添加项目根目录到 Python 路径
|
# 添加项目根目录到 Python 路径
|
||||||
from src.common.database import Database
|
root_path = os.path.abspath(os.path.join(os.path.dirname(__file__), "../../.."))
|
||||||
|
sys.path.append(root_path)
|
||||||
|
|
||||||
|
from src.common.database import db
|
||||||
from src.plugins.memory_system.offline_llm import LLMModel
|
from src.plugins.memory_system.offline_llm import LLMModel
|
||||||
|
|
||||||
# 获取当前文件的目录
|
# 获取当前文件的目录
|
||||||
@@ -35,45 +37,6 @@ else:
|
|||||||
logger.warning(f"未找到环境变量文件: {env_path}")
|
logger.warning(f"未找到环境变量文件: {env_path}")
|
||||||
logger.info("将使用默认配置")
|
logger.info("将使用默认配置")
|
||||||
|
|
||||||
class Database:
|
|
||||||
_instance = None
|
|
||||||
db = None
|
|
||||||
|
|
||||||
@classmethod
|
|
||||||
def get_instance(cls):
|
|
||||||
if cls._instance is None:
|
|
||||||
cls._instance = cls()
|
|
||||||
return cls._instance
|
|
||||||
|
|
||||||
def __init__(self):
|
|
||||||
if not Database.db:
|
|
||||||
Database.initialize(
|
|
||||||
host=os.getenv("MONGODB_HOST"),
|
|
||||||
port=int(os.getenv("MONGODB_PORT")),
|
|
||||||
db_name=os.getenv("DATABASE_NAME"),
|
|
||||||
username=os.getenv("MONGODB_USERNAME"),
|
|
||||||
password=os.getenv("MONGODB_PASSWORD"),
|
|
||||||
auth_source=os.getenv("MONGODB_AUTH_SOURCE")
|
|
||||||
)
|
|
||||||
|
|
||||||
@classmethod
|
|
||||||
def initialize(cls, host, port, db_name, username=None, password=None, auth_source="admin"):
|
|
||||||
try:
|
|
||||||
if username and password:
|
|
||||||
uri = f"mongodb://{username}:{password}@{host}:{port}/{db_name}?authSource={auth_source}"
|
|
||||||
else:
|
|
||||||
uri = f"mongodb://{host}:{port}"
|
|
||||||
|
|
||||||
client = pymongo.MongoClient(uri)
|
|
||||||
cls.db = client[db_name]
|
|
||||||
# 测试连接
|
|
||||||
client.server_info()
|
|
||||||
logger.success("MongoDB连接成功!")
|
|
||||||
|
|
||||||
except Exception as e:
|
|
||||||
logger.error(f"初始化MongoDB失败: {str(e)}")
|
|
||||||
raise
|
|
||||||
|
|
||||||
def calculate_information_content(text):
|
def calculate_information_content(text):
|
||||||
"""计算文本的信息量(熵)"""
|
"""计算文本的信息量(熵)"""
|
||||||
char_count = Counter(text)
|
char_count = Counter(text)
|
||||||
@@ -86,20 +49,20 @@ def calculate_information_content(text):
|
|||||||
|
|
||||||
return entropy
|
return entropy
|
||||||
|
|
||||||
def get_cloest_chat_from_db(db, length: int, timestamp: str):
|
def get_closest_chat_from_db(length: int, timestamp: str):
|
||||||
"""从数据库中获取最接近指定时间戳的聊天记录,并记录读取次数
|
"""从数据库中获取最接近指定时间戳的聊天记录,并记录读取次数
|
||||||
|
|
||||||
Returns:
|
Returns:
|
||||||
list: 消息记录字典列表,每个字典包含消息内容和时间信息
|
list: 消息记录字典列表,每个字典包含消息内容和时间信息
|
||||||
"""
|
"""
|
||||||
chat_records = []
|
chat_records = []
|
||||||
closest_record = db.db.messages.find_one({"time": {"$lte": timestamp}}, sort=[('time', -1)])
|
closest_record = db.messages.find_one({"time": {"$lte": timestamp}}, sort=[('time', -1)])
|
||||||
|
|
||||||
if closest_record and closest_record.get('memorized', 0) < 4:
|
if closest_record and closest_record.get('memorized', 0) < 4:
|
||||||
closest_time = closest_record['time']
|
closest_time = closest_record['time']
|
||||||
group_id = closest_record['group_id']
|
group_id = closest_record['group_id']
|
||||||
# 获取该时间戳之后的length条消息,且groupid相同
|
# 获取该时间戳之后的length条消息,且groupid相同
|
||||||
records = list(db.db.messages.find(
|
records = list(db.messages.find(
|
||||||
{"time": {"$gt": closest_time}, "group_id": group_id}
|
{"time": {"$gt": closest_time}, "group_id": group_id}
|
||||||
).sort('time', 1).limit(length))
|
).sort('time', 1).limit(length))
|
||||||
|
|
||||||
@@ -111,7 +74,7 @@ def get_cloest_chat_from_db(db, length: int, timestamp: str):
|
|||||||
return ''
|
return ''
|
||||||
|
|
||||||
# 更新memorized值
|
# 更新memorized值
|
||||||
db.db.messages.update_one(
|
db.messages.update_one(
|
||||||
{"_id": record["_id"]},
|
{"_id": record["_id"]},
|
||||||
{"$set": {"memorized": current_memorized + 1}}
|
{"$set": {"memorized": current_memorized + 1}}
|
||||||
)
|
)
|
||||||
@@ -128,7 +91,6 @@ def get_cloest_chat_from_db(db, length: int, timestamp: str):
|
|||||||
class Memory_graph:
|
class Memory_graph:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.G = nx.Graph() # 使用 networkx 的图结构
|
self.G = nx.Graph() # 使用 networkx 的图结构
|
||||||
self.db = Database.get_instance()
|
|
||||||
|
|
||||||
def connect_dot(self, concept1, concept2):
|
def connect_dot(self, concept1, concept2):
|
||||||
# 如果边已存在,增加 strength
|
# 如果边已存在,增加 strength
|
||||||
@@ -223,19 +185,19 @@ class Hippocampus:
|
|||||||
# 短期:1h 中期:4h 长期:24h
|
# 短期:1h 中期:4h 长期:24h
|
||||||
for _ in range(time_frequency.get('near')):
|
for _ in range(time_frequency.get('near')):
|
||||||
random_time = current_timestamp - random.randint(1, 3600*4)
|
random_time = current_timestamp - random.randint(1, 3600*4)
|
||||||
messages = get_cloest_chat_from_db(db=self.memory_graph.db, length=chat_size, timestamp=random_time)
|
messages = get_closest_chat_from_db(length=chat_size, timestamp=random_time)
|
||||||
if messages:
|
if messages:
|
||||||
chat_samples.append(messages)
|
chat_samples.append(messages)
|
||||||
|
|
||||||
for _ in range(time_frequency.get('mid')):
|
for _ in range(time_frequency.get('mid')):
|
||||||
random_time = current_timestamp - random.randint(3600*4, 3600*24)
|
random_time = current_timestamp - random.randint(3600*4, 3600*24)
|
||||||
messages = get_cloest_chat_from_db(db=self.memory_graph.db, length=chat_size, timestamp=random_time)
|
messages = get_closest_chat_from_db(length=chat_size, timestamp=random_time)
|
||||||
if messages:
|
if messages:
|
||||||
chat_samples.append(messages)
|
chat_samples.append(messages)
|
||||||
|
|
||||||
for _ in range(time_frequency.get('far')):
|
for _ in range(time_frequency.get('far')):
|
||||||
random_time = current_timestamp - random.randint(3600*24, 3600*24*7)
|
random_time = current_timestamp - random.randint(3600*24, 3600*24*7)
|
||||||
messages = get_cloest_chat_from_db(db=self.memory_graph.db, length=chat_size, timestamp=random_time)
|
messages = get_closest_chat_from_db(length=chat_size, timestamp=random_time)
|
||||||
if messages:
|
if messages:
|
||||||
chat_samples.append(messages)
|
chat_samples.append(messages)
|
||||||
|
|
||||||
@@ -360,7 +322,7 @@ class Hippocampus:
|
|||||||
self.memory_graph.G.clear()
|
self.memory_graph.G.clear()
|
||||||
|
|
||||||
# 从数据库加载所有节点
|
# 从数据库加载所有节点
|
||||||
nodes = self.memory_graph.db.db.graph_data.nodes.find()
|
nodes = db.graph_data.nodes.find()
|
||||||
for node in nodes:
|
for node in nodes:
|
||||||
concept = node['concept']
|
concept = node['concept']
|
||||||
memory_items = node.get('memory_items', [])
|
memory_items = node.get('memory_items', [])
|
||||||
@@ -371,7 +333,7 @@ class Hippocampus:
|
|||||||
self.memory_graph.G.add_node(concept, memory_items=memory_items)
|
self.memory_graph.G.add_node(concept, memory_items=memory_items)
|
||||||
|
|
||||||
# 从数据库加载所有边
|
# 从数据库加载所有边
|
||||||
edges = self.memory_graph.db.db.graph_data.edges.find()
|
edges = db.graph_data.edges.find()
|
||||||
for edge in edges:
|
for edge in edges:
|
||||||
source = edge['source']
|
source = edge['source']
|
||||||
target = edge['target']
|
target = edge['target']
|
||||||
@@ -408,7 +370,7 @@ class Hippocampus:
|
|||||||
使用特征值(哈希值)快速判断是否需要更新
|
使用特征值(哈希值)快速判断是否需要更新
|
||||||
"""
|
"""
|
||||||
# 获取数据库中所有节点和内存中所有节点
|
# 获取数据库中所有节点和内存中所有节点
|
||||||
db_nodes = list(self.memory_graph.db.db.graph_data.nodes.find())
|
db_nodes = list(db.graph_data.nodes.find())
|
||||||
memory_nodes = list(self.memory_graph.G.nodes(data=True))
|
memory_nodes = list(self.memory_graph.G.nodes(data=True))
|
||||||
|
|
||||||
# 转换数据库节点为字典格式,方便查找
|
# 转换数据库节点为字典格式,方便查找
|
||||||
@@ -431,7 +393,7 @@ class Hippocampus:
|
|||||||
'memory_items': memory_items,
|
'memory_items': memory_items,
|
||||||
'hash': memory_hash
|
'hash': memory_hash
|
||||||
}
|
}
|
||||||
self.memory_graph.db.db.graph_data.nodes.insert_one(node_data)
|
db.graph_data.nodes.insert_one(node_data)
|
||||||
else:
|
else:
|
||||||
# 获取数据库中节点的特征值
|
# 获取数据库中节点的特征值
|
||||||
db_node = db_nodes_dict[concept]
|
db_node = db_nodes_dict[concept]
|
||||||
@@ -440,7 +402,7 @@ class Hippocampus:
|
|||||||
# 如果特征值不同,则更新节点
|
# 如果特征值不同,则更新节点
|
||||||
if db_hash != memory_hash:
|
if db_hash != memory_hash:
|
||||||
# logger.info(f"更新节点内容: {concept}")
|
# logger.info(f"更新节点内容: {concept}")
|
||||||
self.memory_graph.db.db.graph_data.nodes.update_one(
|
db.graph_data.nodes.update_one(
|
||||||
{'concept': concept},
|
{'concept': concept},
|
||||||
{'$set': {
|
{'$set': {
|
||||||
'memory_items': memory_items,
|
'memory_items': memory_items,
|
||||||
@@ -453,10 +415,10 @@ class Hippocampus:
|
|||||||
for db_node in db_nodes:
|
for db_node in db_nodes:
|
||||||
if db_node['concept'] not in memory_concepts:
|
if db_node['concept'] not in memory_concepts:
|
||||||
# logger.info(f"删除多余节点: {db_node['concept']}")
|
# logger.info(f"删除多余节点: {db_node['concept']}")
|
||||||
self.memory_graph.db.db.graph_data.nodes.delete_one({'concept': db_node['concept']})
|
db.graph_data.nodes.delete_one({'concept': db_node['concept']})
|
||||||
|
|
||||||
# 处理边的信息
|
# 处理边的信息
|
||||||
db_edges = list(self.memory_graph.db.db.graph_data.edges.find())
|
db_edges = list(db.graph_data.edges.find())
|
||||||
memory_edges = list(self.memory_graph.G.edges())
|
memory_edges = list(self.memory_graph.G.edges())
|
||||||
|
|
||||||
# 创建边的哈希值字典
|
# 创建边的哈希值字典
|
||||||
@@ -482,12 +444,12 @@ class Hippocampus:
|
|||||||
'num': 1,
|
'num': 1,
|
||||||
'hash': edge_hash
|
'hash': edge_hash
|
