diff --git a/README.md b/README.md
index a7394c7cf..7d06ad789 100644
--- a/README.md
+++ b/README.md
@@ -43,6 +43,7 @@
- [一群](https://qm.qq.com/q/VQ3XZrWgMs) 766798517 ,建议加下面的(开发和建议相关讨论)不一定有空回复,会优先写文档和代码
- [二群](https://qm.qq.com/q/RzmCiRtHEW) 571780722 (开发和建议相关讨论)不一定有空回复,会优先写文档和代码
- [三群](https://qm.qq.com/q/wlH5eT8OmQ) 1035228475(开发和建议相关讨论)不一定有空回复,会优先写文档和代码
+- [四群](https://qm.qq.com/q/wlH5eT8OmQ) 729957033(开发和建议相关讨论)不一定有空回复,会优先写文档和代码
@@ -53,11 +54,17 @@
- (由 [CabLate](https://github.com/cablate) 贡献) [Telegram 与其他平台(未来可能会有)的版本](https://github.com/cablate/MaiMBot/tree/telegram) - [集中讨论串](https://github.com/SengokuCola/MaiMBot/discussions/149)
+
+
+## 📝 注意注意注意注意注意注意注意注意注意注意注意注意注意注意注意注意注意
+**如果你有想法想要提交pr**
+- 由于本项目在快速迭代和功能调整,并且有重构计划,目前不接受任何未经过核心开发组讨论的pr合并,谢谢!如您仍旧希望提交pr,可以详情请看置顶issue
+
📚 文档 ⬇️ 快速开始使用麦麦 ⬇️
-### 部署方式
+### 部署方式(忙于开发,部分内容可能过时)
- 📦 **Windows 一键傻瓜式部署**:请运行项目根目录中的 `run.bat`,部署完成后请参照后续配置指南进行配置
diff --git a/bot.py b/bot.py
index a3a844a15..acc7990ed 100644
--- a/bot.py
+++ b/bot.py
@@ -8,14 +8,21 @@ import time
import uvicorn
from dotenv import load_dotenv
-from loguru import logger
from nonebot.adapters.onebot.v11 import Adapter
import platform
+from src.plugins.utils.logger_config import setup_logger
+
+from loguru import logger
+
+# 配置日志格式
# 获取没有加载env时的环境变量
env_mask = {key: os.getenv(key) for key in os.environ}
uvicorn_server = None
+driver = None
+app = None
+loop = None
def easter_egg():
@@ -95,43 +102,7 @@ def load_env():
def load_logger():
- logger.remove()
-
- # 配置日志基础路径
- log_path = os.path.join(os.getcwd(), "logs")
- if not os.path.exists(log_path):
- os.makedirs(log_path)
-
- current_env = os.getenv("ENVIRONMENT", "dev")
-
- # 公共配置参数
- log_level = os.getenv("LOG_LEVEL", "INFO" if current_env == "prod" else "DEBUG")
- log_filter = lambda record: (
- ("nonebot" not in record["name"] or record["level"].no >= logger.level("ERROR").no)
- if current_env == "prod"
- else True
- )
- log_format = (
- "{time:YYYY-MM-DD HH:mm:ss.SSS} "
- "| {level: <7} "
- "| {name:.<8}:{function:.<8}:{line: >4} "
- "- {message}"
- )
-
- # 日志文件储存至/logs
- logger.add(
- os.path.join(log_path, "maimbot_{time:YYYY-MM-DD}.log"),
- rotation="00:00",
- retention="30 days",
- format=log_format,
- colorize=False,
- level=log_level,
- filter=log_filter,
- encoding="utf-8",
- )
-
- # 终端输出
- logger.add(sys.stderr, format=log_format, colorize=True, level=log_level, filter=log_filter)
+ setup_logger()
def scan_provider(env_config: dict):
@@ -203,11 +174,14 @@ def raw_main():
if platform.system().lower() != "windows":
time.tzset()
+ # 配置日志
+ load_logger()
easter_egg()
init_config()
init_env()
load_env()
- load_logger()
+
+ # load_logger()
env_config = {key: os.getenv(key) for key in os.environ}
scan_provider(env_config)
@@ -235,17 +209,21 @@ if __name__ == "__main__":
try:
raw_main()
- global app
app = nonebot.get_asgi()
-
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
- loop.run_until_complete(uvicorn_main())
- except KeyboardInterrupt:
- logger.warning("麦麦会努力做的更好的!正在停止中......")
+
+ try:
+ loop.run_until_complete(uvicorn_main())
+ except KeyboardInterrupt:
+ logger.warning("收到中断信号,正在优雅关闭...")
+ loop.run_until_complete(graceful_shutdown())
+ finally:
+ loop.close()
+
except Exception as e:
- logger.error(f"主程序异常: {e}")
- finally:
- loop.run_until_complete(graceful_shutdown())
- loop.close()
- logger.info("进程终止完毕,麦麦开始休眠......下次再见哦!")
+ logger.error(f"主程序异常: {str(e)}")
+ if loop and not loop.is_closed():
+ loop.run_until_complete(graceful_shutdown())
+ loop.close()
+ sys.exit(1)
diff --git a/docs/installation_cute.md b/docs/installation_cute.md
index e0c03310f..ca97f18e9 100644
--- a/docs/installation_cute.md
+++ b/docs/installation_cute.md
@@ -43,13 +43,11 @@ CHAT_ANY_WHERE_BASE_URL=https://api.chatanywhere.tech/v1 # ChatAnyWhere的地
```toml
[model.llm_reasoning]
name = "Pro/deepseek-ai/DeepSeek-R1"
-base_url = "SILICONFLOW_BASE_URL" # 告诉机器人:去硅基流动游乐园玩
-key = "SILICONFLOW_KEY" # 用硅基流动的门票进去
+provider = "SILICONFLOW" # 告诉机器人:去硅基流动游乐园玩,机器人会自动用硅基流动的门票进去
[model.llm_normal]
name = "Pro/deepseek-ai/DeepSeek-V3"
-base_url = "SILICONFLOW_BASE_URL" # 还是去硅基流动游乐园
-key = "SILICONFLOW_KEY" # 用同一张门票就可以啦
+provider = "SILICONFLOW" # 还是去硅基流动游乐园
```
### 🎪 举个例子喵
@@ -59,13 +57,11 @@ key = "SILICONFLOW_KEY" # 用同一张门票就可以啦
```toml
[model.llm_reasoning]
name = "deepseek-reasoner" # 改成对应的模型名称,这里为DeepseekR1
-base_url = "DEEP_SEEK_BASE_URL" # 改成去DeepSeek游乐园
-key = "DEEP_SEEK_KEY" # 用DeepSeek的门票
+provider = "DEEP_SEEK" # 改成去DeepSeek游乐园
[model.llm_normal]
name = "deepseek-chat" # 改成对应的模型名称,这里为DeepseekV3
-base_url = "DEEP_SEEK_BASE_URL" # 也去DeepSeek游乐园
-key = "DEEP_SEEK_KEY" # 用同一张DeepSeek门票
+provider = "DEEP_SEEK" # 也去DeepSeek游乐园
```
### 🎯 简单来说
@@ -132,28 +128,35 @@ prompt_personality = [
"曾经是一个学习地质的女大学生,现在学习心理学和脑科学,你会刷贴吧", # 贴吧风格的性格
"是一个女大学生,你有黑色头发,你会刷小红书" # 小红书风格的性格
]
-prompt_schedule = "一个曾经学习地质,现在学习心理学和脑科学的女大学生,喜欢刷qq,贴吧,知乎和小红书"
+prompt_schedule = "一个曾经学习地质,现在学习心理学和脑科学的女大学生,喜欢刷qq,贴吧,知乎和小红书" # 用来提示机器人每天干什么的提示词喵
[message]
min_text_length = 2 # 机器人每次至少要说几个字呢
max_context_size = 15 # 机器人能记住多少条消息喵
emoji_chance = 0.2 # 机器人使用表情的概率哦(0.2就是20%的机会呢)
-ban_words = ["脏话", "不文明用语"] # 在这里填写不让机器人说的词
+thinking_timeout = 120 # 机器人思考时间,时间越长能思考的时间越多,但是不要太长喵
+
+response_willing_amplifier = 1 # 机器人回复意愿放大系数,增大会让他更愿意聊天喵
+response_interested_rate_amplifier = 1 # 机器人回复兴趣度放大系数,听到记忆里的内容时意愿的放大系数喵
+down_frequency_rate = 3.5 # 降低回复频率的群组回复意愿降低系数
+ban_words = ["脏话", "不文明用语"] # 在这里填写不让机器人说的词,要用英文逗号隔开,每个词都要用英文双引号括起来喵
[emoji]
auto_save = true # 是否自动保存看到的表情包呢
enable_check = false # 是否要检查表情包是不是合适的喵
check_prompt = "符合公序良俗" # 检查表情包的标准呢
+[others]
+enable_advance_output = true # 是否要显示更多的运行信息呢
+enable_kuuki_read = true # 让机器人能够"察言观色"喵
+enable_debug_output = false # 是否启用调试输出喵
+enable_friend_chat = false # 是否启用好友聊天喵
+
[groups]
talk_allowed = [123456, 789012] # 比如:让机器人在群123456和789012里说话
talk_frequency_down = [345678] # 比如:在群345678里少说点话
ban_user_id = [111222] # 比如:不回复QQ号为111222的人的消息
-[others]
-enable_advance_output = true # 是否要显示更多的运行信息呢
-enable_kuuki_read = true # 让机器人能够"察言观色"喵
-
# 模型配置部分的详细说明喵~
@@ -162,46 +165,39 @@ enable_kuuki_read = true # 让机器人能够"察言观色"喵
[model.llm_reasoning] #推理模型R1,用来理解和思考的喵
name = "Pro/deepseek-ai/DeepSeek-R1" # 模型名字
# name = "Qwen/QwQ-32B" # 如果想用千问模型,可以把上面那行注释掉,用这个呢
-base_url = "SILICONFLOW_BASE_URL" # 使用在.env.prod里设置的服务地址
-key = "SILICONFLOW_KEY" # 使用在.env.prod里设置的密钥
+provider = "SILICONFLOW" # 使用在.env.prod里设置的宏,也就是去掉"_BASE_URL"留下来的字喵
[model.llm_reasoning_minor] #R1蒸馏模型,是个轻量版的推理模型喵
name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
-base_url = "SILICONFLOW_BASE_URL"
-key = "SILICONFLOW_KEY"
+provider = "SILICONFLOW"
[model.llm_normal] #V3模型,用来日常聊天的喵
name = "Pro/deepseek-ai/DeepSeek-V3"
-base_url = "SILICONFLOW_BASE_URL"
-key = "SILICONFLOW_KEY"
+provider = "SILICONFLOW"
[model.llm_normal_minor] #V2.5模型,是V3的前代版本呢
name = "deepseek-ai/DeepSeek-V2.5"
-base_url = "SILICONFLOW_BASE_URL"
-key = "SILICONFLOW_KEY"
+provider = "SILICONFLOW"
[model.vlm] #图像识别模型,让机器人能看懂图片喵
name = "deepseek-ai/deepseek-vl2"
-base_url = "SILICONFLOW_BASE_URL"