||||||
}
|
}
|
||||||
self.memory_graph.db.db.graph_data.edges.insert_one(edge_data)
|
db.graph_data.edges.insert_one(edge_data)
|
||||||
else:
|
else:
|
||||||
# 检查边的特征值是否变化
|
# 检查边的特征值是否变化
|
||||||
if db_edge_dict[edge_key]['hash'] != edge_hash:
|
if db_edge_dict[edge_key]['hash'] != edge_hash:
|
||||||
logger.info(f"更新边: {source} - {target}")
|
logger.info(f"更新边: {source} - {target}")
|
||||||
self.memory_graph.db.db.graph_data.edges.update_one(
|
db.graph_data.edges.update_one(
|
||||||
{'source': source, 'target': target},
|
{'source': source, 'target': target},
|
||||||
{'$set': {'hash': edge_hash}}
|
{'$set': {'hash': edge_hash}}
|
||||||
)
|
)
|
||||||
@@ -498,7 +460,7 @@ class Hippocampus:
|
|||||||
if edge_key not in memory_edge_set:
|
if edge_key not in memory_edge_set:
|
||||||
source, target = edge_key
|
source, target = edge_key
|
||||||
logger.info(f"删除多余边: {source} - {target}")
|
logger.info(f"删除多余边: {source} - {target}")
|
||||||
self.memory_graph.db.db.graph_data.edges.delete_one({
|
db.graph_data.edges.delete_one({
|
||||||
'source': source,
|
'source': source,
|
||||||
'target': target
|
'target': target
|
||||||
})
|
})
|
||||||
@@ -524,9 +486,9 @@ class Hippocampus:
|
|||||||
topic: 要删除的节点概念
|
topic: 要删除的节点概念
|
||||||
"""
|
"""
|
||||||
# 删除节点
|
# 删除节点
|
||||||
self.memory_graph.db.db.graph_data.nodes.delete_one({'concept': topic})
|
db.graph_data.nodes.delete_one({'concept': topic})
|
||||||
# 删除所有涉及该节点的边
|
# 删除所有涉及该节点的边
|
||||||
self.memory_graph.db.db.graph_data.edges.delete_many({
|
db.graph_data.edges.delete_many({
|
||||||
'$or': [
|
'$or': [
|
||||||
{'source': topic},
|
{'source': topic},
|
||||||
{'target': topic}
|
{'target': topic}
|
||||||
@@ -743,7 +705,7 @@ class Hippocampus:
|
|||||||
|
|
||||||
async def memory_activate_value(self, text: str, max_topics: int = 5, similarity_threshold: float = 0.3) -> int:
|
async def memory_activate_value(self, text: str, max_topics: int = 5, similarity_threshold: float = 0.3) -> int:
|
||||||
"""计算输入文本对记忆的激活程度"""
|
"""计算输入文本对记忆的激活程度"""
|
||||||
print(f"\033[1;32m[记忆激活]\033[0m 识别主题: {await self._identify_topics(text)}")
|
logger.info(f"[记忆激活]识别主题: {await self._identify_topics(text)}")
|
||||||
|
|
||||||
identified_topics = await self._identify_topics(text)
|
identified_topics = await self._identify_topics(text)
|
||||||
if not identified_topics:
|
if not identified_topics:
|
||||||
@@ -939,9 +901,6 @@ def visualize_graph_lite(memory_graph: Memory_graph, color_by_memory: bool = Fal
|
|||||||
plt.show()
|
plt.show()
|
||||||
|
|
||||||
async def main():
|
async def main():
|
||||||
# 初始化数据库
|
|
||||||
logger.info("正在初始化数据库连接...")
|
|
||||||
db = Database.get_instance()
|
|
||||||
start_time = time.time()
|
start_time = time.time()
|
||||||
|
|
||||||
test_pare = {'do_build_memory':False,'do_forget_topic':False,'do_visualize_graph':True,'do_query':False,'do_merge_memory':False}
|
test_pare = {'do_build_memory':False,'do_forget_topic':False,'do_visualize_graph':True,'do_query':False,'do_merge_memory':False}
|
||||||
@@ -1008,9 +967,6 @@ async def main():
|
|||||||
else:
|
else:
|
||||||
print("未找到相关记忆。")
|
print("未找到相关记忆。")
|
||||||
|
|
||||||
|
|
||||||
if __name__ == "__main__":
|
if __name__ == "__main__":
|
||||||
import asyncio
|
import asyncio
|
||||||
asyncio.run(main())
|
asyncio.run(main())
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
1168
src/plugins/memory_system/memory_test1.py
Normal file
@@ -7,10 +7,11 @@ from typing import Tuple, Union
|
|||||||
import aiohttp
|
import aiohttp
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
from nonebot import get_driver
|
from nonebot import get_driver
|
||||||
|
import base64
|
||||||
from ...common.database import Database
|
from PIL import Image
|
||||||
|
import io
|
||||||
|
from ...common.database import db
|
||||||
from ..chat.config import global_config
|
from ..chat.config import global_config
|
||||||
from ..chat.utils_image import compress_base64_image_by_scale
|
|
||||||
|
|
||||||
driver = get_driver()
|
driver = get_driver()
|
||||||
config = driver.config
|
config = driver.config
|
||||||
@@ -33,19 +34,18 @@ class LLM_request:
|
|||||||
self.pri_out = model.get("pri_out", 0)
|
self.pri_out = model.get("pri_out", 0)
|
||||||
|
|
||||||
# 获取数据库实例
|
# 获取数据库实例
|
||||||
self.db = Database.get_instance()
|
|
||||||
self._init_database()
|
self._init_database()
|
||||||
|
|
||||||
def _init_database(self):
|
def _init_database(self):
|
||||||
"""初始化数据库集合"""
|
"""初始化数据库集合"""
|
||||||
try:
|
try:
|
||||||
# 创建llm_usage集合的索引
|
# 创建llm_usage集合的索引
|
||||||
self.db.db.llm_usage.create_index([("timestamp", 1)])
|
db.llm_usage.create_index([("timestamp", 1)])
|
||||||
self.db.db.llm_usage.create_index([("model_name", 1)])
|
db.llm_usage.create_index([("model_name", 1)])
|
||||||
self.db.db.llm_usage.create_index([("user_id", 1)])
|
db.llm_usage.create_index([("user_id", 1)])
|
||||||
self.db.db.llm_usage.create_index([("request_type", 1)])
|
db.llm_usage.create_index([("request_type", 1)])
|
||||||
except Exception as e:
|
except Exception:
|
||||||
logger.error(f"创建数据库索引失败: {e}")
|
logger.error("创建数据库索引失败")
|
||||||
|
|
||||||
def _record_usage(self, prompt_tokens: int, completion_tokens: int, total_tokens: int,
|
def _record_usage(self, prompt_tokens: int, completion_tokens: int, total_tokens: int,
|
||||||
user_id: str = "system", request_type: str = "chat",
|
user_id: str = "system", request_type: str = "chat",
|
||||||
@@ -72,15 +72,15 @@ class LLM_request:
|
|||||||
"status": "success",
|
"status": "success",
|
||||||
"timestamp": datetime.now()
|
"timestamp": datetime.now()
|
||||||
}
|
}
|
||||||
self.db.db.llm_usage.insert_one(usage_data)
|
db.llm_usage.insert_one(usage_data)
|
||||||
logger.info(
|
logger.info(
|
||||||
f"Token使用情况 - 模型: {self.model_name}, "
|
f"Token使用情况 - 模型: {self.model_name}, "
|
||||||
f"用户: {user_id}, 类型: {request_type}, "
|
f"用户: {user_id}, 类型: {request_type}, "
|
||||||
f"提示词: {prompt_tokens}, 完成: {completion_tokens}, "
|
f"提示词: {prompt_tokens}, 完成: {completion_tokens}, "
|
||||||
f"总计: {total_tokens}"
|
f"总计: {total_tokens}"
|
||||||
)
|
)
|
||||||
except Exception as e:
|
except Exception:
|
||||||
logger.error(f"记录token使用情况失败: {e}")
|
logger.error("记录token使用情况失败")
|
||||||
|
|
||||||
def _calculate_cost(self, prompt_tokens: int, completion_tokens: int) -> float:
|
def _calculate_cost(self, prompt_tokens: int, completion_tokens: int) -> float:
|
||||||
"""计算API调用成本
|
"""计算API调用成本
|
||||||
@@ -103,6 +103,7 @@ class LLM_request:
|
|||||||
endpoint: str,
|
endpoint: str,
|
||||||
prompt: str = None,
|
prompt: str = None,
|
||||||
image_base64: str = None,
|
image_base64: str = None,
|
||||||
|
image_format: str = None,
|
||||||
payload: dict = None,
|
payload: dict = None,
|
||||||
retry_policy: dict = None,
|
retry_policy: dict = None,
|
||||||
response_handler: callable = None,
|
response_handler: callable = None,
|
||||||
@@ -114,6 +115,7 @@ class LLM_request:
|
|||||||
endpoint: API端点路径 (如 "chat/completions")
|
endpoint: API端点路径 (如 "chat/completions")
|
||||||
prompt: prompt文本
|
prompt: prompt文本
|
||||||
image_base64: 图片的base64编码
|
image_base64: 图片的base64编码
|
||||||
|
image_format: 图片格式
|
||||||
payload: 请求体数据
|
payload: 请求体数据
|
||||||
retry_policy: 自定义重试策略
|
retry_policy: 自定义重试策略
|
||||||
response_handler: 自定义响应处理器
|
response_handler: 自定义响应处理器
|
||||||
@@ -130,7 +132,7 @@ class LLM_request:
|
|||||||
# 常见Error Code Mapping
|
# 常见Error Code Mapping
|
||||||
error_code_mapping = {
|
error_code_mapping = {
|
||||||
400: "参数不正确",
|
400: "参数不正确",
|
||||||
401: "API key 错误,认证失败",
|
401: "API key 错误,认证失败,请检查/config/bot_config.toml和.env.prod中的配置是否正确哦~",
|
||||||
402: "账号余额不足",
|
402: "账号余额不足",
|
||||||
403: "需要实名,或余额不足",
|
403: "需要实名,或余额不足",
|
||||||
404: "Not Found",
|
404: "Not Found",
|
||||||
@@ -140,17 +142,17 @@ class LLM_request:
|
|||||||
}
|
}
|
||||||
|
|
||||||
api_url = f"{self.base_url.rstrip('/')}/{endpoint.lstrip('/')}"
|
api_url = f"{self.base_url.rstrip('/')}/{endpoint.lstrip('/')}"
|
||||||
#判断是否为流式
|
# 判断是否为流式
|
||||||
stream_mode = self.params.get("stream", False)
|
stream_mode = self.params.get("stream", False)
|
||||||
if self.params.get("stream", False) is True:
|
if self.params.get("stream", False) is True:
|
||||||
logger.info(f"进入流式输出模式,发送请求到URL: {api_url}")
|
logger.debug(f"进入流式输出模式,发送请求到URL: {api_url}")
|
||||||
else:
|
else:
|
||||||
logger.info(f"发送请求到URL: {api_url}")
|
logger.debug(f"发送请求到URL: {api_url}")
|
||||||
logger.info(f"使用模型: {self.model_name}")
|
logger.info(f"使用模型: {self.model_name}")
|
||||||
|
|
||||||
# 构建请求体
|
# 构建请求体
|
||||||
if image_base64:
|
if image_base64:
|
||||||
payload = await self._build_payload(prompt, image_base64)
|
payload = await self._build_payload(prompt, image_base64, image_format)
|
||||||
elif payload is None:
|
elif payload is None:
|
||||||
payload = await self._build_payload(prompt)
|
payload = await self._build_payload(prompt)
|
||||||
|
|
||||||
@@ -158,7 +160,7 @@ class LLM_request:
|
|||||||
try:
|
try:
|
||||||
# 使用上下文管理器处理会话
|
# 使用上下文管理器处理会话
|
||||||
headers = await self._build_headers()
|
headers = await self._build_headers()
|
||||||
#似乎是openai流式必须要的东西,不过阿里云的qwq-plus加了这个没有影响
|
# 似乎是openai流式必须要的东西,不过阿里云的qwq-plus加了这个没有影响
|
||||||
if stream_mode:
|
if stream_mode:
|
||||||
headers["Accept"] = "text/event-stream"
|
headers["Accept"] = "text/event-stream"
|
||||||
|
|
||||||
@@ -171,7 +173,7 @@ class LLM_request:
|
|||||||
if response.status == 413:
|
if response.status == 413:
|
||||||
logger.warning("请求体过大,尝试压缩...")