-key = "SILICONFLOW_KEY"
+provider = "SILICONFLOW"
[model.embedding] #嵌入模型,帮助机器人理解文本的相似度呢
name = "BAAI/bge-m3"
-base_url = "SILICONFLOW_BASE_URL"
-key = "SILICONFLOW_KEY"
+provider = "SILICONFLOW"
# 如果选择了llm方式提取主题,就用这个模型配置喵
[topic.llm_topic]
name = "Pro/deepseek-ai/DeepSeek-V3"
-base_url = "SILICONFLOW_BASE_URL"
-key = "SILICONFLOW_KEY"
+provider = "SILICONFLOW"
```
## 💡 模型配置说明喵
1. **关于模型服务**:
- 如果你用硅基流动的服务,这些配置都不用改呢
- - 如果用DeepSeek官方API,要把base_url和key改成你在.env.prod里设置的值喵
+ - 如果用DeepSeek官方API,要把provider改成你在.env.prod里设置的宏喵
- 如果要用自定义模型,选择一个相似功能的模型配置来改呢
2. **主要模型功能**:
diff --git a/docs/installation_standard.md b/docs/installation_standard.md
index dfaf0e797..dcbbf0c99 100644
--- a/docs/installation_standard.md
+++ b/docs/installation_standard.md
@@ -30,8 +30,7 @@ CHAT_ANY_WHERE_BASE_URL=https://api.chatanywhere.tech/v1 # ChatAnyWhere API地
```toml
[model.llm_reasoning]
name = "Pro/deepseek-ai/DeepSeek-R1"
-base_url = "SILICONFLOW_BASE_URL" # 引用.env.prod中定义的地址
-key = "SILICONFLOW_KEY" # 引用.env.prod中定义的密钥
+provider = "SILICONFLOW" # 引用.env.prod中定义的宏
```
如需切换到其他API服务,只需修改引用:
@@ -39,8 +38,7 @@ key = "SILICONFLOW_KEY" # 引用.env.prod中定义的密钥
```toml
[model.llm_reasoning]
name = "deepseek-reasoner" # 改成对应的模型名称,这里为DeepseekR1
-base_url = "DEEP_SEEK_BASE_URL" # 切换为DeepSeek服务
-key = "DEEP_SEEK_KEY" # 使用DeepSeek密钥
+provider = "DEEP_SEEK" # 使用DeepSeek密钥
```
## 配置文件详解
@@ -82,7 +80,7 @@ PLUGINS=["src2.plugins.chat"]
```toml
[bot]
-qq = "机器人QQ号" # 必填
+qq = "机器人QQ号" # 机器人的QQ号,必填
nickname = "麦麦" # 机器人昵称
# alias_names: 配置机器人可使用的别名。当机器人在群聊或对话中被调用时,别名可以作为直接命令或提及机器人的关键字使用。
# 该配置项为字符串数组。例如: ["小麦", "阿麦"]
@@ -92,13 +90,18 @@ alias_names = ["小麦", "阿麦"] # 机器人别名
prompt_personality = [
"曾经是一个学习地质的女大学生,现在学习心理学和脑科学,你会刷贴吧",
"是一个女大学生,你有黑色头发,你会刷小红书"
-]
-prompt_schedule = "一个曾经学习地质,现在学习心理学和脑科学的女大学生,喜欢刷qq,贴吧,知乎和小红书"
+] # 人格提示词
+prompt_schedule = "一个曾经学习地质,现在学习心理学和脑科学的女大学生,喜欢刷qq,贴吧,知乎和小红书" # 日程生成提示词
[message]
min_text_length = 2 # 最小回复长度
max_context_size = 15 # 上下文记忆条数
emoji_chance = 0.2 # 表情使用概率
+thinking_timeout = 120 # 机器人思考时间,时间越长能思考的时间越多,但是不要太长
+
+response_willing_amplifier = 1 # 机器人回复意愿放大系数,增大会更愿意聊天
+response_interested_rate_amplifier = 1 # 机器人回复兴趣度放大系数,听到记忆里的内容时意愿的放大系数
+down_frequency_rate = 3.5 # 降低回复频率的群组回复意愿降低系数
ban_words = [] # 禁用词列表
[emoji]
@@ -112,45 +115,40 @@ talk_frequency_down = [] # 降低回复频率的群号
ban_user_id = [] # 禁止回复的用户QQ号
[others]
-enable_advance_output = true # 启用详细日志
-enable_kuuki_read = true # 启用场景理解
+enable_advance_output = true # 是否启用高级输出
+enable_kuuki_read = true # 是否启用读空气功能
+enable_debug_output = false # 是否启用调试输出
+enable_friend_chat = false # 是否启用好友聊天
# 模型配置
[model.llm_reasoning] # 推理模型
name = "Pro/deepseek-ai/DeepSeek-R1"
-base_url = "SILICONFLOW_BASE_URL"
-key = "SILICONFLOW_KEY"
+provider = "SILICONFLOW"
[model.llm_reasoning_minor] # 轻量推理模型
name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
-base_url = "SILICONFLOW_BASE_URL"
-key = "SILICONFLOW_KEY"
+provider = "SILICONFLOW"
[model.llm_normal] # 对话模型
name = "Pro/deepseek-ai/DeepSeek-V3"
-base_url = "SILICONFLOW_BASE_URL"
-key = "SILICONFLOW_KEY"
+provider = "SILICONFLOW"
[model.llm_normal_minor] # 备用对话模型
name = "deepseek-ai/DeepSeek-V2.5"
-base_url = "SILICONFLOW_BASE_URL"
-key = "SILICONFLOW_KEY"
+provider = "SILICONFLOW"
[model.vlm] # 图像识别模型
name = "deepseek-ai/deepseek-vl2"
-base_url = "SILICONFLOW_BASE_URL"
-key = "SILICONFLOW_KEY"
+provider = "SILICONFLOW"
[model.embedding] # 文本向量模型
name = "BAAI/bge-m3"
-base_url = "SILICONFLOW_BASE_URL"
-key = "SILICONFLOW_KEY"
+provider = "SILICONFLOW"
[topic.llm_topic]
name = "Pro/deepseek-ai/DeepSeek-V3"
-base_url = "SILICONFLOW_BASE_URL"
-key = "SILICONFLOW_KEY"
+provider = "SILICONFLOW"
```
## 注意事项
diff --git a/docs/synology_deploy.md b/docs/synology_deploy.md
index 23e24e704..a7b3bebda 100644
--- a/docs/synology_deploy.md
+++ b/docs/synology_deploy.md
@@ -24,6 +24,7 @@ bot_config.toml: https://github.com/SengokuCola/MaiMBot/blob/main/template/bot_c
.env.prod: https://github.com/SengokuCola/MaiMBot/blob/main/template.env
下载后,重命名为 `.env.prod`
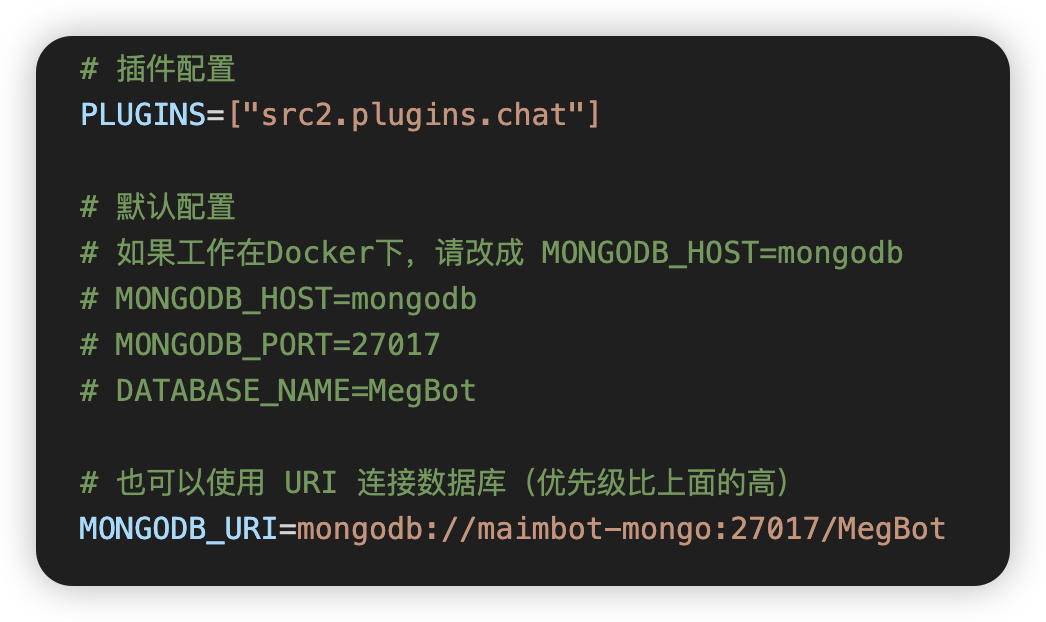
+将 `HOST` 修改为 `0.0.0.0`,确保 maimbot 能被 napcat 访问
按下图修改 mongodb 设置,使用 `MONGODB_URI`
diff --git a/src/plugins/chat/__init__.py b/src/plugins/chat/__init__.py
index 6dde80d24..6b8f639ae 100644
--- a/src/plugins/chat/__init__.py
+++ b/src/plugins/chat/__init__.py
@@ -20,7 +20,7 @@ from .chat_stream import chat_manager
from ..memory_system.memory import hippocampus, memory_graph
from .bot import ChatBot
from .message_sender import message_manager, message_sender
-
+from .storage import MessageStorage
# 创建LLM统计实例
llm_stats = LLMStatistics("llm_statistics.txt")
@@ -148,3 +148,13 @@ async def generate_schedule_task():
await bot_schedule.initialize()
if not bot_schedule.enable_output:
bot_schedule.print_schedule()
+
+@scheduler.scheduled_job("interval", seconds=3600, id="remove_recalled_message")
+
+async def remove_recalled_message() -> None:
+ """删除撤回消息"""
+ try:
+ storage = MessageStorage()
+ await storage.remove_recalled_message(time.time())
+ except Exception:
+ logger.exception("删除撤回消息失败")
\ No newline at end of file
diff --git a/src/plugins/chat/bot.py b/src/plugins/chat/bot.py
index b8624dae0..4d1318f2a 100644
--- a/src/plugins/chat/bot.py
+++ b/src/plugins/chat/bot.py
@@ -1,7 +1,6 @@
import re
import time
from random import random
-from loguru import logger
from nonebot.adapters.onebot.v11 import (
Bot,
GroupMessageEvent,
@@ -9,6 +8,9 @@ from nonebot.adapters.onebot.v11 import (
PrivateMessageEvent,
NoticeEvent,
PokeNotifyEvent,
+ GroupRecallNoticeEvent,
+ FriendRecallNoticeEvent,
+
)
from ..memory_system.memory import hippocampus
@@ -30,6 +32,10 @@ from .utils_image import image_path_to_base64
from .utils_user import get_user_nickname, get_user_cardname, get_groupname
from .willing_manager import willing_manager # 导入意愿管理器
from .message_base import UserInfo, GroupInfo, Seg
+from ..utils.logger_config import setup_logger, LogModule
+
+# 配置日志
+logger = setup_logger(LogModule.CHAT)
class ChatBot:
@@ -53,64 +59,43 @@ class ChatBot:
"""处理收到的通知"""
# 戳一戳通知
if isinstance(event, PokeNotifyEvent):
+ # 不处理其他人的戳戳
+ if not event.is_tome():
+ return
+
# 用户屏蔽,不区分私聊/群聊
if event.user_id in global_config.ban_user_id:
return
- reply_poke_probability = 1 # 回复戳一戳的概率
+
+ reply_poke_probability = 1.0 # 回复戳一戳的概率,如果要改可以在这里改,暂不提取到配置文件
if random() < reply_poke_probability:
- user_info = UserInfo(
- user_id=event.user_id,
- user_nickname=get_user_nickname(event.user_id) or None,
- user_cardname=get_user_cardname(event.user_id) or None,
- platform="qq",
- )
- group_info = GroupInfo(group_id=event.group_id, group_name=None, platform="qq")
- message_cq = MessageRecvCQ(
- message_id=None,
- user_info=user_info,
- raw_message=str("[戳了戳]你"),
- group_info=group_info,
- reply_message=None,
- platform="qq",
- )
- message_json = message_cq.to_dict()
+ raw_message = "[戳了戳]你" # 默认类型
+ if info := event.raw_info:
+ poke_type = info[2].get("txt", "戳了戳") # 戳戳类型,例如“拍一拍”、“揉一揉”、“捏一捏”
+ custom_poke_message = info[4].get("txt", "") # 自定义戳戳消息,若不存在会为空字符串
+ raw_message = f"[{poke_type}]你{custom_poke_message}"
- # 进入maimbot
- message = MessageRecv(message_json)
- groupinfo = message.message_info.group_info
- userinfo = message.message_info.user_info
- messageinfo = message.message_info
+ raw_message += "(这是一个类似摸摸头的友善行为,而不是恶意行为,请不要作出攻击发言)"
+ await self.directly_reply(raw_message, event.user_id, event.group_id)
- chat = await chat_manager.get_or_create_stream(
- platform=messageinfo.platform, user_info=userinfo, group_info=groupinfo
- )
- message.update_chat_stream(chat)
- await message.process()
+ if isinstance(event, GroupRecallNoticeEvent) or isinstance(event, FriendRecallNoticeEvent):
+ user_info = UserInfo(
+ user_id=event.user_id,
+ user_nickname=get_user_nickname(event.user_id) or None,
+ user_cardname=get_user_cardname(event.user_id) or None,
+ platform="qq",
+ )
- bot_user_info = UserInfo(
- user_id=global_config.BOT_QQ,
- user_nickname=global_config.BOT_NICKNAME,
- platform=messageinfo.platform,
- )
+ group_info = GroupInfo(group_id=event.group_id, group_name=None, platform="qq")
- response, raw_content = await self.gpt.generate_response(message)
+ chat = await chat_manager.get_or_create_stream(
+ platform=user_info.platform, user_info=user_info, group_info=group_info
+ )
+
+ await self.storage.store_recalled_message(event.message_id, time.time(), chat)
+
- if response:
- for msg in response:
- message_segment = Seg(type="text", data=msg)
-
- bot_message = MessageSending(
- message_id=None,
- chat_stream=chat,
- bot_user_info=bot_user_info,
- sender_info=userinfo,
- message_segment=message_segment,
- reply=None,
- is_head=False,
- is_emoji=False,
- )
- message_manager.add_message(bot_message)
async def handle_message(self, event: MessageEvent, bot: Bot) -> None:
"""处理收到的消息"""
@@ -120,8 +105,13 @@ class ChatBot:
# 用户屏蔽,不区分私聊/群聊
if event.user_id in global_config.ban_user_id:
return
-
- if event.reply and hasattr(event.reply, 'sender') and hasattr(event.reply.sender, 'user_id') and event.reply.sender.user_id in global_config.ban_user_id:
+
+ if (
+ event.reply
+ and hasattr(event.reply, "sender")
+ and hasattr(event.reply.sender, "user_id")
+ and event.reply.sender.user_id in global_config.ban_user_id
+ ):
logger.debug(f"跳过处理回复来自被ban用户 {event.reply.sender.user_id} 的消息")
return
# 处理私聊消息
@@ -371,6 +361,72 @@ class ChatBot:
# chat_stream=chat
# )
+ async def directly_reply(self, raw_message: str, user_id: int, group_id: int):
+ """
+ 直接回复发来的消息,不经过意愿管理器
+ """
+
+ # 构造用户信息和群组信息
+ user_info = UserInfo(
+ user_id=user_id,
+ user_nickname=get_user_nickname(user_id) or None,
+ user_cardname=get_user_cardname(user_id) or None,
+ platform="qq",
+ )
+ group_info = GroupInfo(group_id=group_id, group_name=None, platform="qq")
+
+ message_cq = MessageRecvCQ(
+ message_id=None,
+ user_info=user_info,
+ raw_message=raw_message,
+ group_info=group_info,
+ reply_message=None,
+ platform="qq",
+ )
+ message_json = message_cq.to_dict()
+
+ message = MessageRecv(message_json)
+ groupinfo = message.message_info.group_info
+ userinfo = message.message_info.user_info
+ messageinfo = message.message_info
+
+ chat = await chat_manager.get_or_create_stream(
+ platform=messageinfo.platform, user_info=userinfo, group_info=groupinfo
+ )
+ message.update_chat_stream(chat)
+ await message.process()
+
+ bot_user_info = UserInfo(
+ user_id=global_config.BOT_QQ,
+ user_nickname=global_config.BOT_NICKNAME,
+ platform=messageinfo.platform,
+ )
+
+ current_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(messageinfo.time))
+ logger.info(
+ f"[{current_time}][{chat.group_info.group_name if chat.group_info else '私聊'}]{chat.user_info.user_nickname}:"
+ f"{message.processed_plain_text}"
+ )
+
+ # 使用大模型生成回复
+ response, raw_content = await self.gpt.generate_response(message)
+
+ if response:
+ for msg in response:
+ message_segment = Seg(type="text", data=msg)
+
+ bot_message = MessageSending(
+ message_id=None,
+ chat_stream=chat,
+ bot_user_info=bot_user_info,
+ sender_info=userinfo,
+ message_segment=message_segment,
+ reply=None,
+ is_head=False,
+ is_emoji=False,
+ )
+ message_manager.add_message(bot_message)
+
# 创建全局ChatBot实例
chat_bot = ChatBot()
diff --git a/src/plugins/chat/emoji_manager.py b/src/plugins/chat/emoji_manager.py
index e3342d1a7..ab5dad5e9 100644
--- a/src/plugins/chat/emoji_manager.py
+++ b/src/plugins/chat/emoji_manager.py
@@ -18,11 +18,17 @@ from ..chat.utils import get_embedding
from ..chat.utils_image import ImageManager, image_path_to_base64
from ..models.utils_model import LLM_request
+from ..utils.logger_config import setup_logger, LogModule
+
+# 配置日志
+logger = setup_logger(LogModule.EMOJI)
+
driver = get_driver()
config = driver.config
image_manager = ImageManager()
+
class EmojiManager:
_instance = None
EMOJI_DIR = os.path.join("data", "emoji") # 表情包存储目录
@@ -154,20 +160,20 @@ class EmojiManager:
# 更新使用次数
db.emoji.update_one({"_id": selected_emoji["_id"]}, {"$inc": {"usage_count": 1}})
- logger.success(
- f"找到匹配的表情包: {selected_emoji.get('description', '无描述')} (相似度: {similarity:.4f})"
+ logger.info(
+ f"[匹配] 找到表情包: {selected_emoji.get('description', '无描述')} (相似度: {similarity:.4f})"
)
# 稍微改一下文本描述,不然容易产生幻觉,描述已经包含 表情包 了
return selected_emoji["path"], "[ %s ]" % selected_emoji.get("description", "无描述")
except Exception as search_error:
- logger.error(f"搜索表情包失败: {str(search_error)}")
+ logger.error(f"[错误] 搜索表情包失败: {str(search_error)}")
return None
return None
except Exception as e:
- logger.error(f"获取表情包失败: {str(e)}")
+ logger.error(f"[错误] 获取表情包失败: {str(e)}")
return None
async def _get_emoji_discription(self, image_base64: str) -> str:
@@ -181,7 +187,7 @@ class EmojiManager:
return description
except Exception as e:
- logger.error(f"获取标签失败: {str(e)}")
+ logger.error(f"[错误] 获取表情包描述失败: {str(e)}")
return None
async def _check_emoji(self, image_base64: str, image_format: str) -> str:
@@ -189,11 +195,11 @@ class EmojiManager:
prompt = f'这是一个表情包,请回答这个表情包是否满足"{global_config.EMOJI_CHECK_PROMPT}"的要求,是则回答是,否则回答否,不要出现任何其他内容'
content, _ = await self.vlm.generate_response_for_image(prompt, image_base64, image_format)
- logger.debug(f"输出描述: {content}")
+ logger.debug(f"[检查] 表情包检查结果: {content}")
return content
except Exception as e:
- logger.error(f"获取标签失败: {str(e)}")
+ logger.error(f"[错误] 表情包检查失败: {str(e)}")
return None
async def _get_kimoji_for_text(self, text: str):
@@ -201,11 +207,11 @@ class EmojiManager:
prompt = f'这是{global_config.BOT_NICKNAME}将要发送的消息内容:\n{text}\n若要为其配上表情包,请你输出这个表情包应该表达怎样的情感,应该给人什么样的感觉,不要太简洁也不要太长,注意不要输出任何对消息内容的分析内容,只输出"一种什么样的感觉"中间的形容词部分。'
content, _ = await self.llm_emotion_judge.generate_response_async(prompt, temperature=1.5)
- logger.info(f"输出描述: {content}")
+ logger.info(f"[情感] 表情包情感描述: {content}")
return content
except Exception as e:
- logger.error(f"获取标签失败: {str(e)}")
+ logger.error(f"[错误] 获取表情包情感失败: {str(e)}")
return None
async def scan_new_emojis(self):
@@ -252,7 +258,7 @@ class EmojiManager:
db.images.update_one({"hash": image_hash}, {"$set": image_doc}, upsert=True)