|
logger.warning("请求体过大,尝试压缩...")
|
||||||
image_base64 = compress_base64_image_by_scale(image_base64)
|
image_base64 = compress_base64_image_by_scale(image_base64)
|
||||||
payload = await self._build_payload(prompt, image_base64)
|
payload = await self._build_payload(prompt, image_base64, image_format)
|
||||||
elif response.status in [500, 503]:
|
elif response.status in [500, 503]:
|
||||||
logger.error(f"错误码: {response.status} - {error_code_mapping.get(response.status)}")
|
logger.error(f"错误码: {response.status} - {error_code_mapping.get(response.status)}")
|
||||||
raise RuntimeError("服务器负载过高,模型恢复失败QAQ")
|
raise RuntimeError("服务器负载过高,模型恢复失败QAQ")
|
||||||
@@ -183,16 +185,21 @@ class LLM_request:
|
|||||||
elif response.status in policy["abort_codes"]:
|
elif response.status in policy["abort_codes"]:
|
||||||
logger.error(f"错误码: {response.status} - {error_code_mapping.get(response.status)}")
|
logger.error(f"错误码: {response.status} - {error_code_mapping.get(response.status)}")
|
||||||
if response.status == 403:
|
if response.status == 403:
|
||||||
# 尝试降级Pro模型
|
#只针对硅基流动的V3和R1进行降级处理
|
||||||
if self.model_name.startswith("Pro/") and self.base_url == "https://api.siliconflow.cn/v1/":
|
if self.model_name.startswith(
|
||||||
|
"Pro/deepseek-ai") and self.base_url == "https://api.siliconflow.cn/v1/":
|
||||||
old_model_name = self.model_name
|
old_model_name = self.model_name
|
||||||
self.model_name = self.model_name[4:] # 移除"Pro/"前缀
|
self.model_name = self.model_name[4:] # 移除"Pro/"前缀
|
||||||
logger.warning(f"检测到403错误,模型从 {old_model_name} 降级为 {self.model_name}")
|
logger.warning(f"检测到403错误,模型从 {old_model_name} 降级为 {self.model_name}")
|
||||||
|
|
||||||
# 对全局配置进行更新
|
# 对全局配置进行更新
|
||||||
if hasattr(global_config, 'llm_normal') and global_config.llm_normal.get('name') == old_model_name:
|
if global_config.llm_normal.get('name') == old_model_name:
|
||||||
global_config.llm_normal['name'] = self.model_name
|
global_config.llm_normal['name'] = self.model_name
|
||||||
logger.warning(f"已将全局配置中的 llm_normal 模型降级")
|
logger.warning(f"将全局配置中的 llm_normal 模型临时降级至{self.model_name}")
|
||||||
|
|
||||||
|
if global_config.llm_reasoning.get('name') == old_model_name:
|
||||||
|
global_config.llm_reasoning['name'] = self.model_name
|
||||||
|
logger.warning(f"将全局配置中的 llm_reasoning 模型临时降级至{self.model_name}")
|
||||||
|
|
||||||
# 更新payload中的模型名
|
# 更新payload中的模型名
|
||||||
if payload and 'model' in payload:
|
if payload and 'model' in payload:
|
||||||
@@ -206,8 +213,9 @@ class LLM_request:
|
|||||||
|
|
||||||
response.raise_for_status()
|
response.raise_for_status()
|
||||||
|
|
||||||
#将流式输出转化为非流式输出
|
# 将流式输出转化为非流式输出
|
||||||
if stream_mode:
|
if stream_mode:
|
||||||
|
flag_delta_content_finished = False
|
||||||
accumulated_content = ""
|
accumulated_content = ""
|
||||||
async for line_bytes in response.content:
|
async for line_bytes in response.content:
|
||||||
line = line_bytes.decode("utf-8").strip()
|
line = line_bytes.decode("utf-8").strip()
|
||||||
@@ -219,13 +227,25 @@ class LLM_request:
|
|||||||
break
|
break
|
||||||
try:
|
try:
|
||||||
chunk = json.loads(data_str)
|
chunk = json.loads(data_str)
|
||||||
|
if flag_delta_content_finished:
|
||||||
|
usage = chunk.get("usage", None) # 获取tokn用量
|
||||||
|
else:
|
||||||
delta = chunk["choices"][0]["delta"]
|
delta = chunk["choices"][0]["delta"]
|
||||||
delta_content = delta.get("content")
|
delta_content = delta.get("content")
|
||||||
if delta_content is None:
|
if delta_content is None:
|
||||||
delta_content = ""
|
delta_content = ""
|
||||||
accumulated_content += delta_content
|
accumulated_content += delta_content
|
||||||
except Exception as e:
|
# 检测流式输出文本是否结束
|
||||||
logger.error(f"解析流式输出错误: {e}")
|
finish_reason = chunk["choices"][0].get("finish_reason")
|
||||||
|
if finish_reason == "stop":
|
||||||
|
usage = chunk.get("usage", None)
|
||||||
|
if usage:
|
||||||
|
break
|
||||||
|
# 部分平台在文本输出结束前不会返回token用量,此时需要再获取一次chunk
|
||||||
|
flag_delta_content_finished = True
|
||||||
|
|
||||||
|
except Exception:
|
||||||
|
logger.exception("解析流式输出错误")
|
||||||
content = accumulated_content
|
content = accumulated_content
|
||||||
reasoning_content = ""
|
reasoning_content = ""
|
||||||
think_match = re.search(r'<think>(.*?)</think>', content, re.DOTALL)
|
think_match = re.search(r'<think>(.*?)</think>', content, re.DOTALL)
|
||||||
@@ -233,12 +253,15 @@ class LLM_request:
|
|||||||
reasoning_content = think_match.group(1).strip()
|
reasoning_content = think_match.group(1).strip()
|
||||||
content = re.sub(r'<think>.*?</think>', '', content, flags=re.DOTALL).strip()
|
content = re.sub(r'<think>.*?</think>', '', content, flags=re.DOTALL).strip()
|
||||||
# 构造一个伪result以便调用自定义响应处理器或默认处理器
|
# 构造一个伪result以便调用自定义响应处理器或默认处理器
|
||||||
result = {"choices": [{"message": {"content": content, "reasoning_content": reasoning_content}}]}
|
result = {
|
||||||
return response_handler(result) if response_handler else self._default_response_handler(result, user_id, request_type, endpoint)
|
"choices": [{"message": {"content": content, "reasoning_content": reasoning_content}}], "usage": usage}
|
||||||
|
return response_handler(result) if response_handler else self._default_response_handler(
|
||||||
|
result, user_id, request_type, endpoint)
|
||||||
else:
|
else:
|
||||||
result = await response.json()
|
result = await response.json()
|
||||||
# 使用自定义处理器或默认处理
|
# 使用自定义处理器或默认处理
|
||||||
return response_handler(result) if response_handler else self._default_response_handler(result, user_id, request_type, endpoint)
|
return response_handler(result) if response_handler else self._default_response_handler(
|
||||||
|
result, user_id, request_type, endpoint)
|
||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
if retry < policy["max_retries"] - 1:
|
if retry < policy["max_retries"] - 1:
|
||||||
@@ -253,7 +276,7 @@ class LLM_request:
|
|||||||
logger.error("达到最大重试次数,请求仍然失败")
|
logger.error("达到最大重试次数,请求仍然失败")
|
||||||
raise RuntimeError("达到最大重试次数,API请求仍然失败")
|
raise RuntimeError("达到最大重试次数,API请求仍然失败")
|
||||||
|
|
||||||
async def _transform_parameters(self, params: dict) ->dict:
|
async def _transform_parameters(self, params: dict) -> dict:
|
||||||
"""
|
"""
|
||||||
根据模型名称转换参数:
|
根据模型名称转换参数:
|
||||||
- 对于需要转换的OpenAI CoT系列模型(例如 "o3-mini"),删除 'temprature' 参数,
|
- 对于需要转换的OpenAI CoT系列模型(例如 "o3-mini"),删除 'temprature' 参数,
|
||||||
@@ -262,7 +285,8 @@ class LLM_request:
|
|||||||
# 复制一份参数,避免直接修改原始数据
|
# 复制一份参数,避免直接修改原始数据
|
||||||
new_params = dict(params)
|
new_params = dict(params)
|
||||||
# 定义需要转换的模型列表
|
# 定义需要转换的模型列表
|
||||||
models_needing_transformation = ["o3-mini", "o1-mini", "o1-preview", "o1-2024-12-17", "o1-preview-2024-09-12", "o3-mini-2025-01-31", "o1-mini-2024-09-12"]
|
models_needing_transformation = ["o3-mini", "o1-mini", "o1-preview", "o1-2024-12-17", "o1-preview-2024-09-12",
|
||||||
|
"o3-mini-2025-01-31", "o1-mini-2024-09-12"]
|
||||||
if self.model_name.lower() in models_needing_transformation:
|
if self.model_name.lower() in models_needing_transformation:
|
||||||
# 删除 'temprature' 参数(如果存在)
|
# 删除 'temprature' 参数(如果存在)
|
||||||
new_params.pop("temperature", None)
|
new_params.pop("temperature", None)
|
||||||
@@ -271,7 +295,7 @@ class LLM_request:
|
|||||||
new_params["max_completion_tokens"] = new_params.pop("max_tokens")
|
new_params["max_completion_tokens"] = new_params.pop("max_tokens")
|
||||||
return new_params
|
return new_params
|
||||||
|
|
||||||
async def _build_payload(self, prompt: str, image_base64: str = None) -> dict:
|
async def _build_payload(self, prompt: str, image_base64: str = None, image_format: str = None) -> dict:
|
||||||
"""构建请求体"""
|
"""构建请求体"""
|
||||||
# 复制一份参数,避免直接修改 self.params
|
# 复制一份参数,避免直接修改 self.params
|
||||||
params_copy = await self._transform_parameters(self.params)
|
params_copy = await self._transform_parameters(self.params)
|
||||||
@@ -283,7 +307,7 @@ class LLM_request:
|
|||||||
"role": "user",
|
"role": "user",
|
||||||
"content": [
|
"content": [
|
||||||
{"type": "text", "text": prompt},
|
{"type": "text", "text": prompt},
|
||||||
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_base64}"}}