# 保存描述到image_descriptions集合
image_manager._save_description_to_db(image_hash, description, "emoji")
- logger.success(f"同步已存在的表情包到images集合: {filename}")
+ logger.success(f"[同步] 已同步表情包到images集合: {filename}")
continue
# 检查是否在images集合中已有描述
@@ -268,15 +274,10 @@ class EmojiManager:
check = await self._check_emoji(image_base64, image_format)
if "是" not in check:
os.remove(image_path)
- logger.info(f"描述: {description}")
-
- logger.info(f"描述: {description}")
- logger.info(f"其不满足过滤规则,被剔除 {check}")
+ logger.info(f"[过滤] 表情包描述: {description}")
+ logger.info(f"[过滤] 表情包不满足规则,已移除: {check}")
continue
- logger.info(f"check通过 {check}")
-
- if description is not None:
- embedding = await get_embedding(description)
+ logger.info(f"[检查] 表情包检查通过: {check}")
if description is not None:
embedding = await get_embedding(description)
@@ -293,8 +294,8 @@ class EmojiManager:
# 保存到emoji数据库
db["emoji"].insert_one(emoji_record)
- logger.success(f"注册新表情包: {filename}")
- logger.info(f"描述: {description}")
+ logger.success(f"[注册] 新表情包: {filename}")
+ logger.info(f"[描述] {description}")
# 保存到images数据库
image_doc = {
@@ -307,17 +308,17 @@ class EmojiManager:
db.images.update_one({"hash": image_hash}, {"$set": image_doc}, upsert=True)
# 保存描述到image_descriptions集合
image_manager._save_description_to_db(image_hash, description, "emoji")
- logger.success(f"同步保存到images集合: {filename}")
+ logger.success(f"[同步] 已保存到images集合: {filename}")
else:
- logger.warning(f"跳过表情包: {filename}")
+ logger.warning(f"[跳过] 表情包: {filename}")
except Exception:
- logger.exception("扫描表情包失败")
+ logger.exception("[错误] 扫描表情包失败")
async def _periodic_scan(self, interval_MINS: int = 10):
"""定期扫描新表情包"""
while True:
- logger.info("开始扫描新表情包...")
+ logger.info("[扫描] 开始扫描新表情包...")
await self.scan_new_emojis()
await asyncio.sleep(interval_MINS * 60) # 每600秒扫描一次
@@ -335,48 +336,48 @@ class EmojiManager:
for emoji in all_emojis:
try:
if "path" not in emoji:
- logger.warning(f"发现无效记录(缺少path字段),ID: {emoji.get('_id', 'unknown')}")
+ logger.warning(f"[检查] 发现无效记录(缺少path字段),ID: {emoji.get('_id', 'unknown')}")
db.emoji.delete_one({"_id": emoji["_id"]})
removed_count += 1
continue
if "embedding" not in emoji:
- logger.warning(f"发现过时记录(缺少embedding字段),ID: {emoji.get('_id', 'unknown')}")
+ logger.warning(f"[检查] 发现过时记录(缺少embedding字段),ID: {emoji.get('_id', 'unknown')}")
db.emoji.delete_one({"_id": emoji["_id"]})
removed_count += 1
continue
# 检查文件是否存在
if not os.path.exists(emoji["path"]):
- logger.warning(f"表情包文件已被删除: {emoji['path']}")
+ logger.warning(f"[检查] 表情包文件已被删除: {emoji['path']}")
# 从数据库中删除记录
result = db.emoji.delete_one({"_id": emoji["_id"]})
if result.deleted_count > 0:
- logger.debug(f"成功删除数据库记录: {emoji['_id']}")
+ logger.debug(f"[清理] 成功删除数据库记录: {emoji['_id']}")
removed_count += 1
else:
- logger.error(f"删除数据库记录失败: {emoji['_id']}")
+ logger.error(f"[错误] 删除数据库记录失败: {emoji['_id']}")
continue
if "hash" not in emoji:
- logger.warning(f"发现缺失记录(缺少hash字段),ID: {emoji.get('_id', 'unknown')}")
+ logger.warning(f"[检查] 发现缺失记录(缺少hash字段),ID: {emoji.get('_id', 'unknown')}")
hash = hashlib.md5(open(emoji["path"], "rb").read()).hexdigest()
db.emoji.update_one({"_id": emoji["_id"]}, {"$set": {"hash": hash}})
except Exception as item_error:
- logger.error(f"处理表情包记录时出错: {str(item_error)}")
+ logger.error(f"[错误] 处理表情包记录时出错: {str(item_error)}")
continue
# 验证清理结果
remaining_count = db.emoji.count_documents({})
if removed_count > 0:
- logger.success(f"已清理 {removed_count} 个失效的表情包记录")
- logger.info(f"清理前总数: {total_count} | 清理后总数: {remaining_count}")
+ logger.success(f"[清理] 已清理 {removed_count} 个失效的表情包记录")
+ logger.info(f"[统计] 清理前: {total_count} | 清理后: {remaining_count}")
else:
- logger.info(f"已检查 {total_count} 个表情包记录")
+ logger.info(f"[检查] 已检查 {total_count} 个表情包记录")
except Exception as e:
- logger.error(f"检查表情包完整性失败: {str(e)}")
+ logger.error(f"[错误] 检查表情包完整性失败: {str(e)}")
logger.error(traceback.format_exc())
async def start_periodic_check(self, interval_MINS: int = 120):
diff --git a/src/plugins/chat/message.py b/src/plugins/chat/message.py
index f05139279..b93b3fb28 100644
--- a/src/plugins/chat/message.py
+++ b/src/plugins/chat/message.py
@@ -325,7 +325,7 @@ class MessageSending(MessageProcessBase):
self.message_segment = Seg(
type="seglist",
data=[
- Seg(type="reply", data=reply.message_info.message_id),
+ Seg(type="reply", data=self.reply.message_info.message_id),
self.message_segment,
],
)
diff --git a/src/plugins/chat/message_sender.py b/src/plugins/chat/message_sender.py
index 5b580f244..b138af3b6 100644
--- a/src/plugins/chat/message_sender.py
+++ b/src/plugins/chat/message_sender.py
@@ -4,7 +4,7 @@ from typing import Dict, List, Optional, Union
from loguru import logger
from nonebot.adapters.onebot.v11 import Bot
-
+from ...common.database import db
from .message_cq import MessageSendCQ
from .message import MessageSending, MessageThinking, MessageRecv, MessageSet
@@ -24,6 +24,14 @@ class Message_Sender:
def set_bot(self, bot: Bot):
"""设置当前bot实例"""
self._current_bot = bot
+
+ def get_recalled_messages(self, stream_id: str) -> list:
+ """获取所有撤回的消息"""
+ recalled_messages = []
+
+ recalled_messages = list(db.recalled_messages.find({"stream_id": stream_id}, {"message_id": 1}))
+ # 按thinking_start_time排序,时间早的在前面
+ return recalled_messages
async def send_message(
self,
@@ -32,36 +40,41 @@ class Message_Sender:
"""发送消息"""
if isinstance(message, MessageSending):
- message_json = message.to_dict()
- message_send = MessageSendCQ(data=message_json)
- # logger.debug(message_send.message_info,message_send.raw_message)
- message_preview = truncate_message(message.processed_plain_text)
- if (
- message_send.message_info.group_info
- and message_send.message_info.group_info.group_id
- ):
- try:
- await self._current_bot.send_group_msg(
- group_id=message.message_info.group_info.group_id,
- message=message_send.raw_message,
- auto_escape=False,
- )
- logger.success(f"[调试] 发送消息“{message_preview}”成功")
- except Exception as e:
- logger.error(f"[调试] 发生错误 {e}")
- logger.error(f"[调试] 发送消息“{message_preview}”失败")
- else:
- try:
- logger.debug(message.message_info.user_info)
- await self._current_bot.send_private_msg(
- user_id=message.sender_info.user_id,
- message=message_send.raw_message,
- auto_escape=False,
- )
- logger.success(f"[调试] 发送消息“{message_preview}”成功")
- except Exception as e:
- logger.error(f"[调试] 发生错误 {e}")
- logger.error(f"[调试] 发送消息“{message_preview}”失败")
+ recalled_messages = self.get_recalled_messages(message.chat_stream.stream_id)
+ is_recalled = False
+ for recalled_message in recalled_messages:
+ if message.reply_to_message_id == recalled_message["message_id"]:
+ is_recalled = True
+ logger.warning(f"消息“{message.processed_plain_text}”已被撤回,不发送")
+ break
+ if not is_recalled:
+ message_json = message.to_dict()
+ message_send = MessageSendCQ(data=message_json)
+ # logger.debug(message_send.message_info,message_send.raw_message)
+ message_preview = truncate_message(message.processed_plain_text)
+ if message_send.message_info.group_info and message_send.message_info.group_info.group_id:
+ try:
+ await self._current_bot.send_group_msg(
+ group_id=message.message_info.group_info.group_id,
+ message=message_send.raw_message,
+ auto_escape=False,
+ )
+ logger.success(f"[调试] 发送消息“{message_preview}”成功")
+ except Exception as e:
+ logger.error(f"[调试] 发生错误 {e}")
+ logger.error(f"[调试] 发送消息“{message_preview}”失败")
+ else:
+ try:
+ logger.debug(message.message_info.user_info)
+ await self._current_bot.send_private_msg(
+ user_id=message.sender_info.user_id,
+ message=message_send.raw_message,
+ auto_escape=False,
+ )
+ logger.success(f"[调试] 发送消息“{message_preview}”成功")
+ except Exception as e:
+ logger.error(f"[调试] 发生错误 {e}")
+ logger.error(f"[调试] 发送消息“{message_preview}”失败")
class MessageContainer:
@@ -144,9 +157,7 @@ class MessageManager:
self.containers[chat_id] = MessageContainer(chat_id)
return self.containers[chat_id]
- def add_message(
- self, message: Union[MessageThinking, MessageSending, MessageSet]
- ) -> None:
+ def add_message(self, message: Union[MessageThinking, MessageSending, MessageSet]) -> None:
chat_stream = message.chat_stream
if not chat_stream:
raise ValueError("无法找到对应的聊天流")
@@ -173,25 +184,22 @@ class MessageManager:
if thinking_time > global_config.thinking_timeout:
logger.warning(f"消息思考超时({thinking_time}秒),移除该消息")
container.remove_message(message_earliest)
- else:
+ else:
if (
message_earliest.is_head
and message_earliest.update_thinking_time() > 30
and not message_earliest.is_private_message() # 避免在私聊时插入reply
):
- await message_sender.send_message(message_earliest.set_reply())
- else:
- await message_sender.send_message(message_earliest)
+ message_earliest.set_reply()
+ await message_sender.send_message(message_earliest)
await message_earliest.process()
print(
f"\033[1;34m[调试]\033[0m 消息“{truncate_message(message_earliest.processed_plain_text)}”正在发送中"
)
- await self.storage.store_message(
- message_earliest, message_earliest.chat_stream, None
- )
+ await self.storage.store_message(message_earliest, message_earliest.chat_stream, None)
container.remove_message(message_earliest)
@@ -208,9 +216,8 @@ class MessageManager:
and msg.update_thinking_time() > 30
and not message_earliest.is_private_message() # 避免在私聊时插入reply
):
- await message_sender.send_message(msg.set_reply())
- else:
- await message_sender.send_message(msg)
+ msg.set_reply()
+ await message_sender.send_message(msg)
# if msg.is_emoji:
# msg.processed_plain_text = "[表情包]"
diff --git a/src/plugins/chat/storage.py b/src/plugins/chat/storage.py
index 33099d6b6..99ae13bd8 100644
--- a/src/plugins/chat/storage.py
+++ b/src/plugins/chat/storage.py
@@ -25,4 +25,25 @@ class MessageStorage:
except Exception:
logger.exception("存储消息失败")
+ async def store_recalled_message(self, message_id: str, time: str, chat_stream:ChatStream) -> None:
+ """存储撤回消息到数据库"""
+ if "recalled_messages" not in db.list_collection_names():
+ db.create_collection("recalled_messages")
+ else:
+ try:
+ message_data = {
+ "message_id": message_id,
+ "time": time,
+ "stream_id":chat_stream.stream_id,
+ }
+ db.recalled_messages.insert_one(message_data)
+ except Exception:
+ logger.exception("存储撤回消息失败")
+
+ async def remove_recalled_message(self, time: str) -> None:
+ """删除撤回消息"""
+ try:
+ db.recalled_messages.delete_many({"time": {"$lt": time-300}})
+ except Exception:
+ logger.exception("删除撤回消息失败")
# 如果需要其他存储相关的函数,可以在这里添加
diff --git a/src/plugins/memory_system/memory.py b/src/plugins/memory_system/memory.py
index c5ec2ddcb..9113fb3ba 100644
--- a/src/plugins/memory_system/memory.py
+++ b/src/plugins/memory_system/memory.py
@@ -8,9 +8,8 @@ import os
import jieba
import networkx as nx
-from loguru import logger
from nonebot import get_driver
-from ...common.database import db # 使用正确的导入语法
+from ...common.database import db
from ..chat.config import global_config
from ..chat.utils import (
calculate_information_content,
@@ -20,6 +19,13 @@ from ..chat.utils import (
)
from ..models.utils_model import LLM_request
+from ..utils.logger_config import setup_logger, LogModule
+
+# 配置日志
+logger = setup_logger(LogModule.MEMORY)
+
+logger.info("初始化记忆系统")
+
class Memory_graph:
def __init__(self):
self.G = nx.Graph() # 使用 networkx 的图结构
@@ -518,7 +524,7 @@ class Hippocampus:
{'concept': concept},
{'$set': update_data}
)
- logger.info(f"为节点 {concept} 添加缺失的时间字段")
+ logger.info(f"[时间更新] 节点 {concept} 添加缺失的时间字段")
# 获取时间信息(如果不存在则使用当前时间)
created_time = node.get('created_time', current_time)
@@ -551,7 +557,7 @@ class Hippocampus:
{'source': source, 'target': target},
{'$set': update_data}
)
- logger.info(f"为边 {source} - {target} 添加缺失的时间字段")
+ logger.info(f"[时间更新] 边 {source} - {target} 添加缺失的时间字段")
# 获取时间信息(如果不存在则使用当前时间)
created_time = edge.get('created_time', current_time)
@@ -565,16 +571,27 @@ class Hippocampus:
last_modified=last_modified)
if need_update:
- logger.success("已为缺失的时间字段进行补充")
+ logger.success("[数据库] 已为缺失的时间字段进行补充")
async def operation_forget_topic(self, percentage=0.1):
"""随机选择图中一定比例的节点和边进行检查,根据时间条件决定是否遗忘"""
# 检查数据库是否为空
+ # logger.remove()
+
+ logger.info(f"[遗忘] 开始检查数据库... 当前Logger信息:")
+ # logger.info(f"- Logger名称: {logger.name}")
+ logger.info(f"- Logger等级: {logger.level}")
+ # logger.info(f"- Logger处理器: {[handler.__class__.__name__ for handler in logger.handlers]}")
+
+ # logger2 = setup_logger(LogModule.MEMORY)
+ # logger2.info(f"[遗忘] 开始检查数据库... 当前Logger信息:")
+ # logger.info(f"[遗忘] 开始检查数据库... 当前Logger信息:")
+
all_nodes = list(self.memory_graph.G.nodes())
all_edges = list(self.memory_graph.G.edges())
if not all_nodes and not all_edges:
- logger.info("记忆图为空,无需进行遗忘操作")
+ logger.info("[遗忘] 记忆图为空,无需进行遗忘操作")
return
check_nodes_count = max(1, int(len(all_nodes) * percentage))
@@ -589,35 +606,32 @@ class Hippocampus:
current_time = datetime.datetime.now().timestamp()
# 检查并遗忘连接
- logger.info("开始检查连接...")
+ logger.info("[遗忘] 开始检查连接...")
for source, target in edges_to_check:
edge_data = self.memory_graph.G[source][target]
last_modified = edge_data.get('last_modified')
- # print(source,target)
- # print(f"float(last_modified):{float(last_modified)}" )
- # print(f"current_time:{current_time}")
- # print(f"current_time - last_modified:{current_time - last_modified}")
- if current_time - last_modified > 3600*global_config.memory_forget_time: # test
+
+ if current_time - last_modified > 3600*global_config.memory_forget_time:
current_strength = edge_data.get('strength', 1)
new_strength = current_strength - 1
if new_strength <= 0:
self.memory_graph.G.remove_edge(source, target)
edge_changes['removed'] += 1
- logger.info(f"\033[1;31m[连接移除]\033[0m {source} - {target}")
+ logger.info(f"[遗忘] 连接移除: {source} -> {target}")
else:
edge_data['strength'] = new_strength
edge_data['last_modified'] = current_time
edge_changes['weakened'] += 1
- logger.info(f"\033[1;34m[连接减弱]\033[0m {source} - {target} (强度: {current_strength} -> {new_strength})")
+ logger.info(f"[遗忘] 连接减弱: {source} -> {target} (强度: {current_strength} -> {new_strength})")
# 检查并遗忘话题
- logger.info("开始检查节点...")
+ logger.info("[遗忘] 开始检查节点...")