|
{"type": "image_url", "image_url": {"url": f"data:image/{image_format.lower()};base64,{image_base64}"}}
|
||||||
]
|
]
|
||||||
}
|
}
|
||||||
],
|
],
|
||||||
@@ -298,11 +322,11 @@ class LLM_request:
|
|||||||
**params_copy
|
**params_copy
|
||||||
}
|
}
|
||||||
# 如果 payload 中依然存在 max_tokens 且需要转换,在这里进行再次检查
|
# 如果 payload 中依然存在 max_tokens 且需要转换,在这里进行再次检查
|
||||||
if self.model_name.lower() in ["o3-mini", "o1-mini", "o1-preview", "o1-2024-12-17", "o1-preview-2024-09-12", "o3-mini-2025-01-31", "o1-mini-2024-09-12"] and "max_tokens" in payload:
|
if self.model_name.lower() in ["o3-mini", "o1-mini", "o1-preview", "o1-2024-12-17", "o1-preview-2024-09-12",
|
||||||
|
"o3-mini-2025-01-31", "o1-mini-2024-09-12"] and "max_tokens" in payload:
|
||||||
payload["max_completion_tokens"] = payload.pop("max_tokens")
|
payload["max_completion_tokens"] = payload.pop("max_tokens")
|
||||||
return payload
|
return payload
|
||||||
|
|
||||||
|
|
||||||
def _default_response_handler(self, result: dict, user_id: str = "system",
|
def _default_response_handler(self, result: dict, user_id: str = "system",
|
||||||
request_type: str = "chat", endpoint: str = "/chat/completions") -> Tuple:
|
request_type: str = "chat", endpoint: str = "/chat/completions") -> Tuple:
|
||||||
"""默认响应解析"""
|
"""默认响应解析"""
|
||||||
@@ -349,7 +373,7 @@ class LLM_request:
|
|||||||
"""构建请求头"""
|
"""构建请求头"""
|
||||||
if no_key:
|
if no_key:
|
||||||
return {
|
return {
|
||||||
"Authorization": f"Bearer **********",
|
"Authorization": "Bearer **********",
|
||||||
"Content-Type": "application/json"
|
"Content-Type": "application/json"
|
||||||
}
|
}
|
||||||
else:
|
else:
|
||||||
@@ -368,13 +392,14 @@ class LLM_request:
|
|||||||
)
|
)
|
||||||
return content, reasoning_content
|
return content, reasoning_content
|
||||||
|
|
||||||
async def generate_response_for_image(self, prompt: str, image_base64: str) -> Tuple[str, str]:
|
async def generate_response_for_image(self, prompt: str, image_base64: str, image_format: str) -> Tuple[str, str]:
|
||||||
"""根据输入的提示和图片生成模型的异步响应"""
|
"""根据输入的提示和图片生成模型的异步响应"""
|
||||||
|
|
||||||
content, reasoning_content = await self._execute_request(
|
content, reasoning_content = await self._execute_request(
|
||||||
endpoint="/chat/completions",
|
endpoint="/chat/completions",
|
||||||
prompt=prompt,
|
prompt=prompt,
|
||||||
image_base64=image_base64
|
image_base64=image_base64,
|
||||||
|
image_format=image_format
|
||||||
)
|
)
|
||||||
return content, reasoning_content
|
return content, reasoning_content
|
||||||
|
|
||||||
@@ -404,6 +429,7 @@ class LLM_request:
|
|||||||
Returns:
|
Returns:
|
||||||
list: embedding向量,如果失败则返回None
|
list: embedding向量,如果失败则返回None
|
||||||
"""
|
"""
|
||||||
|
|
||||||
def embedding_handler(result):
|
def embedding_handler(result):
|
||||||
"""处理响应"""
|
"""处理响应"""
|
||||||
if "data" in result and len(result["data"]) > 0:
|
if "data" in result and len(result["data"]) > 0:
|
||||||
@@ -426,3 +452,77 @@ class LLM_request:
|
|||||||
)
|
)
|
||||||
return embedding
|
return embedding
|
||||||
|
|
||||||
|
def compress_base64_image_by_scale(base64_data: str, target_size: int = 0.8 * 1024 * 1024) -> str:
|
||||||
|
"""压缩base64格式的图片到指定大小
|
||||||
|
Args:
|
||||||
|
base64_data: base64编码的图片数据
|
||||||
|
target_size: 目标文件大小(字节),默认0.8MB
|
||||||
|
Returns:
|
||||||
|
str: 压缩后的base64图片数据
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
# 将base64转换为字节数据
|
||||||
|
image_data = base64.b64decode(base64_data)
|
||||||
|
|
||||||
|
# 如果已经小于目标大小,直接返回原图
|
||||||
|
if len(image_data) <= 2*1024*1024:
|
||||||
|
return base64_data
|
||||||
|
|
||||||
|
# 将字节数据转换为图片对象
|
||||||
|
img = Image.open(io.BytesIO(image_data))
|
||||||
|
|
||||||
|
# 获取原始尺寸
|
||||||
|
original_width, original_height = img.size
|
||||||
|
|
||||||
|
# 计算缩放比例
|
||||||
|
scale = min(1.0, (target_size / len(image_data)) ** 0.5)
|
||||||
|
|
||||||
|
# 计算新的尺寸
|
||||||
|
new_width = int(original_width * scale)
|
||||||
|
new_height = int(original_height * scale)
|
||||||
|
|
||||||
|
# 创建内存缓冲区
|
||||||
|
output_buffer = io.BytesIO()
|
||||||
|
|
||||||
|
# 如果是GIF,处理所有帧
|
||||||
|
if getattr(img, "is_animated", False):
|
||||||
|
frames = []
|
||||||
|
for frame_idx in range(img.n_frames):
|
||||||
|
img.seek(frame_idx)
|
||||||
|
new_frame = img.copy()
|
||||||
|
new_frame = new_frame.resize((new_width//2, new_height//2), Image.Resampling.LANCZOS) # 动图折上折
|
||||||
|
frames.append(new_frame)
|
||||||
|
|
||||||
|
# 保存到缓冲区
|
||||||
|
frames[0].save(
|
||||||
|
output_buffer,
|
||||||
|
format='GIF',
|
||||||
|
save_all=True,
|
||||||
|
append_images=frames[1:],
|
||||||
|
optimize=True,
|
||||||
|
duration=img.info.get('duration', 100),
|
||||||
|
loop=img.info.get('loop', 0)
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
# 处理静态图片
|
||||||
|
resized_img = img.resize((new_width, new_height), Image.Resampling.LANCZOS)
|
||||||
|
|
||||||
|
# 保存到缓冲区,保持原始格式
|
||||||
|
if img.format == 'PNG' and img.mode in ('RGBA', 'LA'):
|
||||||
|
resized_img.save(output_buffer, format='PNG', optimize=True)
|
||||||
|
else:
|
||||||
|
resized_img.save(output_buffer, format='JPEG', quality=95, optimize=True)
|
||||||
|
|
||||||
|
# 获取压缩后的数据并转换为base64
|
||||||
|
compressed_data = output_buffer.getvalue()
|
||||||
|
logger.success(f"压缩图片: {original_width}x{original_height} -> {new_width}x{new_height}")
|
||||||
|
logger.info(f"压缩前大小: {len(image_data)/1024:.1f}KB, 压缩后大小: {len(compressed_data)/1024:.1f}KB")
|
||||||
|
|
||||||
|
return base64.b64encode(compressed_data).decode('utf-8')
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"压缩图片失败: {str(e)}")
|
||||||
|
import traceback
|
||||||
|
logger.error(traceback.format_exc())
|
||||||
|
return base64_data
|
||||||
|
|
||||||
|
|||||||
@@ -4,7 +4,7 @@ import time
|
|||||||
from dataclasses import dataclass
|
from dataclasses import dataclass
|
||||||
|
|
||||||
from ..chat.config import global_config
|
from ..chat.config import global_config
|
||||||
|
from loguru import logger
|
||||||
|
|
||||||
@dataclass
|
@dataclass
|
||||||
class MoodState:
|
class MoodState:
|
||||||
@@ -210,7 +210,7 @@ class MoodManager:
|
|||||||
|
|
||||||
def print_mood_status(self) -> None:
|
def print_mood_status(self) -> None:
|
||||||
"""打印当前情绪状态"""
|
"""打印当前情绪状态"""
|
||||||
print(f"\033[1;35m[情绪状态]\033[0m 愉悦度: {self.current_mood.valence:.2f}, "
|
logger.info(f"[情绪状态]愉悦度: {self.current_mood.valence:.2f}, "
|
||||||
f"唤醒度: {self.current_mood.arousal:.2f}, "
|
f"唤醒度: {self.current_mood.arousal:.2f}, "
|
||||||
f"心情: {self.current_mood.text}")
|
f"心情: {self.current_mood.text}")
|
||||||
|
|
||||||
|
|||||||
@@ -1,3 +1,4 @@
|
|||||||
|
import os
|
||||||
import datetime
|
import datetime
|
||||||
import json
|
import json
|
||||||
from typing import Dict, Union
|
from typing import Dict, Union
|
||||||
@@ -7,28 +8,20 @@ from nonebot import get_driver
|
|||||||
|
|
||||||
from src.plugins.chat.config import global_config
|
from src.plugins.chat.config import global_config
|
||||||
|
|
||||||
from ...common.database import Database # 使用正确的导入语法
|
from ...common.database import db # 使用正确的导入语法
|
||||||
from ..models.utils_model import LLM_request
|
from ..models.utils_model import LLM_request
|
||||||
|
|
||||||
driver = get_driver()
|
driver = get_driver()
|
||||||
config = driver.config
|
config = driver.config
|
||||||
|
|
||||||
Database.initialize(
|
|
||||||
host=config.MONGODB_HOST,
|
|
||||||
port=int(config.MONGODB_PORT),
|
|
||||||
db_name=config.DATABASE_NAME,
|
|
||||||
username=config.MONGODB_USERNAME,
|
|
||||||
password=config.MONGODB_PASSWORD,
|
|
||||||
auth_source=config.MONGODB_AUTH_SOURCE
|
|
||||||
)
|
|
||||||
|
|
||||||
|
|
||||||
class ScheduleGenerator:
|
class ScheduleGenerator:
|
||||||
|
enable_output: bool = True
|
||||||
|
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
# 根据global_config.llm_normal这一字典配置指定模型
|
# 根据global_config.llm_normal这一字典配置指定模型
|
||||||
# self.llm_scheduler = LLMModel(model = global_config.llm_normal,temperature=0.9)
|
# self.llm_scheduler = LLMModel(model = global_config.llm_normal,temperature=0.9)
|
||||||
self.llm_scheduler = LLM_request(model=global_config.llm_normal, temperature=0.9)