for node in nodes_to_check:
node_data = self.memory_graph.G.nodes[node]
last_modified = node_data.get('last_modified', current_time)
- if current_time - last_modified > 3600*24: # test
+ if current_time - last_modified > 3600*24:
memory_items = node_data.get('memory_items', [])
if not isinstance(memory_items, list):
memory_items = [memory_items] if memory_items else []
@@ -631,27 +645,22 @@ class Hippocampus:
self.memory_graph.G.nodes[node]['memory_items'] = memory_items
self.memory_graph.G.nodes[node]['last_modified'] = current_time
node_changes['reduced'] += 1
- logger.info(f"\033[1;33m[记忆减少]\033[0m {node} (记忆数量: {current_count} -> {len(memory_items)})")
+ logger.info(f"[遗忘] 记忆减少: {node} (数量: {current_count} -> {len(memory_items)})")
else:
self.memory_graph.G.remove_node(node)
node_changes['removed'] += 1
- logger.info(f"\033[1;31m[节点移除]\033[0m {node}")
+ logger.info(f"[遗忘] 节点移除: {node}")
if any(count > 0 for count in edge_changes.values()) or any(count > 0 for count in node_changes.values()):
self.sync_memory_to_db()
- logger.info("\n遗忘操作统计:")
- logger.info(f"连接变化: {edge_changes['weakened']} 个减弱, {edge_changes['removed']} 个移除")
- logger.info(f"节点变化: {node_changes['reduced']} 个减少记忆, {node_changes['removed']} 个移除")
+ logger.info("[遗忘] 统计信息:")
+ logger.info(f"[遗忘] 连接变化: {edge_changes['weakened']} 个减弱, {edge_changes['removed']} 个移除")
+ logger.info(f"[遗忘] 节点变化: {node_changes['reduced']} 个减少记忆, {node_changes['removed']} 个移除")
else:
- logger.info("\n本次检查没有节点或连接满足遗忘条件")
+ logger.info("[遗忘] 本次检查没有节点或连接满足遗忘条件")
async def merge_memory(self, topic):
- """
- 对指定话题的记忆进行合并压缩
-
- Args:
- topic: 要合并的话题节点
- """
+ """对指定话题的记忆进行合并压缩"""
# 获取节点的记忆项
memory_items = self.memory_graph.G.nodes[topic].get('memory_items', [])
if not isinstance(memory_items, list):
@@ -666,8 +675,8 @@ class Hippocampus:
# 拼接成文本
merged_text = "\n".join(selected_memories)
- logger.debug(f"\n[合并记忆] 话题: {topic}")
- logger.debug(f"选择的记忆:\n{merged_text}")
+ logger.debug(f"[合并] 话题: {topic}")
+ logger.debug(f"[合并] 选择的记忆:\n{merged_text}")
# 使用memory_compress生成新的压缩记忆
compressed_memories, _ = await self.memory_compress(selected_memories, 0.1)
@@ -679,11 +688,11 @@ class Hippocampus:
# 添加新的压缩记忆
for _, compressed_memory in compressed_memories:
memory_items.append(compressed_memory)
- logger.info(f"添加压缩记忆: {compressed_memory}")
+ logger.info(f"[合并] 添加压缩记忆: {compressed_memory}")
# 更新节点的记忆项
self.memory_graph.G.nodes[topic]['memory_items'] = memory_items
- logger.debug(f"完成记忆合并,当前记忆数量: {len(memory_items)}")
+ logger.debug(f"[合并] 完成记忆合并,当前记忆数量: {len(memory_items)}")
async def operation_merge_memory(self, percentage=0.1):
"""
@@ -813,7 +822,7 @@ class Hippocampus:
async def memory_activate_value(self, text: str, max_topics: int = 5, similarity_threshold: float = 0.3) -> int:
"""计算输入文本对记忆的激活程度"""
- logger.info(f"识别主题: {await self._identify_topics(text)}")
+ logger.info(f"[激活] 识别主题: {await self._identify_topics(text)}")
# 识别主题
identified_topics = await self._identify_topics(text)
@@ -824,7 +833,7 @@ class Hippocampus:
all_similar_topics = self._find_similar_topics(
identified_topics,
similarity_threshold=similarity_threshold,
- debug_info="记忆激活"
+ debug_info="激活"
)
if not all_similar_topics:
@@ -845,7 +854,7 @@ class Hippocampus:
activation = int(score * 50 * penalty)
logger.info(
- f"[记忆激活]单主题「{topic}」- 相似度: {score:.3f}, 内容数: {content_count}, 激活值: {activation}")
+ f"[激活] 单主题「{topic}」- 相似度: {score:.3f}, 内容数: {content_count}, 激活值: {activation}")
return activation
# 计算关键词匹配率,同时考虑内容数量
@@ -872,8 +881,8 @@ class Hippocampus:
matched_topics.add(input_topic)
adjusted_sim = sim * penalty
topic_similarities[input_topic] = max(topic_similarities.get(input_topic, 0), adjusted_sim)
- logger.info(
- f"[记忆激活]主题「{input_topic}」-> 「{memory_topic}」(内容数: {content_count}, 相似度: {adjusted_sim:.3f})")
+ logger.debug(
+ f"[激活] 主题「{input_topic}」-> 「{memory_topic}」(内容数: {content_count}, 相似度: {adjusted_sim:.3f})")
# 计算主题匹配率和平均相似度
topic_match = len(matched_topics) / len(identified_topics)
@@ -882,7 +891,7 @@ class Hippocampus:
# 计算最终激活值
activation = int((topic_match + average_similarities) / 2 * 100)
logger.info(
- f"[记忆激活]匹配率: {topic_match:.3f}, 平均相似度: {average_similarities:.3f}, 激活值: {activation}")
+ f"[激活] 匹配率: {topic_match:.3f}, 平均相似度: {average_similarities:.3f}, 激活值: {activation}")
return activation
diff --git a/src/plugins/models/utils_model.py b/src/plugins/models/utils_model.py
index 0f5bb335c..c5782a923 100644
--- a/src/plugins/models/utils_model.py
+++ b/src/plugins/models/utils_model.py
@@ -18,6 +18,17 @@ config = driver.config
class LLM_request:
+ # 定义需要转换的模型列表,作为类变量避免重复
+ MODELS_NEEDING_TRANSFORMATION = [
+ "o3-mini",
+ "o1-mini",
+ "o1-preview",
+ "o1-2024-12-17",
+ "o1-preview-2024-09-12",
+ "o3-mini-2025-01-31",
+ "o1-mini-2024-09-12",
+ ]
+
def __init__(self, model, **kwargs):
# 将大写的配置键转换为小写并从config中获取实际值
try:
@@ -36,7 +47,8 @@ class LLM_request:
# 获取数据库实例
self._init_database()
- def _init_database(self):
+ @staticmethod
+ def _init_database():
"""初始化数据库集合"""
try:
# 创建llm_usage集合的索引
@@ -44,12 +56,18 @@ class LLM_request:
db.llm_usage.create_index([("model_name", 1)])
db.llm_usage.create_index([("user_id", 1)])
db.llm_usage.create_index([("request_type", 1)])
- except Exception:
- logger.error("创建数据库索引失败")
+ except Exception as e:
+ logger.error(f"创建数据库索引失败: {str(e)}")
- def _record_usage(self, prompt_tokens: int, completion_tokens: int, total_tokens: int,
- user_id: str = "system", request_type: str = "chat",
- endpoint: str = "/chat/completions"):
+ def _record_usage(
+ self,
+ prompt_tokens: int,
+ completion_tokens: int,
+ total_tokens: int,
+ user_id: str = "system",
+ request_type: str = "chat",
+ endpoint: str = "/chat/completions",
+ ):
"""记录模型使用情况到数据库
Args:
prompt_tokens: 输入token数
@@ -70,7 +88,7 @@ class LLM_request:
"total_tokens": total_tokens,
"cost": self._calculate_cost(prompt_tokens, completion_tokens),
"status": "success",
- "timestamp": datetime.now()
+ "timestamp": datetime.now(),
}
db.llm_usage.insert_one(usage_data)
logger.info(
@@ -79,17 +97,17 @@ class LLM_request:
f"提示词: {prompt_tokens}, 完成: {completion_tokens}, "
f"总计: {total_tokens}"
)
- except Exception:
- logger.error("记录token使用情况失败")
+ except Exception as e:
+ logger.error(f"记录token使用情况失败: {str(e)}")
def _calculate_cost(self, prompt_tokens: int, completion_tokens: int) -> float:
"""计算API调用成本
使用模型的pri_in和pri_out价格计算输入和输出的成本
-
+
Args:
prompt_tokens: 输入token数量
completion_tokens: 输出token数量
-
+
Returns:
float: 总成本(元)
"""
@@ -99,16 +117,16 @@ class LLM_request:
return round(input_cost + output_cost, 6)
async def _execute_request(
- self,
- endpoint: str,
- prompt: str = None,
- image_base64: str = None,
- image_format: str = None,
- payload: dict = None,
- retry_policy: dict = None,
- response_handler: callable = None,
- user_id: str = "system",
- request_type: str = "chat"
+ self,
+ endpoint: str,
+ prompt: str = None,
+ image_base64: str = None,
+ image_format: str = None,
+ payload: dict = None,
+ retry_policy: dict = None,
+ response_handler: callable = None,
+ user_id: str = "system",
+ request_type: str = "chat",
):
"""统一请求执行入口
Args:
@@ -124,9 +142,11 @@ class LLM_request:
"""
# 合并重试策略
default_retry = {
- "max_retries": 3, "base_wait": 15,
+ "max_retries": 3,
+ "base_wait": 15,
"retry_codes": [429, 413, 500, 503],
- "abort_codes": [400, 401, 402, 403]}
+ "abort_codes": [400, 401, 402, 403],
+ }
policy = {**default_retry, **(retry_policy or {})}
# 常见Error Code Mapping
@@ -138,16 +158,14 @@ class LLM_request:
404: "Not Found",
429: "请求过于频繁,请稍后再试",
500: "服务器内部故障",
- 503: "服务器负载过高"
+ 503: "服务器负载过高",
}
api_url = f"{self.base_url.rstrip('/')}/{endpoint.lstrip('/')}"
# 判断是否为流式
stream_mode = self.params.get("stream", False)
- if self.params.get("stream", False) is True:
- logger.debug(f"进入流式输出模式,发送请求到URL: {api_url}")
- else:
- logger.debug(f"发送请求到URL: {api_url}")
+ logger_msg = "进入流式输出模式," if stream_mode else ""
+ logger.debug(f"{logger_msg}发送请求到URL: {api_url}")
logger.info(f"使用模型: {self.model_name}")
# 构建请求体
@@ -168,7 +186,7 @@ class LLM_request:
async with session.post(api_url, headers=headers, json=payload) as response:
# 处理需要重试的状态码
if response.status in policy["retry_codes"]:
- wait_time = policy["base_wait"] * (2 ** retry)
+ wait_time = policy["base_wait"] * (2**retry)
logger.warning(f"错误码: {response.status}, 等待 {wait_time}秒后重试")
if response.status == 413:
logger.warning("请求体过大,尝试压缩...")
@@ -184,26 +202,56 @@ class LLM_request:
continue
elif response.status in policy["abort_codes"]:
logger.error(f"错误码: {response.status} - {error_code_mapping.get(response.status)}")
+ # 尝试获取并记录服务器返回的详细错误信息
+ try:
+ error_json = await response.json()
+ if error_json and isinstance(error_json, list) and len(error_json) > 0:
+ for error_item in error_json:
+ if "error" in error_item and isinstance(error_item["error"], dict):
+ error_obj = error_item["error"]
+ error_code = error_obj.get("code")
+ error_message = error_obj.get("message")
+ error_status = error_obj.get("status")
+ logger.error(
+ f"服务器错误详情: 代码={error_code}, 状态={error_status}, 消息={error_message}"
+ )
+ elif isinstance(error_json, dict) and "error" in error_json:
+ # 处理单个错误对象的情况
+ error_obj = error_json.get("error", {})
+ error_code = error_obj.get("code")
+ error_message = error_obj.get("message")
+ error_status = error_obj.get("status")
+ logger.error(
+ f"服务器错误详情: 代码={error_code}, 状态={error_status}, 消息={error_message}"
+ )
+ else:
+ # 记录原始错误响应内容
+ logger.error(f"服务器错误响应: {error_json}")
+ except Exception as e:
+ logger.warning(f"无法解析服务器错误响应: {str(e)}")
+
if response.status == 403:
- #只针对硅基流动的V3和R1进行降级处理
- if self.model_name.startswith(
- "Pro/deepseek-ai") and self.base_url == "https://api.siliconflow.cn/v1/":
+ # 只针对硅基流动的V3和R1进行降级处理
+ if (
+ self.model_name.startswith("Pro/deepseek-ai")
+ and self.base_url == "https://api.siliconflow.cn/v1/"
+ ):
old_model_name = self.model_name
self.model_name = self.model_name[4:] # 移除"Pro/"前缀
logger.warning(f"检测到403错误,模型从 {old_model_name} 降级为 {self.model_name}")
# 对全局配置进行更新
- if global_config.llm_normal.get('name') == old_model_name:
- global_config.llm_normal['name'] = self.model_name
+ if global_config.llm_normal.get("name") == old_model_name:
+ global_config.llm_normal["name"] = self.model_name
logger.warning(f"将全局配置中的 llm_normal 模型临时降级至{self.model_name}")
- if global_config.llm_reasoning.get('name') == old_model_name:
- global_config.llm_reasoning['name'] = self.model_name
+ if global_config.llm_reasoning.get("name") == old_model_name:
+ global_config.llm_reasoning["name"] = self.model_name
logger.warning(f"将全局配置中的 llm_reasoning 模型临时降级至{self.model_name}")
# 更新payload中的模型名
- if payload and 'model' in payload:
- payload['model'] = self.model_name
+ if payload and "model" in payload:
+ payload["model"] = self.model_name
# 重新尝试请求
retry -= 1 # 不计入重试次数
@@ -217,6 +265,8 @@ class LLM_request:
if stream_mode:
flag_delta_content_finished = False
accumulated_content = ""
+ usage = None # 初始化usage变量,避免未定义错误
+
async for line_bytes in response.content:
line = line_bytes.decode("utf-8").strip()
if not line:
@@ -228,7 +278,9 @@ class LLM_request:
try:
chunk = json.loads(data_str)
if flag_delta_content_finished:
- usage = chunk.get("usage", None) # 获取tokn用量
+ chunk_usage = chunk.get("usage",None)
+ if chunk_usage:
+ usage = chunk_usage # 获取token用量
else:
delta = chunk["choices"][0]["delta"]
delta_content = delta.get("content")
@@ -236,40 +288,99 @@ class LLM_request:
delta_content = ""
accumulated_content += delta_content
# 检测流式输出文本是否结束
- finish_reason = chunk["choices"][0].get("finish_reason")
+ finish_reason = chunk["choices"][0].get("finish_reason")
if finish_reason == "stop":
- usage = chunk.get("usage", None)
- if usage:
+ chunk_usage = chunk.get("usage",None)
+ if chunk_usage:
+ usage = chunk_usage
break
# 部分平台在文本输出结束前不会返回token用量,此时需要再获取一次chunk
flag_delta_content_finished = True
-
- except Exception:
- logger.exception("解析流式输出错误")
+
+ except Exception as e:
+ logger.exception(f"解析流式输出错误: {str(e)}")
content = accumulated_content
reasoning_content = ""
- think_match = re.search(r'(.*?)', content, re.DOTALL)
+ think_match = re.search(r"(.*?)", content, re.DOTALL)
if think_match:
reasoning_content = think_match.group(1).strip()
- content = re.sub(r'.*?', '', content, flags=re.DOTALL).strip()
+ content = re.sub(r".*?", "", content, flags=re.DOTALL).strip()
# 构造一个伪result以便调用自定义响应处理器或默认处理器
result = {
- "choices": [{"message": {"content": content, "reasoning_content": reasoning_content}}], "usage": usage}
- return response_handler(result) if response_handler else self._default_response_handler(
- result, user_id, request_type, endpoint)
+ "choices": [{"message": {"content": content, "reasoning_content": reasoning_content}}],
+ "usage": usage,
+ }
+ return (
+ response_handler(result)
+ if response_handler
+ else self._default_response_handler(result, user_id, request_type, endpoint)
+ )
else:
result = await response.json()
# 使用自定义处理器或默认处理
- return response_handler(result) if response_handler else self._default_response_handler(
- result, user_id, request_type, endpoint)
+ return (
+ response_handler(result)
+ if response_handler
+ else self._default_response_handler(result, user_id, request_type, endpoint)
+ )
+ except aiohttp.ClientResponseError as e:
+ # 处理aiohttp抛出的响应错误
+ if retry < policy["max_retries"] - 1:
+ wait_time = policy["base_wait"] * (2**retry)
+ logger.error(f"HTTP响应错误,等待{wait_time}秒后重试... 状态码: {e.status}, 错误: {e.message}")
+ try:
+ if hasattr(e, "response") and e.response and hasattr(e.response, "text"):
+ error_text = await e.response.text()
+ try:
+ error_json = json.loads(error_text)
+ if isinstance(error_json, list) and len(error_json) > 0:
+ for error_item in error_json:
+ if "error" in error_item and isinstance(error_item["error"], dict):
+ error_obj = error_item["error"]
+ logger.error(
+ f"服务器错误详情: 代码={error_obj.get('code')}, 状态={error_obj.get('status')}, 消息={error_obj.get('message')}"
+ )
+ elif isinstance(error_json, dict) and "error" in error_json:
+ error_obj = error_json.get("error", {})
+ logger.error(
+ f"服务器错误详情: 代码={error_obj.get('code')}, 状态={error_obj.get('status')}, 消息={error_obj.get('message')}"
+ )
+ else:
+ logger.error(f"服务器错误响应: {error_json}")
+ except (json.JSONDecodeError, TypeError) as json_err:
+ logger.warning(f"响应不是有效的JSON: {str(json_err)}, 原始内容: {error_text[:200]}")
+ except (AttributeError, TypeError, ValueError) as parse_err:
+ logger.warning(f"无法解析响应错误内容: {str(parse_err)}")
+
+ await asyncio.sleep(wait_time)
+ else:
+ logger.critical(f"HTTP响应错误达到最大重试次数: 状态码: {e.status}, 错误: {e.message}")
+ # 安全地检查和记录请求详情
+ if image_base64 and payload and isinstance(payload, dict) and "messages" in payload and len(payload["messages"]) > 0:
+ if isinstance(payload["messages"][0], dict) and "content" in payload["messages"][0]:
+ content = payload["messages"][0]["content"]
+ if isinstance(content, list) and len(content) > 1 and "image_url" in content[1]:
+ payload["messages"][0]["content"][1]["image_url"]["url"] = (
+ f"data:image/{image_format.lower() if image_format else 'jpeg'};base64,{image_base64[:10]}...{image_base64[-10:]}"
+ )
+ logger.critical(f"请求头: {await self._build_headers(no_key=True)} 请求体: {payload}")
+ raise RuntimeError(f"API请求失败: 状态码 {e.status}, {e.message}")
except Exception as e:
if retry < policy["max_retries"] - 1:
- wait_time = policy["base_wait"] * (2 ** retry)
+ wait_time = policy["base_wait"] * (2**retry)
logger.error(f"请求失败,等待{wait_time}秒后重试... 错误: {str(e)}")
await asyncio.sleep(wait_time)
else:
logger.critical(f"请求失败: {str(e)}")
+ # 安全地检查和记录请求详情
+ if image_base64 and payload and isinstance(payload, dict) and "messages" in payload and len(payload["messages"]) > 0:
+ if isinstance(payload["messages"][0], dict) and "content" in payload["messages"][0]:
+ content = payload["messages"][0]["content"]
+ if isinstance(content, list) and len(content) > 1 and "image_url" in content[1]:
+ payload["messages"][0]["content"][1]["image_url"]["url"] = (
+ f"data:image/{image_format.lower() if image_format else 'jpeg'};base64,{image_base64[:10]}...{image_base64[-10:]}"
+ )
logger.critical(f"请求头: {await self._build_headers(no_key=True)} 请求体: {payload}")
raise RuntimeError(f"API请求失败: {str(e)}")
@@ -279,16 +390,14 @@ class LLM_request:
async def _transform_parameters(self, params: dict) -> dict:
"""
根据模型名称转换参数:
- - 对于需要转换的OpenAI CoT系列模型(例如 "o3-mini"),删除 'temprature' 参数,
+ - 对于需要转换的OpenAI CoT系列模型(例如 "o3-mini"),删除 'temperature' 参数,
并将 'max_tokens' 重命名为 'max_completion_tokens'
"""
# 复制一份参数,避免直接修改原始数据
new_params = dict(params)
- # 定义需要转换的模型列表
- models_needing_transformation = ["o3-mini", "o1-mini", "o1-preview", "o1-2024-12-17", "o1-preview-2024-09-12",
- "o3-mini-2025-01-31", "o1-mini-2024-09-12"]
- if self.model_name.lower() in models_needing_transformation:
- # 删除 'temprature' 参数(如果存在)
+
+ if self.model_name.lower() in self.MODELS_NEEDING_TRANSFORMATION:
+ # 删除 'temperature' 参数(如果存在)
new_params.pop("temperature", None)
# 如果存在 'max_tokens',则重命名为 'max_completion_tokens'
if "max_tokens" in new_params:
@@ -307,28 +416,31 @@ class LLM_request:
"role": "user",
"content": [
{"type": "text", "text": prompt},
- {"type": "image_url", "image_url": {"url": f"data:image/{image_format.lower()};base64,{image_base64}"}}
- ]
+ {
+ "type": "image_url",
+ "image_url": {"url": f"data:image/{image_format.lower()};base64,{image_base64}"},
+ },
+ ],
}
],
"max_tokens": global_config.max_response_length,
- **params_copy
+ **params_copy,
}
else:
payload = {
"model": self.model_name,
"messages": [{"role": "user", "content": prompt}],
"max_tokens": global_config.max_response_length,
- **params_copy
+ **params_copy,
}