|
self.llm_scheduler = LLM_request(model=global_config.llm_normal, temperature=0.9)
|
||||||
self.db = Database.get_instance()
|
|
||||||
self.today_schedule_text = ""
|
self.today_schedule_text = ""
|
||||||
self.today_schedule = {}
|
self.today_schedule = {}
|
||||||
self.tomorrow_schedule_text = ""
|
self.tomorrow_schedule_text = ""
|
||||||
@@ -42,43 +35,50 @@ class ScheduleGenerator:
|
|||||||
yesterday = datetime.datetime.now() - datetime.timedelta(days=1)
|
yesterday = datetime.datetime.now() - datetime.timedelta(days=1)
|
||||||
|
|
||||||
self.today_schedule_text, self.today_schedule = await self.generate_daily_schedule(target_date=today)
|
self.today_schedule_text, self.today_schedule = await self.generate_daily_schedule(target_date=today)
|
||||||
self.tomorrow_schedule_text, self.tomorrow_schedule = await self.generate_daily_schedule(target_date=tomorrow,
|
self.tomorrow_schedule_text, self.tomorrow_schedule = await self.generate_daily_schedule(
|
||||||
read_only=True)
|
target_date=tomorrow, read_only=True
|
||||||
|
)
|
||||||
self.yesterday_schedule_text, self.yesterday_schedule = await self.generate_daily_schedule(
|
self.yesterday_schedule_text, self.yesterday_schedule = await self.generate_daily_schedule(
|
||||||
target_date=yesterday, read_only=True)
|
target_date=yesterday, read_only=True
|
||||||
|
)
|
||||||
async def generate_daily_schedule(self, target_date: datetime.datetime = None, read_only: bool = False) -> Dict[
|
|
||||||
str, str]:
|
|
||||||
|
|
||||||
|
async def generate_daily_schedule(
|
||||||
|
self, target_date: datetime.datetime = None, read_only: bool = False
|
||||||
|
) -> Dict[str, str]:
|
||||||
date_str = target_date.strftime("%Y-%m-%d")
|
date_str = target_date.strftime("%Y-%m-%d")
|
||||||
weekday = target_date.strftime("%A")
|
weekday = target_date.strftime("%A")
|
||||||
|
|
||||||
schedule_text = str
|
schedule_text = str
|
||||||
|
|
||||||
existing_schedule = self.db.db.schedule.find_one({"date": date_str})
|
existing_schedule = db.schedule.find_one({"date": date_str})
|
||||||
if existing_schedule:
|
if existing_schedule:
|
||||||
logger.info(f"{date_str}的日程已存在:")
|
if self.enable_output:
|
||||||
|
logger.debug(f"{date_str}的日程已存在:")
|
||||||
schedule_text = existing_schedule["schedule"]
|
schedule_text = existing_schedule["schedule"]
|
||||||
# print(self.schedule_text)
|
# print(self.schedule_text)
|
||||||
|
|
||||||
elif read_only == False:
|
elif not read_only:
|
||||||
logger.info(f"{date_str}的日程不存在,准备生成新的日程。")
|
logger.debug(f"{date_str}的日程不存在,准备生成新的日程。")
|
||||||
prompt = f"""我是{global_config.BOT_NICKNAME},{global_config.PROMPT_SCHEDULE_GEN},请为我生成{date_str}({weekday})的日程安排,包括:""" + \
|
prompt = (
|
||||||
"""
|
f"""我是{global_config.BOT_NICKNAME},{global_config.PROMPT_SCHEDULE_GEN},请为我生成{date_str}({weekday})的日程安排,包括:"""
|
||||||
|
+ """
|
||||||
1. 早上的学习和工作安排
|
1. 早上的学习和工作安排
|
||||||
2. 下午的活动和任务
|
2. 下午的活动和任务
|
||||||
3. 晚上的计划和休息时间
|
3. 晚上的计划和休息时间
|
||||||
请按照时间顺序列出具体时间点和对应的活动,用一个时间点而不是时间段来表示时间,用JSON格式返回日程表,仅返回内容,不要返回注释,时间采用24小时制,格式为{"时间": "活动","时间": "活动",...}。"""
|
请按照时间顺序列出具体时间点和对应的活动,用一个时间点而不是时间段来表示时间,用JSON格式返回日程表,仅返回内容,不要返回注释,不要添加任何markdown或代码块样式,时间采用24小时制,格式为{"时间": "活动","时间": "活动",...}。"""
|
||||||
|
)
|
||||||
|
|
||||||
try:
|
try:
|
||||||
schedule_text, _ = await self.llm_scheduler.generate_response(prompt)
|
schedule_text, _ = await self.llm_scheduler.generate_response(prompt)
|
||||||
self.db.db.schedule.insert_one({"date": date_str, "schedule": schedule_text})
|
db.schedule.insert_one({"date": date_str, "schedule": schedule_text})
|
||||||
|
self.enable_output = True
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logger.error(f"生成日程失败: {str(e)}")
|
logger.error(f"生成日程失败: {str(e)}")
|
||||||
schedule_text = "生成日程时出错了"
|
schedule_text = "生成日程时出错了"
|
||||||
# print(self.schedule_text)
|
# print(self.schedule_text)
|
||||||
else:
|
else:
|
||||||
logger.info(f"{date_str}的日程不存在。")
|
if self.enable_output:
|
||||||
|
logger.debug(f"{date_str}的日程不存在。")
|
||||||
schedule_text = "忘了"
|
schedule_text = "忘了"
|
||||||
|
|
||||||
return schedule_text, None
|
return schedule_text, None
|
||||||
@@ -91,7 +91,7 @@ class ScheduleGenerator:
|
|||||||
try:
|
try:
|
||||||
schedule_dict = json.loads(schedule_text)
|
schedule_dict = json.loads(schedule_text)
|
||||||
return schedule_dict
|
return schedule_dict
|
||||||
except json.JSONDecodeError as e:
|
except json.JSONDecodeError:
|
||||||
logger.exception("解析日程失败: {}".format(schedule_text))
|
logger.exception("解析日程失败: {}".format(schedule_text))
|
||||||
return False
|
return False
|
||||||
|
|
||||||
@@ -105,7 +105,7 @@ class ScheduleGenerator:
|
|||||||
|
|
||||||
# 找到最接近当前时间的任务
|
# 找到最接近当前时间的任务
|
||||||
closest_time = None
|
closest_time = None
|
||||||
min_diff = float('inf')
|
min_diff = float("inf")
|
||||||
|
|
||||||
# 检查今天的日程
|
# 检查今天的日程
|
||||||
if not self.today_schedule:
|
if not self.today_schedule:
|
||||||
@@ -152,12 +152,13 @@ class ScheduleGenerator:
|
|||||||
"""打印完整的日程安排"""
|
"""打印完整的日程安排"""
|
||||||
if not self._parse_schedule(self.today_schedule_text):
|
if not self._parse_schedule(self.today_schedule_text):
|
||||||
logger.warning("今日日程有误,将在下次运行时重新生成")
|
logger.warning("今日日程有误,将在下次运行时重新生成")
|
||||||
self.db.db.schedule.delete_one({"date": datetime.datetime.now().strftime("%Y-%m-%d")})
|
db.schedule.delete_one({"date": datetime.datetime.now().strftime("%Y-%m-%d")})
|
||||||
else:
|
else:
|
||||||
logger.info("\n=== 今日日程安排 ===")
|
logger.info("=== 今日日程安排 ===")
|
||||||
for time_str, activity in self.today_schedule.items():
|
for time_str, activity in self.today_schedule.items():
|
||||||
logger.info(f"时间[{time_str}]: 活动[{activity}]")
|
logger.info(f"时间[{time_str}]: 活动[{activity}]")
|
||||||
logger.info("==================\n")
|
logger.info("==================")
|
||||||
|
self.enable_output = False
|
||||||
|
|
||||||
|
|
||||||
# def main():
|
# def main():
|
||||||
|
|||||||
@@ -3,8 +3,9 @@ import time
|
|||||||
from collections import defaultdict
|
from collections import defaultdict
|
||||||
from datetime import datetime, timedelta
|
from datetime import datetime, timedelta
|
||||||
from typing import Any, Dict
|
from typing import Any, Dict
|
||||||
|
from loguru import logger
|
||||||
|
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
|
|
||||||
|
|
||||||
class LLMStatistics:
|
class LLMStatistics:
|
||||||
@@ -14,7 +15,6 @@ class LLMStatistics:
|
|||||||
Args:
|
Args:
|
||||||
output_file: 统计结果输出文件路径
|
output_file: 统计结果输出文件路径
|
||||||
"""
|
"""
|
||||||
self.db = Database.get_instance()
|
|
||||||
self.output_file = output_file
|
self.output_file = output_file
|
||||||
self.running = False
|
self.running = False
|
||||||
self.stats_thread = None
|
self.stats_thread = None
|
||||||
@@ -52,7 +52,7 @@ class LLMStatistics:
|
|||||||
"costs_by_model": defaultdict(float)
|
"costs_by_model": defaultdict(float)
|
||||||
}
|
}
|
||||||
|
|
||||||
cursor = self.db.db.llm_usage.find({
|
cursor = db.llm_usage.find({
|
||||||
"timestamp": {"$gte": start_time}
|
"timestamp": {"$gte": start_time}
|
||||||
})
|
})
|
||||||
|
|
||||||
@@ -153,8 +153,8 @@ class LLMStatistics:
|
|||||||
try:
|
try:
|
||||||
all_stats = self._collect_all_statistics()
|
all_stats = self._collect_all_statistics()
|
||||||
self._save_statistics(all_stats)
|
self._save_statistics(all_stats)
|
||||||
except Exception as e:
|
except Exception:
|
||||||
print(f"\033[1;31m[错误]\033[0m 统计数据处理失败: {e}")
|
logger.exception("统计数据处理失败")
|
||||||
|
|
||||||
# 等待1分钟
|
# 等待1分钟
|
||||||
for _ in range(60):
|
for _ in range(60):
|
||||||
|
|||||||
@@ -13,6 +13,8 @@ from pathlib import Path
|
|||||||
import jieba
|
import jieba
|
||||||
from pypinyin import Style, pinyin
|
from pypinyin import Style, pinyin
|
||||||
|
|
||||||
|
from loguru import logger
|
||||||
|
|
||||||
|
|
||||||
class ChineseTypoGenerator:
|
class ChineseTypoGenerator:
|
||||||
def __init__(self,
|
def __init__(self,
|
||||||
@@ -38,7 +40,9 @@ class ChineseTypoGenerator:
|
|||||||
self.max_freq_diff = max_freq_diff
|
self.max_freq_diff = max_freq_diff
|
||||||
|
|
||||||
# 加载数据
|
# 加载数据
|
||||||
print("正在加载汉字数据库,请稍候...")