# 如果 payload 中依然存在 max_tokens 且需要转换,在这里进行再次检查
- if self.model_name.lower() in ["o3-mini", "o1-mini", "o1-preview", "o1-2024-12-17", "o1-preview-2024-09-12",
- "o3-mini-2025-01-31", "o1-mini-2024-09-12"] and "max_tokens" in payload:
+ if self.model_name.lower() in self.MODELS_NEEDING_TRANSFORMATION and "max_tokens" in payload:
payload["max_completion_tokens"] = payload.pop("max_tokens")
return payload
- def _default_response_handler(self, result: dict, user_id: str = "system",
- request_type: str = "chat", endpoint: str = "/chat/completions") -> Tuple:
+ def _default_response_handler(
+ self, result: dict, user_id: str = "system", request_type: str = "chat", endpoint: str = "/chat/completions"
+ ) -> Tuple:
"""默认响应解析"""
if "choices" in result and result["choices"]:
message = result["choices"][0]["message"]
@@ -352,17 +464,18 @@ class LLM_request:
total_tokens=total_tokens,
user_id=user_id,
request_type=request_type,
- endpoint=endpoint
+ endpoint=endpoint,
)
return content, reasoning_content
return "没有返回结果", ""
- def _extract_reasoning(self, content: str) -> tuple[str, str]:
+ @staticmethod
+ def _extract_reasoning(content: str) -> Tuple[str, str]:
"""CoT思维链提取"""
- match = re.search(r'(?:)?(.*?)', content, re.DOTALL)
- content = re.sub(r'(?:)?.*?', '', content, flags=re.DOTALL, count=1).strip()
+ match = re.search(r"(?:)?(.*?)", content, re.DOTALL)
+ content = re.sub(r"(?:)?.*?", "", content, flags=re.DOTALL, count=1).strip()
if match:
reasoning = match.group(1).strip()
else:
@@ -372,34 +485,22 @@ class LLM_request:
async def _build_headers(self, no_key: bool = False) -> dict:
"""构建请求头"""
if no_key:
- return {
- "Authorization": "Bearer **********",
- "Content-Type": "application/json"
- }
+ return {"Authorization": "Bearer **********", "Content-Type": "application/json"}
else:
- return {
- "Authorization": f"Bearer {self.api_key}",
- "Content-Type": "application/json"
- }
+ return {"Authorization": f"Bearer {self.api_key}", "Content-Type": "application/json"}
# 防止小朋友们截图自己的key
async def generate_response(self, prompt: str) -> Tuple[str, str]:
"""根据输入的提示生成模型的异步响应"""
- content, reasoning_content = await self._execute_request(
- endpoint="/chat/completions",
- prompt=prompt
- )
+ content, reasoning_content = await self._execute_request(endpoint="/chat/completions", prompt=prompt)
return content, reasoning_content
async def generate_response_for_image(self, prompt: str, image_base64: str, image_format: str) -> Tuple[str, str]:
"""根据输入的提示和图片生成模型的异步响应"""
content, reasoning_content = await self._execute_request(
- endpoint="/chat/completions",
- prompt=prompt,
- image_base64=image_base64,
- image_format=image_format
+ endpoint="/chat/completions", prompt=prompt, image_base64=image_base64, image_format=image_format
)
return content, reasoning_content
@@ -410,22 +511,21 @@ class LLM_request:
"model": self.model_name,
"messages": [{"role": "user", "content": prompt}],
"max_tokens": global_config.max_response_length,
- **self.params
+ **self.params,
+ **kwargs,
}
content, reasoning_content = await self._execute_request(
- endpoint="/chat/completions",
- payload=data,
- prompt=prompt
+ endpoint="/chat/completions", payload=data, prompt=prompt
)
return content, reasoning_content
async def get_embedding(self, text: str) -> Union[list, None]:
"""异步方法:获取文本的embedding向量
-
+
Args:
text: 需要获取embedding的文本
-
+
Returns:
list: embedding向量,如果失败则返回None
"""
@@ -439,19 +539,13 @@ class LLM_request:
embedding = await self._execute_request(
endpoint="/embeddings",
prompt=text,
- payload={
- "model": self.model_name,
- "input": text,
- "encoding_format": "float"
- },
- retry_policy={
- "max_retries": 2,
- "base_wait": 6
- },
- response_handler=embedding_handler
+ payload={"model": self.model_name, "input": text, "encoding_format": "float"},
+ retry_policy={"max_retries": 2, "base_wait": 6},
+ response_handler=embedding_handler,
)
return embedding
+
def compress_base64_image_by_scale(base64_data: str, target_size: int = 0.8 * 1024 * 1024) -> str:
"""压缩base64格式的图片到指定大小
Args:
@@ -463,66 +557,66 @@ def compress_base64_image_by_scale(base64_data: str, target_size: int = 0.8 * 10
try:
# 将base64转换为字节数据
image_data = base64.b64decode(base64_data)
-
+
# 如果已经小于目标大小,直接返回原图
- if len(image_data) <= 2*1024*1024:
+ if len(image_data) <= 2 * 1024 * 1024:
return base64_data
-
+
# 将字节数据转换为图片对象
img = Image.open(io.BytesIO(image_data))
-
+
# 获取原始尺寸
original_width, original_height = img.size
-
+
# 计算缩放比例
scale = min(1.0, (target_size / len(image_data)) ** 0.5)
-
+
# 计算新的尺寸
new_width = int(original_width * scale)
new_height = int(original_height * scale)
-
+
# 创建内存缓冲区
output_buffer = io.BytesIO()
-
+
# 如果是GIF,处理所有帧
if getattr(img, "is_animated", False):
frames = []
for frame_idx in range(img.n_frames):
img.seek(frame_idx)
new_frame = img.copy()
- new_frame = new_frame.resize((new_width//2, new_height//2), Image.Resampling.LANCZOS) # 动图折上折
+ new_frame = new_frame.resize((new_width // 2, new_height // 2), Image.Resampling.LANCZOS) # 动图折上折
frames.append(new_frame)
-
+
# 保存到缓冲区
frames[0].save(
output_buffer,
- format='GIF',
+ format="GIF",
save_all=True,
append_images=frames[1:],
optimize=True,
- duration=img.info.get('duration', 100),
- loop=img.info.get('loop', 0)
+ duration=img.info.get("duration", 100),
+ loop=img.info.get("loop", 0),
)
else:
# 处理静态图片
resized_img = img.resize((new_width, new_height), Image.Resampling.LANCZOS)
-
+
# 保存到缓冲区,保持原始格式
- if img.format == 'PNG' and img.mode in ('RGBA', 'LA'):
- resized_img.save(output_buffer, format='PNG', optimize=True)
+ if img.format == "PNG" and img.mode in ("RGBA", "LA"):
+ resized_img.save(output_buffer, format="PNG", optimize=True)
else:
- resized_img.save(output_buffer, format='JPEG', quality=95, optimize=True)
-
+ resized_img.save(output_buffer, format="JPEG", quality=95, optimize=True)
+
# 获取压缩后的数据并转换为base64
compressed_data = output_buffer.getvalue()
logger.success(f"压缩图片: {original_width}x{original_height} -> {new_width}x{new_height}")
- logger.info(f"压缩前大小: {len(image_data)/1024:.1f}KB, 压缩后大小: {len(compressed_data)/1024:.1f}KB")
-
- return base64.b64encode(compressed_data).decode('utf-8')
-
+ logger.info(f"压缩前大小: {len(image_data) / 1024:.1f}KB, 压缩后大小: {len(compressed_data) / 1024:.1f}KB")
+
+ return base64.b64encode(compressed_data).decode("utf-8")
+
except Exception as e:
logger.error(f"压缩图片失败: {str(e)}")
import traceback
- logger.error(traceback.format_exc())
- return base64_data
+ logger.error(traceback.format_exc())
+ return base64_data
diff --git a/src/plugins/schedule/schedule_generator.py b/src/plugins/schedule/schedule_generator.py
index 2f96f3531..d117a32e6 100644
--- a/src/plugins/schedule/schedule_generator.py
+++ b/src/plugins/schedule/schedule_generator.py
@@ -1,6 +1,6 @@
-import os
import datetime
import json
+import re
from typing import Dict, Union
from loguru import logger
@@ -65,7 +65,9 @@ class ScheduleGenerator:
1. 早上的学习和工作安排
2. 下午的活动和任务
3. 晚上的计划和休息时间
- 请按照时间顺序列出具体时间点和对应的活动,用一个时间点而不是时间段来表示时间,用JSON格式返回日程表,仅返回内容,不要返回注释,不要添加任何markdown或代码块样式,时间采用24小时制,格式为{"时间": "活动","时间": "活动",...}。"""
+ 请按照时间顺序列出具体时间点和对应的活动,用一个时间点而不是时间段来表示时间,用JSON格式返回日程表,
+ 仅返回内容,不要返回注释,不要添加任何markdown或代码块样式,时间采用24小时制,
+ 格式为{"时间": "活动","时间": "活动",...}。"""
)
try:
@@ -89,7 +91,9 @@ class ScheduleGenerator:
def _parse_schedule(self, schedule_text: str) -> Union[bool, Dict[str, str]]:
"""解析日程文本,转换为时间和活动的字典"""
try:
- schedule_dict = json.loads(schedule_text)
+ reg = r"\{(.|\r|\n)+\}"
+ matched = re.search(reg, schedule_text)[0]
+ schedule_dict = json.loads(matched)
return schedule_dict
except json.JSONDecodeError:
logger.exception("解析日程失败: {}".format(schedule_text))
diff --git a/src/plugins/utils/logger_config.py b/src/plugins/utils/logger_config.py
new file mode 100644
index 000000000..cc15d53a4
--- /dev/null
+++ b/src/plugins/utils/logger_config.py
@@ -0,0 +1,71 @@
+import sys
+from loguru import logger
+from enum import Enum
+
+class LogModule(Enum):
+ BASE = "base"
+ MEMORY = "memory"
+ EMOJI = "emoji"
+ CHAT = "chat"
+
+def setup_logger(log_type: LogModule = LogModule.BASE):
+ """配置日志格式
+
+ Args:
+ log_type: 日志类型,可选值:BASE(基础日志)、MEMORY(记忆系统日志)、EMOJI(表情包系统日志)
+ """
+ # 移除默认的处理器
+ logger.remove()
+
+ # 基础日志格式
+ base_format = "{time:HH:mm:ss} | {level: <8} | {name}:{function}:{line} - {message}"
+
+ chat_format = "{time:HH:mm:ss} | {level: <8} | {name}:{function}:{line} - {message}"
+
+ # 记忆系统日志格式
+ memory_format = "{time:HH:mm} | {level: <8} | 海马体 | {message}"
+
+ # 表情包系统日志格式
+ emoji_format = "{time:HH:mm} | {level: <8} | 表情包 | {function}:{line} - {message}"
+ # 根据日志类型选择日志格式和输出
+ if log_type == LogModule.CHAT:
+ logger.add(
+ sys.stderr,
+ format=chat_format,
+ # level="INFO"
+ )
+ elif log_type == LogModule.MEMORY:
+ # 同时输出到控制台和文件
+ logger.add(
+ sys.stderr,
+ format=memory_format,
+ # level="INFO"
+ )
+ logger.add(
+ "logs/memory.log",
+ format=memory_format,
+ level="INFO",
+ rotation="1 day",
+ retention="7 days"
+ )
+ elif log_type == LogModule.EMOJI:
+ logger.add(
+ sys.stderr,
+ format=emoji_format,
+ # level="INFO"
+ )
+ logger.add(
+ "logs/emoji.log",
+ format=emoji_format,
+ level="INFO",
+ rotation="1 day",
+ retention="7 days"
+ )
+ else: # BASE
+ logger.add(
+ sys.stderr,
+ format=base_format,
+ level="INFO"
+ )
+
+ return logger