|
# print("正在加载汉字数据库,请稍候...")
|
||||||
|
logger.info("正在加载汉字数据库,请稍候...")
|
||||||
|
|
||||||
self.pinyin_dict = self._create_pinyin_dict()
|
self.pinyin_dict = self._create_pinyin_dict()
|
||||||
self.char_frequency = self._load_or_create_char_frequency()
|
self.char_frequency = self._load_or_create_char_frequency()
|
||||||
|
|
||||||
|
|||||||
371
src/plugins/zhishi/knowledge_library.py
Normal file
@@ -0,0 +1,371 @@
|
|||||||
|
import os
|
||||||
|
import sys
|
||||||
|
import time
|
||||||
|
import requests
|
||||||
|
from dotenv import load_dotenv
|
||||||
|
import hashlib
|
||||||
|
from datetime import datetime
|
||||||
|
from tqdm import tqdm
|
||||||
|
from rich.console import Console
|
||||||
|
from rich.table import Table
|
||||||
|
|
||||||
|
# 添加项目根目录到 Python 路径
|
||||||
|
root_path = os.path.abspath(os.path.join(os.path.dirname(__file__), "../../.."))
|
||||||
|
sys.path.append(root_path)
|
||||||
|
|
||||||
|
# 现在可以导入src模块
|
||||||
|
from src.common.database import db
|
||||||
|
|
||||||
|
# 加载根目录下的env.edv文件
|
||||||
|
env_path = os.path.join(root_path, ".env.prod")
|
||||||
|
if not os.path.exists(env_path):
|
||||||
|
raise FileNotFoundError(f"配置文件不存在: {env_path}")
|
||||||
|
load_dotenv(env_path)
|
||||||
|
|
||||||
|
class KnowledgeLibrary:
|
||||||
|
def __init__(self):
|
||||||
|
self.raw_info_dir = "data/raw_info"
|
||||||
|
self._ensure_dirs()
|
||||||
|
self.api_key = os.getenv("SILICONFLOW_KEY")
|
||||||
|
if not self.api_key:
|
||||||
|
raise ValueError("SILICONFLOW_API_KEY 环境变量未设置")
|
||||||
|
self.console = Console()
|
||||||
|
|
||||||
|
def _ensure_dirs(self):
|
||||||
|
"""确保必要的目录存在"""
|
||||||
|
os.makedirs(self.raw_info_dir, exist_ok=True)
|
||||||
|
|
||||||
|
def read_file(self, file_path: str) -> str:
|
||||||
|
"""读取文件内容"""
|
||||||
|
with open(file_path, 'r', encoding='utf-8') as f:
|
||||||
|
return f.read()
|
||||||
|
|
||||||
|
def split_content(self, content: str, max_length: int = 512) -> list:
|
||||||
|
"""将内容分割成适当大小的块,保持段落完整性
|
||||||
|
|
||||||
|
Args:
|
||||||
|
content: 要分割的文本内容
|
||||||
|
max_length: 每个块的最大长度
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
list: 分割后的文本块列表
|
||||||
|
"""
|
||||||
|
# 首先按段落分割
|
||||||
|
paragraphs = [p.strip() for p in content.split('\n\n') if p.strip()]
|
||||||
|
chunks = []
|
||||||
|
current_chunk = []
|
||||||
|
current_length = 0
|
||||||
|
|
||||||
|
for para in paragraphs:
|
||||||
|
para_length = len(para)
|
||||||
|
|
||||||
|
# 如果单个段落就超过最大长度
|
||||||
|
if para_length > max_length:
|
||||||
|
# 如果当前chunk不为空,先保存
|
||||||
|
if current_chunk:
|
||||||
|
chunks.append('\n'.join(current_chunk))
|
||||||
|
current_chunk = []
|
||||||
|
current_length = 0
|
||||||
|
|
||||||
|
# 将长段落按句子分割
|
||||||
|
sentences = [s.strip() for s in para.replace('。', '。\n').replace('!', '!\n').replace('?', '?\n').split('\n') if s.strip()]
|
||||||
|
temp_chunk = []
|
||||||
|
temp_length = 0
|
||||||
|
|
||||||
|
for sentence in sentences:
|
||||||
|
sentence_length = len(sentence)
|
||||||
|
if sentence_length > max_length:
|
||||||
|
# 如果单个句子超长,强制按长度分割
|
||||||
|
if temp_chunk:
|
||||||
|
chunks.append('\n'.join(temp_chunk))
|
||||||
|
temp_chunk = []
|
||||||
|
temp_length = 0
|
||||||
|
for i in range(0, len(sentence), max_length):
|
||||||
|
chunks.append(sentence[i:i + max_length])
|
||||||
|
elif temp_length + sentence_length + 1 <= max_length:
|
||||||
|
temp_chunk.append(sentence)
|
||||||
|
temp_length += sentence_length + 1
|
||||||
|
else:
|
||||||
|
chunks.append('\n'.join(temp_chunk))
|
||||||
|
temp_chunk = [sentence]
|
||||||
|
temp_length = sentence_length
|
||||||
|
|
||||||
|
if temp_chunk:
|
||||||
|
chunks.append('\n'.join(temp_chunk))
|
||||||
|
|
||||||
|
# 如果当前段落加上现有chunk不超过最大长度
|
||||||
|
elif current_length + para_length + 1 <= max_length:
|
||||||
|
current_chunk.append(para)
|
||||||
|
current_length += para_length + 1
|
||||||
|
else:
|
||||||
|
# 保存当前chunk并开始新的chunk
|
||||||
|
chunks.append('\n'.join(current_chunk))
|
||||||
|
current_chunk = [para]
|
||||||
|
current_length = para_length
|
||||||
|
|
||||||
|
# 添加最后一个chunk
|
||||||
|
if current_chunk:
|
||||||
|
chunks.append('\n'.join(current_chunk))
|
||||||
|
|
||||||
|
return chunks
|
||||||
|
|
||||||
|
def get_embedding(self, text: str) -> list:
|
||||||
|
"""获取文本的embedding向量"""
|
||||||
|
url = "https://api.siliconflow.cn/v1/embeddings"
|
||||||
|
payload = {
|
||||||
|
"model": "BAAI/bge-m3",
|
||||||
|
"input": text,
|
||||||
|
"encoding_format": "float"
|
||||||
|
}
|
||||||
|
headers = {
|
||||||
|
"Authorization": f"Bearer {self.api_key}",
|
||||||
|
"Content-Type": "application/json"
|
||||||
|
}
|
||||||
|
|
||||||
|
response = requests.post(url, json=payload, headers=headers)
|
||||||
|
if response.status_code != 200:
|
||||||
|
print(f"获取embedding失败: {response.text}")
|
||||||
|
return None
|
||||||
|
|
||||||
|
return response.json()['data'][0]['embedding']
|
||||||
|
|
||||||
|
def process_files(self, knowledge_length:int=512):
|
||||||
|
"""处理raw_info目录下的所有txt文件"""
|
||||||
|
txt_files = [f for f in os.listdir(self.raw_info_dir) if f.endswith('.txt')]
|
||||||
|
|
||||||
|
if not txt_files:
|
||||||
|
self.console.print("[red]警告:在 {} 目录下没有找到任何txt文件[/red]".format(self.raw_info_dir))
|
||||||
|
self.console.print("[yellow]请将需要处理的文本文件放入该目录后再运行程序[/yellow]")
|
||||||
|
return
|
||||||
|
|
||||||
|
total_stats = {
|
||||||
|
"processed_files": 0,
|
||||||
|
"total_chunks": 0,
|
||||||
|
"failed_files": [],
|
||||||
|
"skipped_files": []
|
||||||
|
}
|
||||||
|
|
||||||
|
self.console.print(f"\n[bold blue]开始处理知识库文件 - 共{len(txt_files)}个文件[/bold blue]")
|
||||||
|
|
||||||
|
for filename in tqdm(txt_files, desc="处理文件进度"):
|
||||||
|
file_path = os.path.join(self.raw_info_dir, filename)
|
||||||
|
result = self.process_single_file(file_path, knowledge_length)
|
||||||
|
self._update_stats(total_stats, result, filename)
|
||||||
|
|
||||||
|
self._display_processing_results(total_stats)
|
||||||
|
|
||||||
|
def process_single_file(self, file_path: str, knowledge_length: int = 512):
|
||||||
|
"""处理单个文件"""
|
||||||
|
result = {
|
||||||
|
"status": "success",
|
||||||
|
"chunks_processed": 0,
|
||||||
|
"error": None
|
||||||
|
}
|
||||||
|
|
||||||
|
try:
|
||||||
|
current_hash = self.calculate_file_hash(file_path)
|
||||||
|
processed_record = db.processed_files.find_one({"file_path": file_path})
|
||||||
|
|
||||||
|
if processed_record:
|
||||||
|
if processed_record.get("hash") == current_hash:
|
||||||
|
if knowledge_length in processed_record.get("split_by", []):
|
||||||
|
result["status"] = "skipped"
|
||||||
|
return result
|
||||||
|
|
||||||
|
content = self.read_file(file_path)
|
||||||
|
chunks = self.split_content(content, knowledge_length)
|
||||||
|
|
||||||
|
for chunk in tqdm(chunks, desc=f"处理 {os.path.basename(file_path)} 的文本块", leave=False):
|
||||||
|
embedding = self.get_embedding(chunk)
|
||||||
|
if embedding:
|
||||||
|
knowledge = {
|
||||||
|
"content": chunk,
|
||||||
|
"embedding": embedding,
|
||||||
|
"source_file": file_path,
|
||||||
|
"split_length": knowledge_length,
|
||||||
|
"created_at": datetime.now()
|
||||||
|
}
|
||||||
|
db.knowledges.insert_one(knowledge)
|
||||||
|
result["chunks_processed"] += 1
|
||||||
|
|
||||||
|
split_by = processed_record.get("split_by", []) if processed_record else []
|
||||||
|
if knowledge_length not in split_by:
|
||||||
|
split_by.append(knowledge_length)
|
||||||
|
|
||||||
|
db.knowledges.processed_files.update_one(
|
||||||
|
{"file_path": file_path},
|
||||||
|
{
|
||||||
|
"$set": {
|
||||||
|
"hash": current_hash,
|
||||||
|
"last_processed": datetime.now(),
|
||||||
|
"split_by": split_by
|
||||||
|
}
|
||||||
|
},
|
||||||
|
upsert=True
|
||||||
|
)
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
result["status"] = "failed"
|
||||||
|
result["error"] = str(e)
|
||||||
|
|
||||||
|
return result
|
||||||
|
|
||||||
|
def _update_stats(self, total_stats, result, filename):
|
||||||
|
"""更新总体统计信息"""
|
||||||
|
if result["status"] == "success":
|
||||||
|
total_stats["processed_files"] += 1
|
||||||
|
total_stats["total_chunks"] += result["chunks_processed"]
|
||||||
|
elif result["status"] == "failed":
|
||||||
|
total_stats["failed_files"].append((filename, result["error"]))
|
||||||
|
elif result["status"] == "skipped":
|
||||||
|
total_stats["skipped_files"].append(filename)
|
||||||
|
|
||||||
|
def _display_processing_results(self, stats):
|
||||||
|
"""显示处理结果统计"""
|
||||||
|
self.console.print("\n[bold green]处理完成!统计信息如下:[/bold green]")
|
||||||
|
|
||||||
|
table = Table(show_header=True, header_style="bold magenta")
|
||||||
|
table.add_column("统计项", style="dim")
|
||||||
|
table.add_column("数值")
|
||||||
|
|
||||||
|
table.add_row("成功处理文件数", str(stats["processed_files"]))
|
||||||
|
table.add_row("处理的知识块总数", str(stats["total_chunks"]))
|
||||||
|
table.add_row("跳过的文件数", str(len(stats["skipped_files"])))
|
||||||
|
table.add_row("失败的文件数", str(len(stats["failed_files"])))
|
||||||
|
|
||||||
|
self.console.print(table)
|
||||||
|
|
||||||
|
if stats["failed_files"]:
|
||||||
|
self.console.print("\n[bold red]处理失败的文件:[/bold red]")
|
||||||
|
for filename, error in stats["failed_files"]:
|
||||||
|
self.console.print(f"[red]- {filename}: {error}[/red]")
|
||||||
|
|
||||||
|
if stats["skipped_files"]:
|
||||||
|
self.console.print("\n[bold yellow]跳过的文件(已处理):[/bold yellow]")
|
||||||
|
for filename in stats["skipped_files"]:
|
||||||
|
self.console.print(f"[yellow]- {filename}[/yellow]")
|
||||||
|
|
||||||
|
def calculate_file_hash(self, file_path):
|
||||||
|
"""计算文件的MD5哈希值"""
|
||||||
|
hash_md5 = hashlib.md5()
|
||||||
|
with open(file_path, "rb") as f:
|
||||||
|
for chunk in iter(lambda: f.read(4096), b""):
|
||||||
|
hash_md5.update(chunk)
|
||||||
|
return hash_md5.hexdigest()
|
||||||
|
|
||||||
|
def search_similar_segments(self, query: str, limit: int = 5) -> list:
|
||||||
|
"""搜索与查询文本相似的片段"""
|
||||||
|
query_embedding = self.get_embedding(query)
|
||||||
|
if not query_embedding:
|
||||||
|
return []
|
||||||
|
|
||||||
|
# 使用余弦相似度计算
|
||||||
|
pipeline = [
|
||||||
|
{
|
||||||
|
"$addFields": {
|
||||||
|
"dotProduct": {
|
||||||
|
"$reduce": {
|
||||||
|
"input": {"$range": [0, {"$size": "$embedding"}]},
|
||||||
|
"initialValue": 0,
|
||||||
|
"in": {
|
||||||
|
"$add": [
|
||||||
|
"$$value",
|
||||||
|
{"$multiply": [
|
||||||
|
{"$arrayElemAt": ["$embedding", "$$this"]},
|
||||||
|
{"$arrayElemAt": [query_embedding, "$$this"]}
|
||||||
|
]}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"magnitude1": {
|
||||||
|
"$sqrt": {
|
||||||
|
"$reduce": {
|
||||||
|
"input": "$embedding",
|
||||||
|
"initialValue": 0,
|
||||||
|
"in": {"$add": ["$$value", {"$multiply": ["$$this", "$$this"]}]}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"magnitude2": {
|
||||||
|
"$sqrt": {
|
||||||
|
"$reduce": {
|
||||||
|
"input": query_embedding,
|
||||||
|
"initialValue": 0,
|
||||||
|
"in": {"$add": ["$$value", {"$multiply": ["$$this", "$$this"]}]}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"$addFields": {
|
||||||
|
"similarity": {
|
||||||
|
"$divide": ["$dotProduct", {"$multiply": ["$magnitude1", "$magnitude2"]}]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{"$sort": {"similarity": -1}},
|
||||||
|
{"$limit": limit},
|
||||||
|
{"$project": {"content": 1, "similarity": 1, "file_path": 1}}
|
||||||
|
]
|
||||||
|
|
||||||
|
results = list(db.knowledges.aggregate(pipeline))
|
||||||
|
return results
|
||||||
|
|
||||||
|
# 创建单例实例
|
||||||
|
knowledge_library = KnowledgeLibrary()
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
console = Console()
|
||||||
|
console.print("[bold green]知识库处理工具[/bold green]")
|
||||||
|
|
||||||
|
while True:
|
||||||
|
console.print("\n请选择要执行的操作:")
|
||||||
|
console.print("[1] 麦麦开始学习")
|
||||||
|
console.print("[2] 麦麦全部忘光光(仅知识)")
|
||||||
|
console.print("[q] 退出程序")
|
||||||
|
|
||||||
|
choice = input("\n请输入选项: ").strip()
|
||||||
|
|
||||||
|
if choice.lower() == 'q':
|
||||||
|
console.print("[yellow]程序退出[/yellow]")
|
||||||
|
sys.exit(0)
|
||||||
|
elif choice == '2':
|
||||||
|
confirm = input("确定要删除所有知识吗?这个操作不可撤销!(y/n): ").strip().lower()
|
||||||
|
if confirm == 'y':
|
||||||
|
db.knowledges.delete_many({})
|
||||||
|
console.print("[green]已清空所有知识![/green]")
|
||||||
|
continue
|
||||||
|
elif choice == '1':
|
||||||
|
if not os.path.exists(knowledge_library.raw_info_dir):
|
||||||
|
console.print(f"[yellow]创建目录:{knowledge_library.raw_info_dir}[/yellow]")
|
||||||
|
os.makedirs(knowledge_library.raw_info_dir, exist_ok=True)
|
||||||
|
|
||||||
|
# 询问分割长度
|
||||||
|
while True:
|
||||||
|
try:
|
||||||
|
length_input = input("请输入知识分割长度(默认512,输入q退出,回车使用默认值): ").strip()
|
||||||
|
if length_input.lower() == 'q':
|
||||||
|
break
|
||||||
|
if not length_input: # 如果直接回车,使用默认值
|
||||||
|
knowledge_length = 512
|
||||||
|
break
|
||||||
|
knowledge_length = int(length_input)
|
||||||
|
if knowledge_length <= 0:
|
||||||
|
print("分割长度必须大于0,请重新输入")
|
||||||
|
continue
|
||||||
|
break
|
||||||
|
except ValueError:
|
||||||
|
print("请输入有效的数字")
|
||||||
|
continue
|
||||||
|
|
||||||
|
if length_input.lower() == 'q':
|
||||||
|
continue
|
||||||
|
|
||||||
|
# 测试知识库功能
|
||||||
|
print(f"开始处理知识库文件,使用分割长度: {knowledge_length}...")
|
||||||
|
knowledge_library.process_files(knowledge_length=knowledge_length)
|
||||||
|
else:
|
||||||
|
console.print("[red]无效的选项,请重新选择[/red]")
|
||||||
|
continue
|
||||||
@@ -11,6 +11,8 @@ from pathlib import Path
|
|||||||
import random
|
import random
|
||||||
import math
|
import math
|
||||||
import time
|
import time
|
||||||
|
from loguru import logger
|
||||||
|
|
||||||
|
|
||||||
class ChineseTypoGenerator:
|
class ChineseTypoGenerator:
|
||||||
def __init__(self,
|
def __init__(self,
|
||||||
@@ -36,7 +38,7 @@ class ChineseTypoGenerator:
|
|||||||
self.max_freq_diff = max_freq_diff
|
self.max_freq_diff = max_freq_diff
|
||||||
|
|
||||||
# 加载数据
|
# 加载数据
|
||||||
print("正在加载汉字数据库,请稍候...")
|
logger.debug("正在加载汉字数据库,请稍候...")
|
||||||
self.pinyin_dict = self._create_pinyin_dict()
|
self.pinyin_dict = self._create_pinyin_dict()
|
||||||
self.char_frequency = self._load_or_create_char_frequency()
|
self.char_frequency = self._load_or_create_char_frequency()
|
||||||
|
|
||||||
@@ -66,7 +68,7 @@ class ChineseTypoGenerator:
|
|||||||
|
|
||||||
# 归一化频率值
|
# 归一化频率值
|
||||||
max_freq = max(char_freq.values())
|
max_freq = max(char_freq.values())
|
||||||
normalized_freq = {char: freq/max_freq * 1000 for char, freq in char_freq.items()}
|
normalized_freq = {char: freq / max_freq * 1000 for char, freq in char_freq.items()}
|
||||||
|
|
||||||
# 保存到缓存文件
|
# 保存到缓存文件
|
||||||
with open(cache_file, 'w', encoding='utf-8') as f:
|
with open(cache_file, 'w', encoding='utf-8') as f:
|
||||||
@@ -399,9 +401,10 @@ class ChineseTypoGenerator:
|
|||||||
for key, value in kwargs.items():
|
for key, value in kwargs.items():
|
||||||
if hasattr(self, key):
|
if hasattr(self, key):
|
||||||
setattr(self, key, value)
|
setattr(self, key, value)
|
||||||
print(f"参数 {key} 已设置为 {value}")
|
logger.debug(f"参数 {key} 已设置为 {value}")
|
||||||
else:
|
else:
|
||||||
print(f"警告: 参数 {key} 不存在")
|
logger.warning(f"警告: 参数 {key} 不存在")
|
||||||
|
|
||||||
|
|
||||||
def main():
|
def main():
|
||||||
# 创建错别字生成器实例
|
# 创建错别字生成器实例
|
||||||
@@ -420,18 +423,18 @@ def main():
|
|||||||
typo_sentence, typo_info = typo_generator.create_typo_sentence(sentence)
|
typo_sentence, typo_info = typo_generator.create_typo_sentence(sentence)
|
||||||
|
|
||||||
# 打印结果
|
# 打印结果
|
||||||
print("\n原句:", sentence)
|
logger.debug("原句:", sentence)
|
||||||
print("错字版:", typo_sentence)
|
logger.debug("错字版:", typo_sentence)
|
||||||
|
|
||||||
# 打印错别字信息
|
# 打印错别字信息
|
||||||
if typo_info:
|
if typo_info:
|
||||||
print("\n错别字信息:")
|
logger.debug(f"错别字信息:{typo_generator.format_typo_info(typo_info)})")
|
||||||
print(typo_generator.format_typo_info(typo_info))
|
|
||||||
|
|
||||||
# 计算并打印总耗时
|
# 计算并打印总耗时
|
||||||
end_time = time.time()
|
end_time = time.time()
|
||||||
total_time = end_time - start_time
|
total_time = end_time - start_time
|
||||||
print(f"\n总耗时:{total_time:.2f}秒")
|
logger.debug(f"总耗时:{total_time:.2f}秒")
|
||||||
|
|
||||||
|
|
||||||
if __name__ == "__main__":
|
if __name__ == "__main__":
|
||||||
main()
|
main()
|
||||||
|
|||||||
15
template.env
@@ -5,20 +5,25 @@ PORT=8080
|
|||||||
PLUGINS=["src2.plugins.chat"]
|
PLUGINS=["src2.plugins.chat"]
|
||||||
|
|
||||||
# 默认配置
|
# 默认配置
|
||||||
MONGODB_HOST=127.0.0.1 # 如果工作在Docker下,请改成 MONGODB_HOST=mongodb
|
# 如果工作在Docker下,请改成 MONGODB_HOST=mongodb
|
||||||
|
MONGODB_HOST=127.0.0.1
|
||||||
MONGODB_PORT=27017
|
MONGODB_PORT=27017
|
||||||
DATABASE_NAME=MegBot
|
DATABASE_NAME=MegBot
|
||||||
|
|
||||||
MONGODB_USERNAME = "" # 默认空值
|
# 也可以使用 URI 连接数据库(优先级比上面的高)
|
||||||
MONGODB_PASSWORD = "" # 默认空值
|
# MONGODB_URI=mongodb://127.0.0.1:27017/MegBot
|
||||||
MONGODB_AUTH_SOURCE = "" # 默认空值
|
|
||||||
|
# MongoDB 认证信息,若需要认证,请取消注释以下三行并填写正确的信息
|
||||||
|
# MONGODB_USERNAME=user
|
||||||
|
# MONGODB_PASSWORD=password
|
||||||
|
# MONGODB_AUTH_SOURCE=admin
|
||||||
|
|
||||||
#key and url
|
#key and url
|
||||||
CHAT_ANY_WHERE_BASE_URL=https://api.chatanywhere.tech/v1
|
CHAT_ANY_WHERE_BASE_URL=https://api.chatanywhere.tech/v1
|
||||||
SILICONFLOW_BASE_URL=https://api.siliconflow.cn/v1/
|
SILICONFLOW_BASE_URL=https://api.siliconflow.cn/v1/
|
||||||
DEEP_SEEK_BASE_URL=https://api.deepseek.com/v1
|
DEEP_SEEK_BASE_URL=https://api.deepseek.com/v1
|
||||||
|
|
||||||
#定义你要用的api的base_url
|
#定义你要用的api的key(需要去对应网站申请哦)
|
||||||
DEEP_SEEK_KEY=
|
DEEP_SEEK_KEY=
|
||||||
CHAT_ANY_WHERE_KEY=
|
CHAT_ANY_WHERE_KEY=
|
||||||
SILICONFLOW_KEY=
|
SILICONFLOW_KEY=
|
||||||
@@ -1,5 +1,5 @@
|
|||||||
[inner]
|
[inner]
|
||||||
version = "0.0.4"
|
version = "0.0.8"
|
||||||
|
|
||||||
#如果你想要修改配置文件,请在修改后将version的值进行变更
|
#如果你想要修改配置文件,请在修改后将version的值进行变更
|
||||||
#如果新增项目,请在BotConfig类下新增相应的变量
|
#如果新增项目,请在BotConfig类下新增相应的变量
|
||||||
@@ -15,6 +15,7 @@ version = "0.0.4"
|
|||||||
[bot]
|
[bot]
|
||||||
qq = 123
|
qq = 123
|
||||||
nickname = "麦麦"
|
nickname = "麦麦"
|
||||||
|
alias_names = ["小麦", "阿麦"]
|
||||||
|
|
||||||
[personality]
|
[personality]
|
||||||
prompt_personality = [
|
prompt_personality = [
|
||||||
@@ -40,6 +41,13 @@ ban_words = [
|
|||||||
# "403","张三"
|
# "403","张三"
|
||||||
]
|
]
|
||||||
|
|
||||||
|
ban_msgs_regex = [
|
||||||
|
# 需要过滤的消息(原始消息)匹配的正则表达式,匹配到的消息将被过滤(支持CQ码),若不了解正则表达式请勿修改
|
||||||
|
#"https?://[^\\s]+", # 匹配https链接
|
||||||
|
#"\\d{4}-\\d{2}-\\d{2}", # 匹配日期
|
||||||
|
# "\\[CQ:at,qq=\\d+\\]" # 匹配@
|
||||||
|
]
|
||||||
|
|
||||||
[emoji]
|
[emoji]
|
||||||
check_interval = 120 # 检查表情包的时间间隔
|
check_interval = 120 # 检查表情包的时间间隔
|
||||||
register_interval = 10 # 注册表情包的时间间隔
|
register_interval = 10 # 注册表情包的时间间隔
|
||||||
@@ -57,8 +65,13 @@ model_r1_distill_probability = 0.1 # 麦麦回答时选择次要回复模型3
|
|||||||
max_response_length = 1024 # 麦麦回答的最大token数
|
max_response_length = 1024 # 麦麦回答的最大token数
|
||||||
|
|
||||||
[memory]
|
[memory]
|
||||||
build_memory_interval = 300 # 记忆构建间隔 单位秒
|
build_memory_interval = 600 # 记忆构建间隔 单位秒 间隔越低,麦麦学习越多,但是冗余信息也会增多
|
||||||
forget_memory_interval = 300 # 记忆遗忘间隔 单位秒
|
memory_compress_rate = 0.1 # 记忆压缩率 控制记忆精简程度 建议保持默认,调高可以获得更多信息,但是冗余信息也会增多
|
||||||
|
|
||||||
|
forget_memory_interval = 600 # 记忆遗忘间隔 单位秒 间隔越低,麦麦遗忘越频繁,记忆更精简,但更难学习
|
||||||
|
memory_forget_time = 24 #多长时间后的记忆会被遗忘 单位小时
|
||||||
|
memory_forget_percentage = 0.01 # 记忆遗忘比例 控制记忆遗忘程度 越大遗忘越多 建议保持默认
|
||||||
|
|
||||||
|
|
||||||
memory_ban_words = [ #不希望记忆的词
|
memory_ban_words = [ #不希望记忆的词
|
||||||
# "403","张三"
|
# "403","张三"
|
||||||
@@ -92,6 +105,8 @@ word_replace_rate=0.006 # 整词替换概率
|
|||||||
[others]
|
[others]
|
||||||
enable_advance_output = true # 是否启用高级输出
|
enable_advance_output = true # 是否启用高级输出
|
||||||
enable_kuuki_read = true # 是否启用读空气功能
|
enable_kuuki_read = true # 是否启用读空气功能
|
||||||
|
enable_debug_output = false # 是否启用调试输出
|
||||||
|
enable_friend_chat = false # 是否启用好友聊天
|
||||||
|
|
||||||
[groups]
|
[groups]
|
||||||
talk_allowed = [
|
talk_allowed = [
|
||||||
|
|||||||
4
如果你更新了版本,点我.txt
Normal file
@@ -0,0 +1,4 @@
|
|||||||
|
更新版本后,建议删除数据库messages中所有内容,不然会出现报错
|
||||||
|
该操作不会影响你的记忆
|
||||||
|
|
||||||
|
如果显示配置文件版本过低,运行根目录的bat
|
||||||
45
如果你的配置文件版本太老就点我.bat
Normal file
@@ -0,0 +1,45 @@
|
|||||||
|
@echo off
|
||||||
|
setlocal enabledelayedexpansion
|
||||||
|
chcp 65001
|
||||||
|
cd /d %~dp0
|
||||||
|
|
||||||
|
echo =====================================
|
||||||
|
echo 选择Python环境:
|
||||||
|
echo 1 - venv (推荐)
|
||||||
|
echo 2 - conda
|
||||||
|
echo =====================================
|
||||||
|
choice /c 12 /n /m "输入数字(1或2): "
|
||||||
|
|
||||||
|
if errorlevel 2 (
|
||||||
|
echo =====================================
|
||||||
|
set "CONDA_ENV="
|
||||||
|
set /p CONDA_ENV="请输入要激活的 conda 环境名称: "
|
||||||
|
|
||||||
|
:: 检查输入是否为空
|
||||||
|
if "!CONDA_ENV!"=="" (
|
||||||
|
echo 错误:环境名称不能为空
|
||||||
|
pause
|
||||||
|
exit /b 1
|
||||||
|
)
|
||||||
|
|
||||||
|
call conda activate !CONDA_ENV!
|
||||||
|
if errorlevel 1 (
|
||||||
|
echo 激活 conda 环境失败
|
||||||
|
pause
|
||||||
|
exit /b 1
|
||||||
|
)
|
||||||
|
|
||||||
|
echo Conda 环境 "!CONDA_ENV!" 激活成功
|
||||||
|
python config/auto_update.py
|
||||||
|
) else (
|
||||||
|
if exist "venv\Scripts\python.exe" (
|
||||||
|
venv\Scripts\python config/auto_update.py
|
||||||
|
) else (
|
||||||
|
echo =====================================
|
||||||
|
echo 错误: venv环境不存在,请先创建虚拟环境
|
||||||
|
pause
|
||||||
|
exit /b 1
|
||||||
|
)
|
||||||
|
)
|
||||||
|
endlocal
|
||||||
|
pause
|
||||||
45
麦麦开始学习.bat
Normal file
@@ -0,0 +1,45 @@
|
|||||||
|
@echo off
|
||||||
|
setlocal enabledelayedexpansion
|
||||||
|
chcp 65001
|
||||||
|
cd /d %~dp0
|
||||||
|
|
||||||
|
echo =====================================
|
||||||
|
echo 选择Python环境:
|
||||||
|
echo 1 - venv (推荐)
|
||||||
|
echo 2 - conda
|
||||||
|
echo =====================================
|
||||||
|
choice /c 12 /n /m "输入数字(1或2): "
|
||||||
|
|
||||||
|
if errorlevel 2 (
|
||||||
|
echo =====================================
|
||||||
|
set "CONDA_ENV="
|
||||||
|
set /p CONDA_ENV="请输入要激活的 conda 环境名称: "
|
||||||
|
|
||||||
|
:: 检查输入是否为空
|
||||||
|
if "!CONDA_ENV!"=="" (
|
||||||
|
echo 错误:环境名称不能为空
|
||||||
|
pause
|
||||||
|
exit /b 1
|
||||||
|
)
|
||||||
|
|
||||||
|
call conda activate !CONDA_ENV!
|
||||||
|
if errorlevel 1 (
|
||||||
|
echo 激活 conda 环境失败
|
||||||
|
pause
|
||||||
|
exit /b 1
|
||||||
|
)
|
||||||
|
|
||||||
|
echo Conda 环境 "!CONDA_ENV!" 激活成功
|
||||||
|
python src/plugins/zhishi/knowledge_library.py
|
||||||
|
) else (
|
||||||
|
if exist "venv\Scripts\python.exe" (
|
||||||
|
venv\Scripts\python src/plugins/zhishi/knowledge_library.py
|
||||||
|
) else (
|
||||||
|
echo =====================================
|
||||||
|
echo 错误: venv环境不存在,请先创建虚拟环境
|
||||||
|
pause
|
||||||
|
exit /b 1
|
||||||
|
)
|
||||||
|
)
|
||||||
|
endlocal
|
||||||
|
pause
|
||||||